This article will discuss YOLOR, a novel and state-of-the-art deep learning algorithm for computer vision tasks, namely Object Detection. In particular, you will learn the following:
- What is YOLOR, and how does it compare to other YOLO algorithms
- What’s new in YOLOR? Architecture and concept for multi-task learning.
- Performance and precision of YOLOR
What is YOLOR?
YOLOR is a state-of-the-art machine learning algorithm for object detection, different from YOLOv1-YOLOv5 due to the difference in authorship, architecture, and model infrastructure. YOLOR stands for “You Only Learn One Representation”, not to be confused with YOLO versions 1 through 4, where YOLO stands for “You Only Look Once”.
YOLOR is proposed as a “unified network to encode implicit knowledge and explicit knowledge together”. The findings of the YOLOR research paper with the title “You Only Learn One Representation: Unified Network for Multiple Tasks” states that the results demonstrate benefit from using implicit knowledge.
In the following, I will guide you through the concept and terminology of YOLOR.
Who created the YOLOR algorithm?
YOLOR authors include Chien-Yao Wang, I-Hau, The, and Hong-Yuan Mark Liao. However, the previous versions of YOLO implementations have been created by Joseph Redmon and Ali Farhadi (YOLOv1 to YOLOv3), and Aleksey Bochkovskiy (YOLOv4). The authors of YOLOR represent the Taiwanese Institute of Information Science, Academia Sinica, and Elan Microelectronics Corporation of Taiwan.
YOLOR Object Detection
YOLOR is specifically for object detection, rather than other machine learning use cases such as object identification or analysis. This is because object detection is focused around the general identifiers which make the object fall under a certain category or class. In contrast, other types of machine learning use cases require more exact processes. Object identification requires the machine learning model to be attuned to the range of nuances that would constitute objects from each other.
For example, object analysis is often used for medical purposes, where classic object detection algorithms made for differentiating cars, and people would be ineffective.

How YOLOR works
Humans are able to learn and understand the physical world based on vision, hearing, tactile (explicit knowledge) – but also based on past experience (implicit knowledge). Therefore, humans are able to effectively process entirely new data by making use of abundant experience from prior learning that is gained through normal learning and stored in the brain.
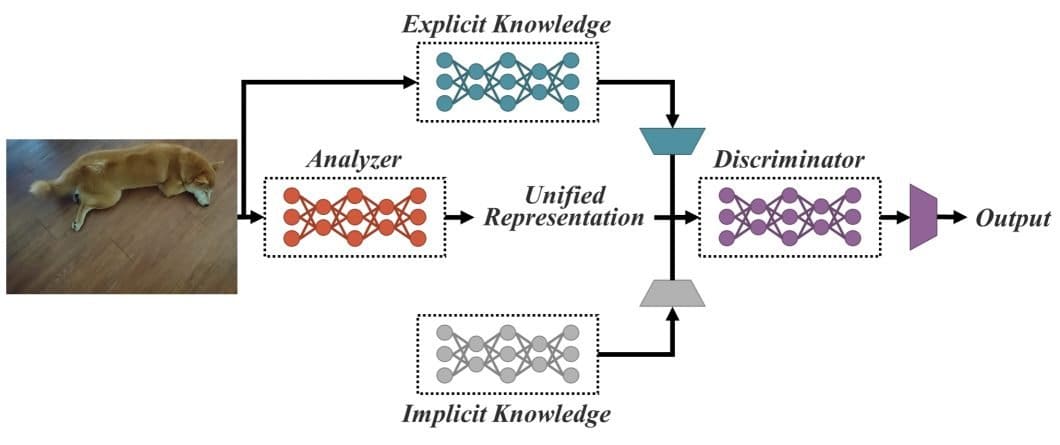
Based on this idea, the YOLOR research paper describes an approach to combine explicit knowledge, defined as learning based on given data and input, with implicit knowledge learned subconsciously. Therefore, the concept of YOLOR is based on encoding implicit and explicit knowledge together, similar to how mammalian brains process implicit and explicit knowledge in conjunction with each other. The unified network proposed in YOLOR generates a unified representation to serve a variety of tasks all at once.
There are three notable processes by which this architecture is made functional: kernel space alignment, prediction refinement, and a convolutional neural network (CNN) with multi-task learning. According to the results, when implicit knowledge is introduced to the neural network that was already trained with explicit knowledge, the network benefits the performance of various tasks.
What’s new in YOLOR
Human beings can answer different questions given a single input. Given one piece of data, humans can analyze the data from different angles. For example, a photo of something may elicit different responses regarding the action depicted, location, etc. YOLOR aims to give this ability to machine learning models – so that they are able to serve many tasks given one input.
Convolutional Neural Networks (CNN) usually fulfill one specific objective, while they could be trained to solve multiple problems at once, which is exactly the goal of YOLOR. CNNs are often created with a single goal in mind. While CNNs learn how to analyze inputs to get outputs, YOLOR tries to have CNNs both (1) learn how to get outputs and also (2) what all the different outputs could be. Rather than just one output, it can have many.
YOLOR performance and precision
The new YOLOR algorithm aims to accomplish tasks using a fraction of predicted additional costs for comparative algorithms. Hence, YOLOR is a unified network that can process implicit and explicit knowledge together and produce a general representation that is refined because of that methodology.
