
Large Learning Models, or LLMs, are quite a popular term when discussing Artificial Intelligence (AI). With the advent of platforms like ChatGPT, these terms have now become a word of mouth for everyone. Today, they are implemented in search engines and every social media app, such as WhatsApp or Instagram. LLMs changed how we interact with the internet, as finding relevant information or performing specific tasks was never this easy before.
What are Large Language Models (LLMs)?
In generative AI, human language is perceived as a difficult data type. If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a Large Language Model (LLM). They are trained on vast curated training data with sizes ranging from thousands to millions of gigabytes.
An easy way to describe LLM is an AI algorithm capable of understanding and generating human language. Machine learning especially Deep Learning is the backbone of every LLM. It makes LLM capable of interpreting language input based on the patterns and complexity of characters and words in natural language.
LLMs are pre-trained on extensive data on the web which shows results after comprehending complexity, pattern, and relation in the language.
Currently, LLMs can comprehend and generate a wide range of content forms like text, speech, pictures, and videos, to name a few. LLMs apply powerful Natural Language Processing (NLP), machine translation, and Visual Question Answering (VQA).
One of the most common examples of an LLM is a virtual voice assistant such as Siri or Alexa. When you ask, “What is the weather today?”, the assistant will understand your question and find out what the weather is like. It then gives a logical answer. This smooth interaction between machine and human happens because of Large Language Models. Due to these models, the assistant can read user input in natural language and reply accordingly.
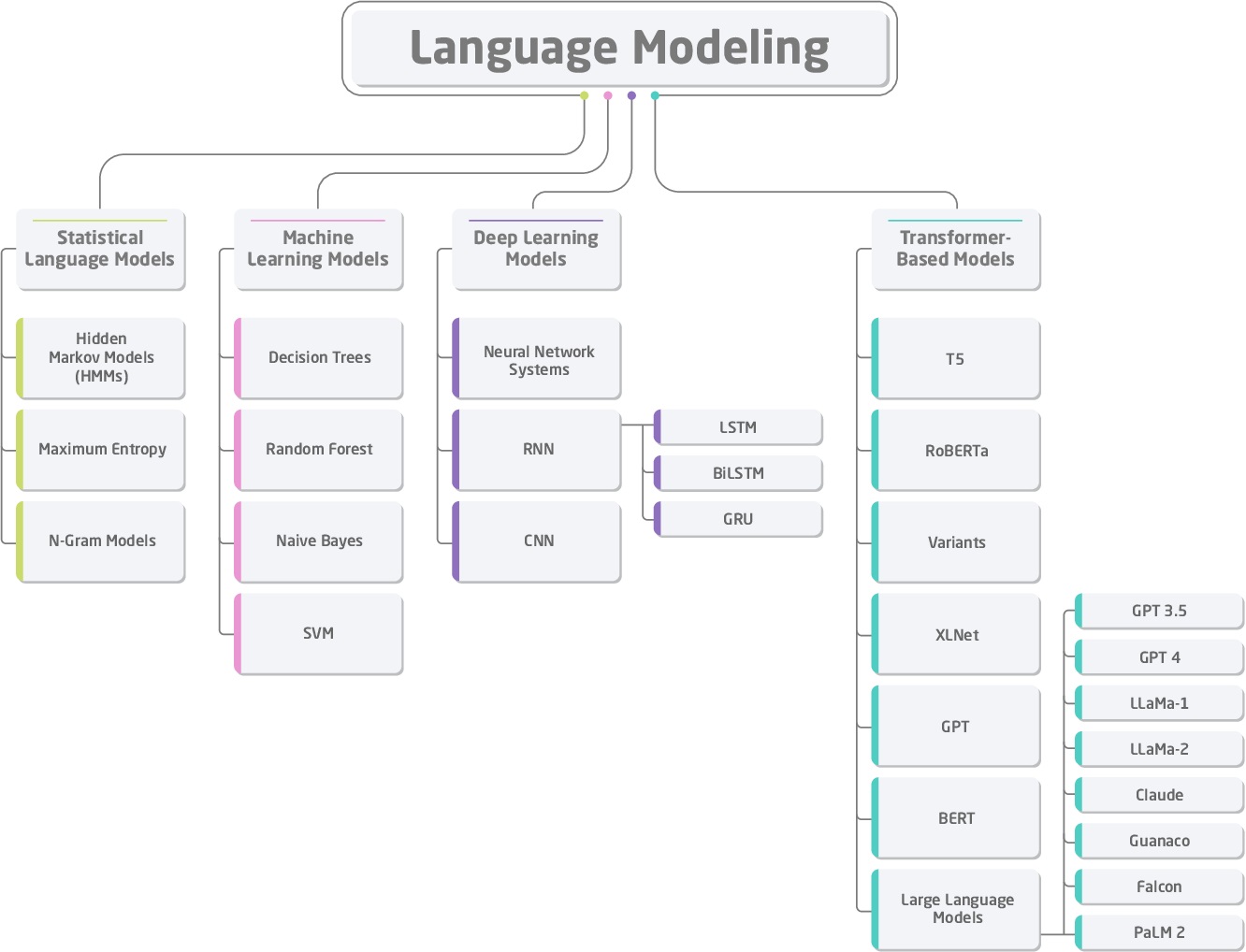
Emergence and History of LLMs
Artificial Neural Networks (ANNs) and Rule-based Models
The foundation of these Computational Linguistics models (CL) dates back to the 1940s when Warren McCulloch and Walter Pitts laid the groundwork for AI. This early research was not about designing a system but exploring the fundamentals of Artificial Neural Networks. However, the first actual language model was a rule-based model developed in the 1950s. These models could understand and produce natural language using predefined rules, but couldn’t comprehend complex language or maintain context.
