
With the advancement of Deep Learning (DL), the invention of Visual Question Answering (VQA) has become possible. VQA has recently become popular among the computer vision research community as researchers are heading towards multi-modal problems. VQA is a challenging yet promising multidisciplinary Artificial Intelligence (AI) task that enables several applications.
In this blog we’ll cover:
- Overview of Visual Question Answering
- The fundamental principles of VQA
- Working on a VQA system
- VQA datasets
- Applications of VQA across various industries
- Recent developments and future challenges
What is Visual Question Answering (VQA)?
The simplest way of defining a VQA system is a system capable of answering questions related to an image. It takes an image and a text-based question as inputs and generates the answer as output. The nature of the problem defines the nature of the input and output of a VQA model.
Inputs may include static images, videos with audio, or even infographics. Questions can be presented within the visual or asked separately regarding the visual input. It can answer multiple-choice questions, YES/NO (binary questions), or any open-ended questions about the provided input image. It allows a computer program to understand and respond to visual and textual input in a human-like manner.

- Are there any phones near the table?
- Guess the number of burgers on the table.
- Guess the color of the table?
- Read the text in the image if any.
A visual question-answering model would be able to answer the above questions about the image.
Due to its complex nature and being a multimodal task (systems that can interpret and comprehend data from various modalities, including text, pictures, and sometimes audio), VQA is considered AI-complete or AI-hard (the most difficult problem in the AI field) as it is equivalent to making computers as intelligent as humans.
Principles Behind VQA
Visual question answering naturally works with image and text modalities.
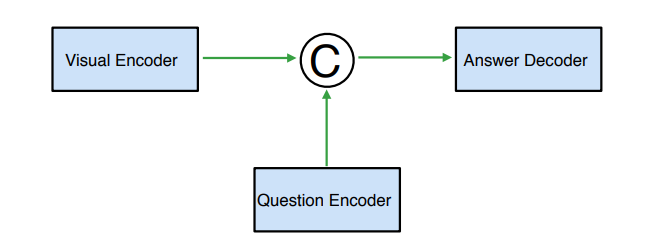
A VQA model has the following elements:
- Computer Vision (CV)
CV is used for image processing and extraction of the relevant features. For image classification and object recognition in an image, CNN (Convolution Neural Networks) are applied. OpenCV and Viso Suite are suitable platforms for this approach. Such methods operate by capturing the local and global visual features from an image. - Natural Language Processing (NLP)
NLP works parallel with CV in any VQA model. NLP processes the data with natural language text or voice. Long Short-Term Memory (LSTM) networks or Bag-Of-Words (BOW) are mostly used to extract question features. These methods understand the sequential nature of the question’s language and convert it to numerical data numerical data for NLP. - Combining CV And NLP
This is the conjugation part in a VQA model. The nature of the final answer is derived from this integration of visual and textual features. Different architectures, such as CNNs and Recurrent Neural Networks (RNNs) combined, Attention Mechanisms, or even Multilayer Perceptrons (MLPs) are used in this approach.
How Does a VQA System Work?
A Visual Question Answering model can handle multiple image inputs. It can take visual input as images, videos, GIFs, sets of images, diagrams, slides, and 360◦ images. From a broader perspective, a visual question-answer system undergoes the following phases:
- Image Feature Extraction: Transformation of images into readable feature representation to process further.
- Question Feature Extraction: Encoding of the natural language questions to extract relevant entities and concepts.
- Feature Conjugation: Methods of combining encoded image and question features.
- Answer Generation: Understanding the integrated features to generate the final answer.