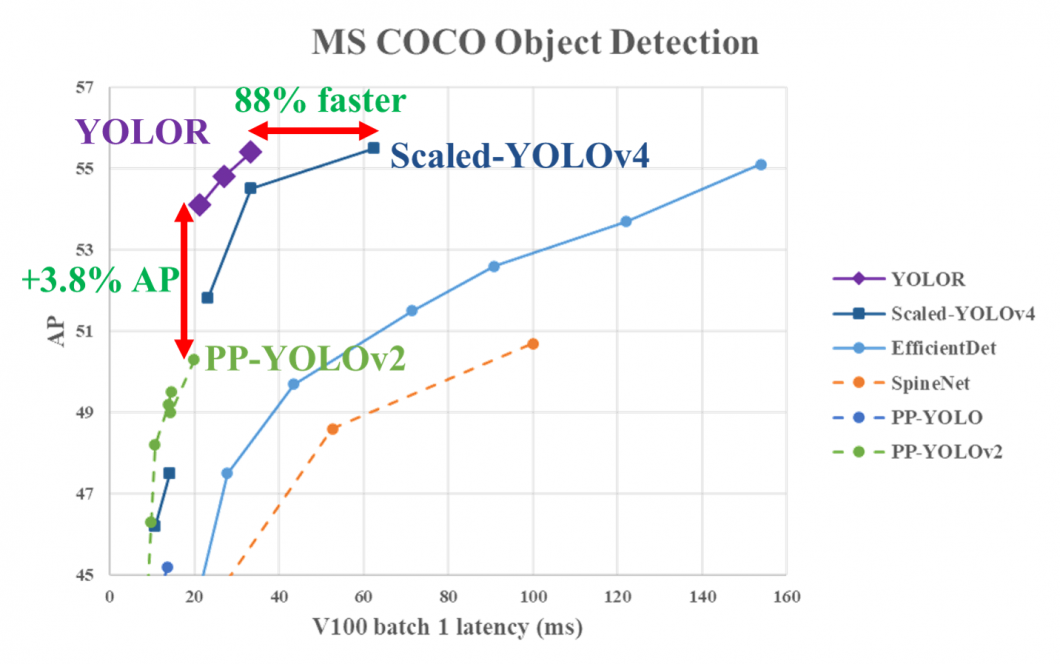
In combination with state-of-the-art methods, the YOLOR achieved comparable object detection accuracy as the Scaled YOLOv4, while the inference speed was increased by 88%. This makes YOLOR one of the fastest object detection algorithms in modern computer vision. On the MS COCO dataset, the mean average precision of YOLOR is 3.8% higher compared to the PP-YOLOv2, at the same inference speed.
What is Explicit Information
Explicit knowledge is given to neural networks by providing clear metadata or image databases that are either thoroughly annotated or well organized. Explicit knowledge can be thought of like flashcards for the machine learning model, with clear definitions and pictures/inputs corresponding to those images.
After the model goes through the deck of flashcards, it is now well-versed in classifying images with their respective definitions, or “classes.” Explicit knowledge for YOLOR is obtained from the shallow layers of the neural networks. This knowledge directly corresponds to observations that are supposed to be made.
Explicit deep learning is carried out using query/key and non-local networks to obtain self-attention or automatic selection of kernels using input data.
What is Implicit Information
Implicit knowledge can effectively assist machine learning models in performing tasks with YOLOR. For humans, implicit knowledge is developed subconsciously. For neural networks, implicit knowledge is obtained by features in the deep layers. The knowledge that does not correspond to observations is known as implicit knowledge as well.
Methods of Obtaining Implicit Learning
Methods belonging to the implicit deep learning category are mainly implicit neural representations and deep equilibrium models. YOLOR uses implicit neural representations to obtain the parameterized continuous mapping representation of discrete inputs.
Deep equilibrium models are used to develop implicit learning into residual-form neural networks. It is then used to perform the equilibrium point calculation for the model. This is useful for other parts of the model, which you can read more about in the YOLOR research paper as it pertains to complex mathematical calculations.
Integration of Implicit and Explicit Learning
To recap, features obtained from shallow layers are known as “explicit knowledge,” while features obtained from deep layers are called implicit knowledge. Vectors, neural networks, and matrix factorization were analyzed as possible methods of modeling implicit and explicit information in the YOLOR paper.
YOLOR is supposed to be a unified network that can integrate implicit and explicit knowledge in order to create a general representation. The general representation then enables sub-representations ideal for a wide array of tasks. Implicit and explicit information was integrated into a unified network by combining compressive sensing and deep learning. There are a few key points in the research paper that describe how the integration process is functional:
- Kernel space alignment, prediction refinement, and multi-task learning were introduced into the implicit knowledge learning process. Tests were run to verify their effectiveness.
- Vector, neural network or matrix factorization were all methods used to model implicit knowledge as well as analyze its effectiveness.
Relevant sources:
- View the YOLOR Source Code and Installation Guide, using pretrained COCO dataset weights
- The YOLO-R research paper: You Only Learn One Representation: Unified Network for Multiple Tasks
What’s Next
Read about related topics, such as the popular real-time object detection algorithm YOLOv3 and the rather controversial YOLO version 5.