Statistics-based Models
After the prominence of statistical models, the language models developed in the 90s could predict and analyze language patterns. Using probabilities, they are applicable in speech recognition and machine translation.
Introduction of Word Embeddings
The introduction of word embeddings initiated great progress in LLM and NLP. These models, created in the mid-2000s, could capture semantic relationships accurately by representing words in a continuous vector space.
Recurrent Neural Network Language Models (RNNLM)
A decade later, Recurrent Neural Network Language Models (RNNLM) were introduced to cope with sequential data. These RNN language models were the first to keep context across different parts of the text for a better understanding of language and output generation.
Google Neural Machine Translation (GNMT)
In 2015, Google developed the revolutionary Google Neural Machine Translation (GNMT) for machine translation. The GNMT featured a deep neural network dedicated to sentence-level translations rather than individual word-base translations with a better approach to unsupervised learning.
It works on the shared encoder-decoder-based architecture with long short-term memory (LSTM) networks to capture context and the generation of actual translations. Huge datasets were used to train these models. Before this model, covering some complex patterns in the language and adapting to possible language structures was not possible.
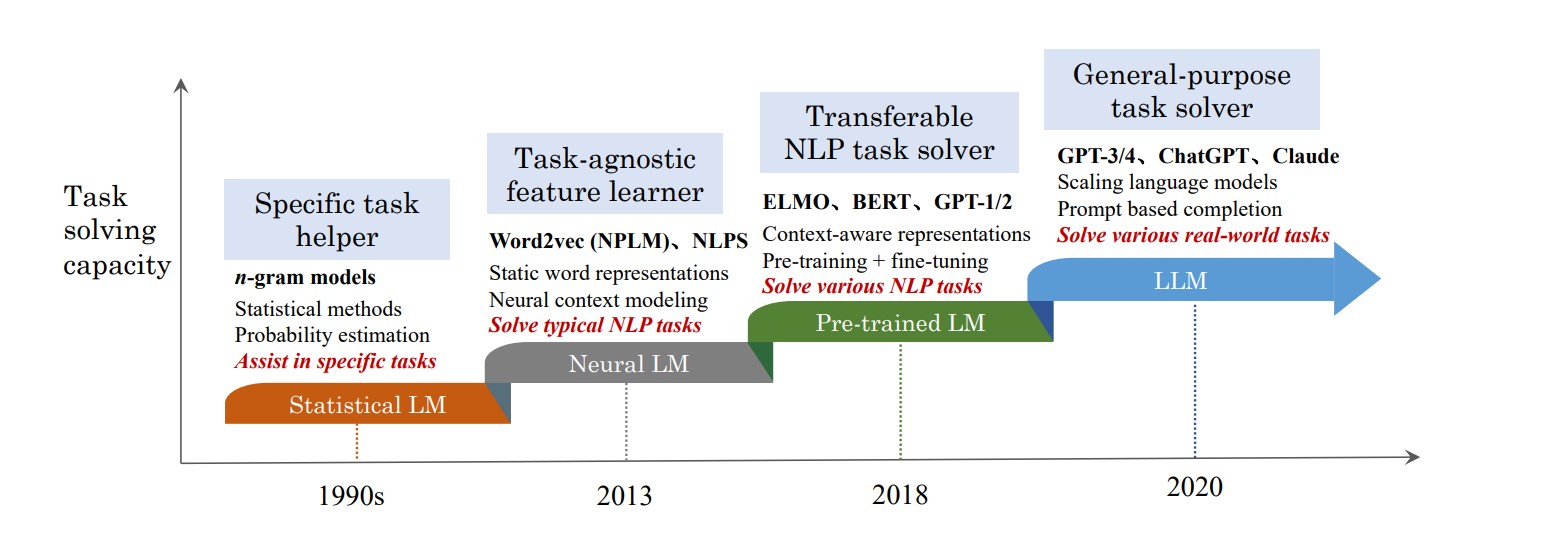
Recent Development
In recent years, deep learning architecture transformer-based language models like BERT (Bidirectional Encoder Representations from Transformers) and GPT-1 (Generative Pre-trained Transformer) were launched by Google and OpenAI, respectively. Such models use a bidirectional approach to understand the context from both directions in a sentence and also generate coherent text by predicting the next word in a sequence to improve tasks like question answering and sentiment analysis.