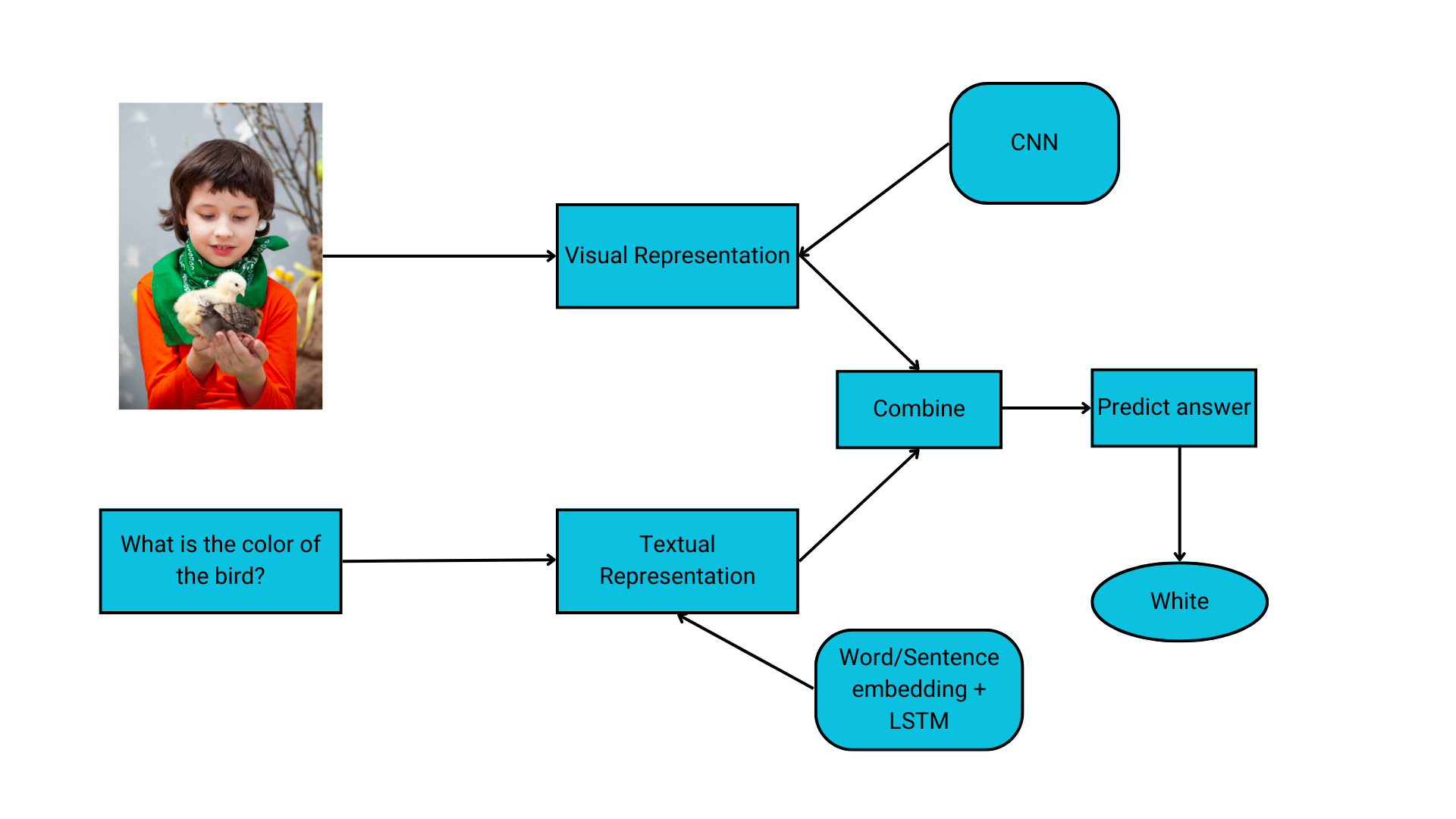
Image Feature Extraction
The majority of VQA models use CNN to process visual imagery. Deep convolutional neural networks receive images as input and use them to train a classifier. CNN’s basic purpose for VQA is image featurization. It uses a linear mathematical operation of “convolution” and not simple matrix multiplication.
Depending on the complexity of the input visual, the number of layers may range from hundreds to thousands. Each layer builds on the outputs of the ones before it to identify complex patterns.
Several Visual Question Answering papers revealed that most of the models used VGGet before ResNets (8x deeper than VGG nets) came in 2017 for image feature extraction.
Question Feature Extraction
The literature on VQA suggests that Long Short-Term Memory (LSTMs) are commonly used for question featurization, a type of Recurrent Neural Network (RNN). As the name suggests, RNNs have a looping or recurrent workflow; they work by passing sequential data that they receive to the hidden layers one step at a time.
The short-term memory component in this neural network uses a hidden layer to remember and use past inputs for future predictions. The next sequence is then predicted based on the current input and stored memory.
RNNs have problems with exploding and vanishing gradients while training a deep neural network. LSTMs overcome this. Several other methods, such as count-based and frequency-based methods like count vectorization and TF-IDF (Term Frequency-Inverse Document Frequency) are also available.
For natural language processing, prediction-based methods such as a continuous bag of words and skip grams are used as well. Word2Vec pre-trained algorithms are also applicable.
A skip-gram model predicts the words around a given word by maximizing the likelihood of correctly guessing context words based on a target word. So, for a sequence of words w1, w2, …, wT, the objective of the model is to accurately predict nearby words.