With the recent release of ChatGPT 4 and 4o, these models are getting more sophisticated by adding billions of parameters and setting new standards in NLP tasks.
Role of Large Language Models in Modern NLP
Large Language Models are considered subsets of Natural Language Processing and their progress also becomes important in Natural Language Processing (NLP). The models, such as BERT and GPT-3 (improved version of GPT-1 and GPT-2), made NLP tasks better and polished.
This language generation model requires large amounts of datasets to train and they use architectures like transformers to maintain long-range dependencies in text. For example, BERT can understand the context of a word like “bank” to differentiate whether it refers to a financial institution or the side of a river.
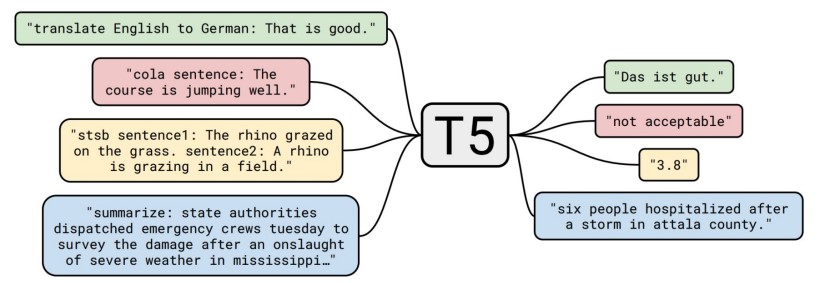
OpenAI’s GPT-3, with its 175 billion parameters, is another prominent example. Generating coherent and contextually relevant text is only made possible by OpenAI’s GPT-3 version. An example of GPT-3’s capability is its ability to complete sentences and paragraphs fluently, given a prompt.
LLM shows outstanding performance in tasks involving data-to-text like suggesting based on your preferences, translating to any language, or even creative writing. Large datasets should be used to train these models and then fine-tuning is required based on the specific application.
LLMs give rise to challenges as well while making great progress. Problems like biases in the training set and the rising costs in computation need a multitude of resources during intensive training and deployment.
Understanding The Working of LLMs – Transformer Architecture
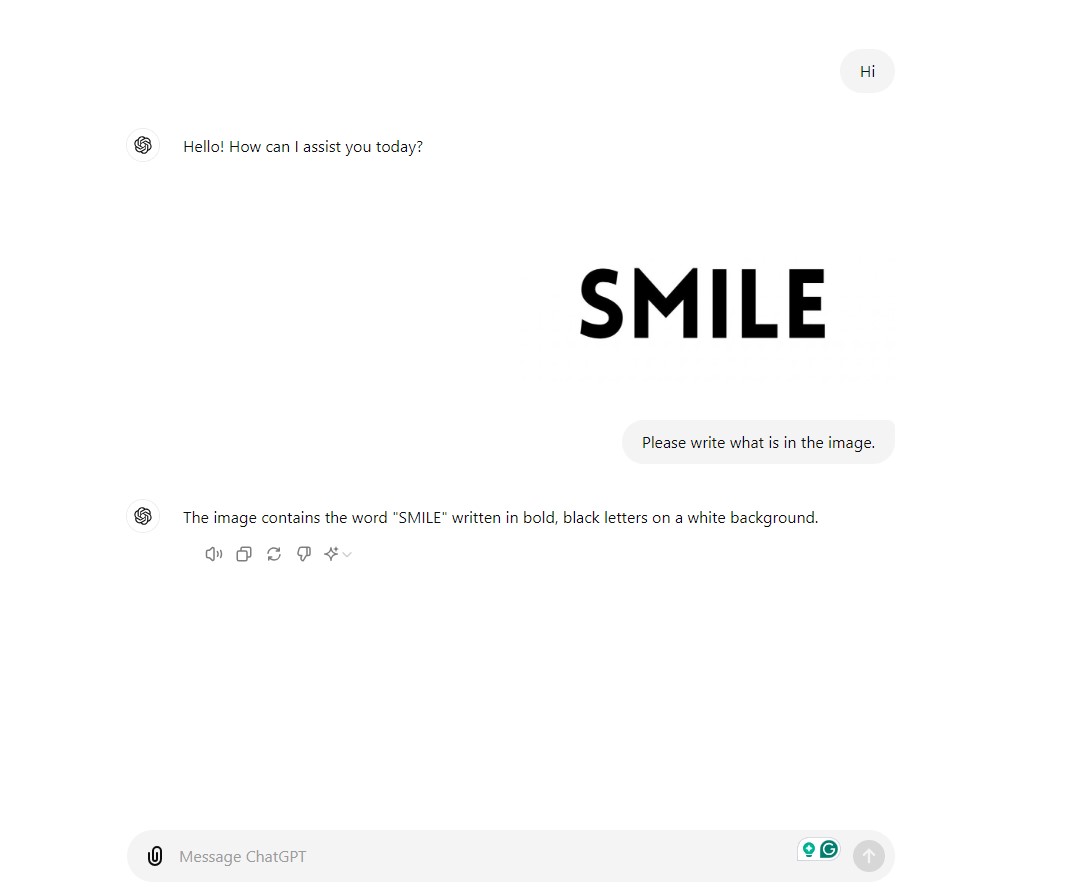
The deep learning architecture, Transformers, serves as the cornerstone of modern LLMs and NLP. Not because it is comparatively efficient, but due to the ability to handle sequential data and capture long-range dependencies that are long-needed in Large Language Models. Introduced by Vaswani et al. in the seminal paper “Attention Is All You Need”, the Transformer model revolutionized how language models process and generate text.
Transformer Architecture
A transformer architecture mainly consists of an encoder and a decoder. Both contain self-attention mechanisms and feed-forward neural networks. Rather than processing the data frame by frame, transformers can process input data in parallel and maintain long-range dependencies.
- Tokenization: Every text-based input is first tokenized into smaller units called tokens. Tokenization converts each word into numbers representing a position in a predefined dictionary.
- Embedding Layer: Tokens are passed through an embedding layer, which then maps them to high-dimensional vectors to capture their semantic meaning.
- Positional Encoding: This step adds positional encoding to the embedding layer to help the model retain the order of tokens since transformers process sequences in parallel.
- Self-Attention Mechanism: For every token, the self-attention mechanism generates and calculates three vectors: query, key, and value. The dot product of queries with keys determines the token relevance. The normalization of the results is done using SoftMax and then applied to the value vectors to get context-aware word representation.
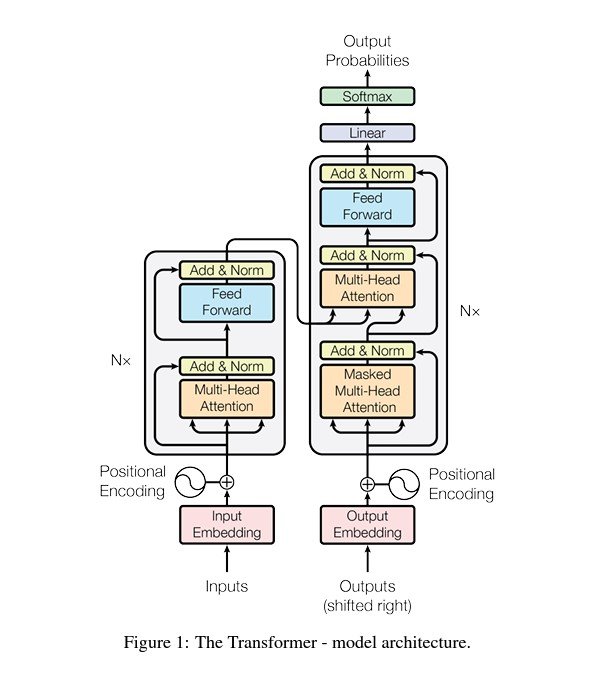
- Multi-Head Attention: Each head focuses on different input sequences. The output is concatenated and linearly transformed, resulting in a better understanding of complex language structures.

Multi-head Attention – Source - Feed-Forward Neural Networks (FFNNs): FFNNs process each token independently. It consists of two linear transformations with a ReLU activation that adds non-linearity.
- Encoder: The encoder processes the input sequence and produces a context-rich representation. It involves multiple layers of multi-head attention and FFNNs.