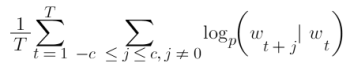
It achieves this by calculating the probability of each word being in the context, with a given target word. Using the softmax function, the following calculation compares vector representations of words.
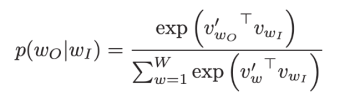
Feature Conjugation
The primary difference between various methodologies for VQA lies in combining the image and text features. Some approaches include simple concatenation and linear classification. A Bayesian approach based on probabilistic modeling is preferable for handling different feature vectors.
If the vectors coming from the image and text are of the same length, element-wise multiplication is also applicable to join the features. You can also try the Attention-based approach to guide the algorithm’s focus towards the most important details in the input. The DualNet VQA model uses a hybrid approach that concatenates element-wise addition and multiplication results to achieve greater accuracy.
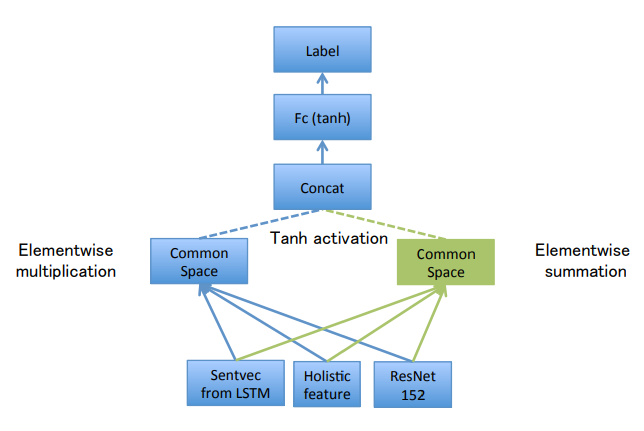
Answer Generation
This phase in a VQA model involves taking the encoded image and question features as inputs and generating the final answer. An answer could be in binary form, counting numbers, checking the right answer, natural language answers, or open-ended answers in words, phrases, or sentences.
The multiple-choice and binary answers use a classification layer to convert the model’s output into a probability score. LSTMs are appropriate to use when dealing with open-ended questions.
VQA Datasets
Several datasets are present for VQA research. Visual Genome is currently the largest available dataset for visual question-answering models.
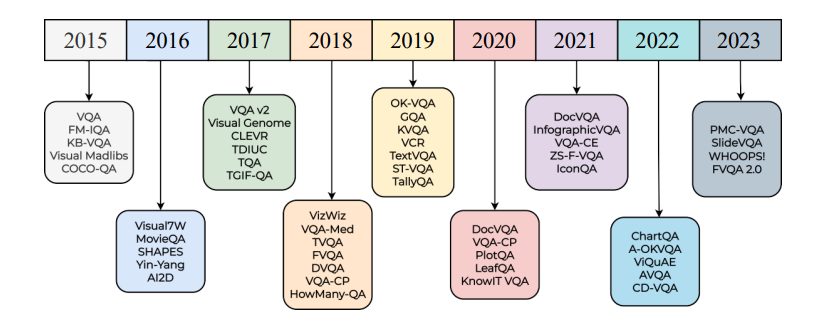
Depending on the question-answer pairs, here are some of the common datasets for VQA.
- COCO-QA Dataset: Extension of COCO (Common Objects in Context). Questions of 4 types: number, color, object, and location. Correct answers are all given in one word.
- CLEVR: Contains a training set of 70,000 images and 699,989 questions. A validation set of 15,000 images and 149,991 questions. A test set of 15,000 images and 14,988 questions. Answers for all training and VAL questions.
- DAQUAR: Contains real-world images. Humans question-answer pairs about images.
- Visual7W: A large-scale visual question-answering dataset with object-level ground truth and multimodal answers. Each question starts with one of the seven Ws.

Applications of the Visual Question Answering System
Individually, CV and NLP have separate sets of various applications. Implementation of both in the same system can further enhance the application domain for Visual Question Answering.
Real-world applications of VQA are:
Medical – VQA
This subdomain focuses on the questions and answers related to the medical field. VQA models may act as pathologists, radiologists, or accurate medical assistants. VQA in the medical sector can greatly reduce the workload of workers by automating several tasks. For example, it can decrease the chances of disease misdiagnosis.