- Decoder: A decoder generates the output sequence. It processes the encoder’s output using an additional cross-attention mechanism, connecting sequences.
- Output Generation: The output is generated as a vector of logic for each token. The SoftMax layer is applied to the output to convert it into probability scores. The token with the highest score is the next word in sequence.
Example
For a simple translation task by the Large Language Model, the encoder processes the input sentence in the source language to construct a context-rich representation, and the decoder generates a translated sentence in the target language according to the output generated by the encoder and the previous tokens generated.
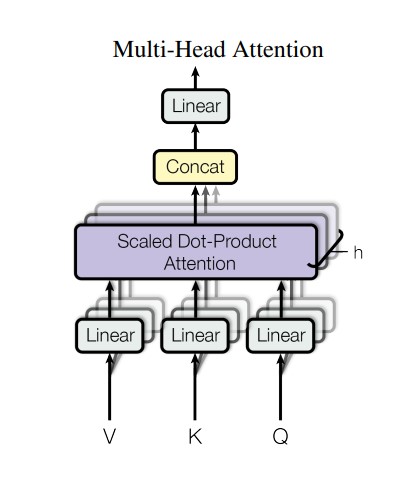
Customization and Fine-Tuning of LLMs For A Specific Task
It is possible to process entire sentences simultaneously using the transformer’s self-attention mechanism. This is the foundation behind a transformer architecture. However, to further improve its efficiency and make it applicable to a certain application, a normal transformer model needs fine-tuning.
Steps For Fine-Tuning
- Data Collection: Collect the data only relevant to your specific task to ensure the model achieves high accuracy.
- Data preprocessing: Based on your dataset and its nature, normalize and tokenize text, remove stop words, and perform morphological analysis to prepare data for training.
- Selecting Model: Choose an appropriate pre-trained model (e.g., GPT-4, BERT) based on your specific task requirements.
- Hyperparameter Tuning: For model performance, adjust the learning rate, batch size, number of epochs, and dropout rate.
- Fine-Tuning: Apply techniques like LoRA or PEFT to fine-tune the model on domain-specific data.
- Evaluation and Deployment: Use metrics such as accuracy, precision, recall, and F1 score to evaluate the model and implement the fine-tuned model on your task.
Large Language Models’ Use-Cases and Applications
Healthcare and Medicine
Large Language Models combined with Computer Vision have become a great tool for radiologists. They are using LLMs for radiologic decision purposes through the analysis of images so they can have second opinions. General physicians and consultants also use LLMs like ChatGPT to get answers to genetics-related questions from verified sources.
LLMs also automate the doctor-patient interaction, reducing the risk of infection or relief for those unable to move. It was an amazing breakthrough in the medical sector especially during pandemics like COVID-19. Tools like XrayGPT automate the analysis of X-ray images.
Education
Large Language Models made learning material more interactive and easily accessible. With search engines based on AI models, teachers can provide students with more personalized courses and learning resources. Moreover, AI tools can offer one-on-one engagement and customized learning plans, such as Khanmigo, a Virtual Tutor by Khan Academy, which uses student performance data to make targeted recommendations.
Multiple studies show that ChatGPT’s performance on the United States Medical Licensing Exam (USMLE) was met or above the passing score.
Finance
Risk assessment, automated trading, business report analysis, and support reporting can be done using LLMs. Models like BloombergGPT achieve outstanding results for news classification, entity recognition, and question-answering tasks.
LLMs integrated with Customer Relationship Management Systems (CRMs) have become a must-have tool for most businesses as they automate most of their business operations.
Other Applications
- Developers are using LLMs to write and debug their code.
- Content creation becomes super easy with LLMs. They can generate blogs or YouTube scripts in no time.
- LLMs can take input of agricultural land and location and provide details on whether it is good for agriculture or not.
- Tools like PDFGPT help automate literature reviews and extract relevant data or summarize text from the selected research papers.
- Tools like Vision Transformers (ViT) apply LLM principles to image recognition ,which helps in medical imaging.
What’s Next for LLMs?
Before LLMs, it wasn’t easy to understand and convey machine language. However, Large Language Models are a part of our everyday life, making it too good to be true that we can talk to computers. We can get more personalized responses and understand them because of their text-generation ability.
LLMs fill the long-awaited gap between machine and human communication. For the future, these models need more task-specific modeling and improved and accurate results. Getting more accurate and sophisticated with time, imagine what we can achieve with the convergence of LLMs, Computer Vision, and Robotics.
Read more related topics and blogs about LLMs and Deep Learning:
- What is Natural Language Processing?
- Generative AI: A Guide To Generative Models
- Large Action Models: Beyond Language, Into Action