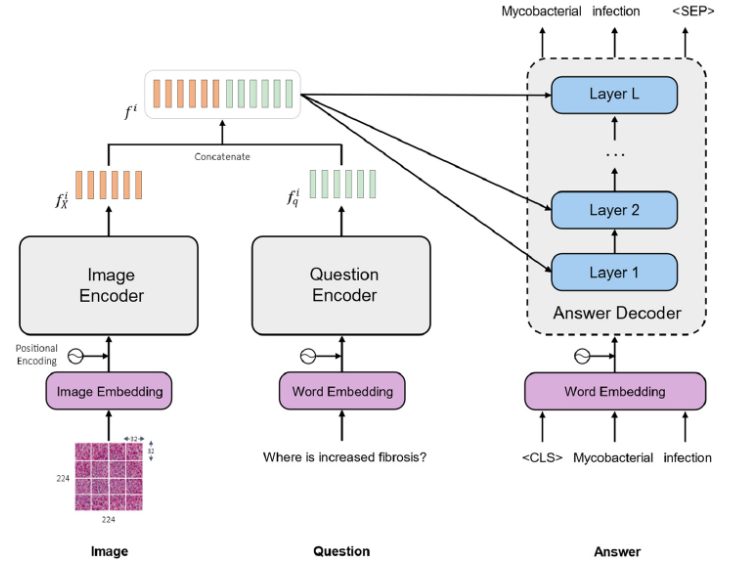
VQA can be implemented as a medical advisor based on images provided by the patients. It can be used to check medical records and data accuracy from the database.
Education
The application of VQA in the education sector can support visual learning to a great extent. Imagine having a learning assistant who can guide and evaluate you with learned concepts. Some of the proposed use cases are Visual Chatbots for Education, Gamification of VQA Systems, and Automated Museum Guides. VQA in education has the potential to make learning styles more interactive and creative.
Assistive Technology
The prime motive behind VQA is to aid visually impaired individuals. Initiatives like the VizWiz mobile app and Be My Eyes utilize VQA systems to provide automated assistance to visually impaired individuals by answering questions about real-world images. Assistive VQA models can see the surroundings and help people understand what’s happening around them.
Visually impaired people can engage more meaningfully with their environment with the help of such VQA systems. Envision Glasses is an example of such a model.

E-commerce
VQA is capable of enhancing the online shopping user experience. Stores and platforms for online shopping can integrate VQA to create a streamlined e-commerce environment. For example, you can ask questions about products (Product Question Answering) or even upload images, and it’ll provide you with all the necessary info like product details, availability, and even recommendations based on what it sees in the images.
Online shopping stores and websites can implement VQA instead of manual customer service to further improve the user experience on their platforms. It can help customers with:
- Product recommendations
- Troubleshooting for users
- Website and shopping tutorials
- VQA system can also act as a Chatbot that can speak visual dialogues
Content Filtering
One of the most suitable applications of VQA is content moderation. Based on its fundamental feature, it can detect harmful or inappropriate content and filter it out to keep a safe online environment. Any offensive or inappropriate content on social media platforms can be detected using VQA.
Recent Development & Challenges In Improving VQA
With the constant advancement of CV and DL, VQA models are making huge progress. The number of annotated datasets is rapidly increasing thanks to crowd-sourcing, and the models are becoming intelligent enough to provide an accurate answer using natural language. In the past few years, many VQA algorithms have been proposed. Almost every method involves:
- Image featurization
- Question featurization
- A suitable algorithm that combines these features to generate the answer
However, a significant gap exists between accurate VQA systems and human intelligence. Currently, it is hard to develop any adaptable model due to the diversity of datasets. It is difficult to determine which method is superior as of yet.
Unfortunately, because most large datasets don’t offer specific information about the types of questions asked, it’s hard to measure how well systems handle certain types of questions.
The present models cannot improve overall performance scores when handling unique questions. This makes it hard for the assessment of methods used for VQA. Currently, multiple choice questions are used to evaluate VQA algorithms because analysis of open-ended multi-word questions is challenging. Moreover, VQA regarding videos still has a long way to go.
Existing algorithms are not sufficient to mark VQA as a solved problem. Without larger datasets and more practical work, it is hard to make better-performing VQA models.
What’s Next for Visual Question Answering?
VQA is a state-of-the-art AI model that is much more than task-specific algorithms. Being an image-understanding model, VQA is going to be a major development in AI. It is bridging the gap between visual content and natural language.
Text-based queries are common, but imagine interacting with the computer and asking questions about images or scenes. We are going to see more intuitive and natural interactions with computers.
Some future recommendations to improve VQA are:
- Datasets need to be larger
- Datasets need to be less biased
- Future datasets need more nuanced analysis for benchmarking
More effort is required to create VQA algorithms that can think deeply about what’s in the images.
Related topics and blog articles about computer vision and NLP: