Vision Transformers (ViT) have recently emerged as a competitive alternative to Convolutional Neural Networks (CNNs) that are currently state-of-the-art (SOTA) in different image recognition and computer vision tasks. ViT models outperform the current SOTA CNNs by almost x4 in terms of computational efficiency and accuracy.
Transformer models have become the de facto status quo in Natural Language Processing (NLP). For example, the popular ChatGPT AI chatbot is a transformer-based language model. Specifically, it is based on the GPT (Generative Pre-trained Transformer) architecture. This uses self-attention mechanisms to model the dependencies between words in a text.
Vision Transformer (ViT) in Image Recognition
While the Transformer architecture has become the highest standard for tasks involving Natural Language Processing (NLP), its use cases relating to Computer Vision (CV) remain limited. In many computer vision tasks, we use attention either in conjunction with convolutional neural networks (CNN) or to substitute certain aspects of CNNs while maintaining their entire composition. Popular image recognition models include ResNet, VGG, YOLOv3, YOLOv7 or YOLOv8, and Segment Anything (SAM).
However, this dependency on CNN is not mandatory, and a pure transformer applied directly to sequences of image patches can work exceptionally well on image classification tasks.
Vision Transformers Performance
Vision Transformers (ViT) have recently achieved highly competitive performance in benchmarks for several computer vision applications, such as image classification, object detection, and semantic image segmentation.
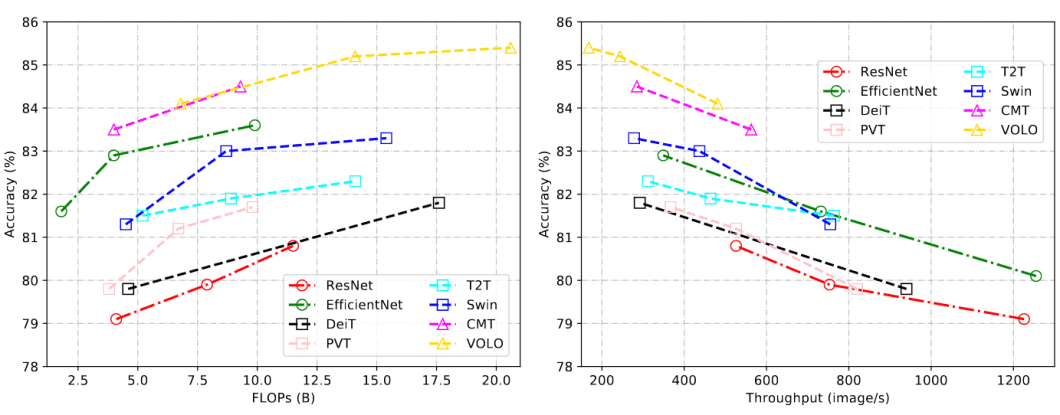
CSWin Transformer is an efficient and effective Transformer-based backbone for general-purpose vision tasks. It uses a new technique called “Cross-Shaped Window self-attention” to analyze different parts of the image simultaneously, making it much faster.
The CSWin Transformer has surpassed previous SOTA methods like the Swin Transformer. In benchmark tasks, CSWIN achieved excellent performance, including 85.4% Top-1 accuracy on ImageNet-1K, 53.9 box AP and 46.4 masks AP on the COCO detection task, and 52.2 mIOU on the ADE20K semantic segmentation task.

Technical Details
The Vision Transformer (ViT) model architecture was introduced in a research paper published as a conference paper at ICLR 2021 titled “An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale”. It was developed and published by Neil Houlsby, Alexey Dosovitskiy, and 10 more authors of the Google Research Brain Team.
The fine-tuning code and pre-trained ViT models are available on the GitHub of the Google Research team. You find them here. The ViT models were pre-trained on the ImageNet and ImageNet-21k datasets.
Origin and History of Vision Transformer Models
In the following, we highlight some of the most significant vision transformer developments over the years. These developments are based on the transformer architecture, originally proposed for natural language processing (NLP) in 2017.
| Date | Model | Description | Vision Transformer? |
|---|---|---|---|
| 2017 Jun | Transformer | A model based solely on an attention mechanism. It demonstrated excellent performance on NLP tasks. | ❌ |
| 2018 Oct | BERT | Pre-trained transformer models started dominating the NLP field. | ❌ |
| 2020 May | DETR | DETR is a simple yet effective framework for high-level vision that views object detection as a direct set prediction problem. | ✅ |
| 2020 May | GPT-3 | The GPT-3 is a huge transformer model with 170B parameters that takes a significant step towards a general NLP model. | ❌ |
| 2020 Jul | iGPT | The transformer model, originally developed for NLP, can also be used for image pre-training. | ✅ |
| 2020 Oct | ViT | Pure transformer architectures that are effective for visual recognition. | ✅ |
| 2020 Dec | IPT/SETR/CLIP | Transformers have been applied to low-level vision, segmentation, and multimodality tasks, respectively. | ✅ |
| 2021 – today | ViT Variants | Several ViT variants include DeiT, PVT, TNT, Swin, and CSWin (2022). | ✅ |
Are Transformers a Deep Learning Method?
A transformer in machine learning is a deep learning model that uses the mechanisms of attention, differentially weighing the significance of each part of the input sequence of data. Transformers in machine learning are composed of multiple self-attention layers. They are primarily used in the AI subfields of natural language processing (NLP) and computer vision (CV).
Transformers in machine learning hold strong promises toward a generic learning method that can be applied to various data modalities, including the recent breakthroughs in computer vision achieving SOTA standard accuracy with better parameter efficiency.
Vision Transformer and Image Classification
Image classification is a fundamental task in computer vision that involves assigning a label to an image based on its content. Over the years, deep CNNs like YOLOv7 have been the SOTA method for image classification.
However, recent advancements in transformer architecture, which was originally introduced for natural language processing (NLP), have shown great promise in competitive results in image classification tasks.
An example is CrossViT, a cross-attention Vision Transformer for Image Classification. Computer vision research indicates that when pre-trained with a sufficient amount of data, ViT models are at least as robust as ResNet models.
Other papers showed that Vision Transformer Models have great potential for privacy-preserving image classification and outperform SOTA methods in terms of robustness against attacks and classification accuracy.
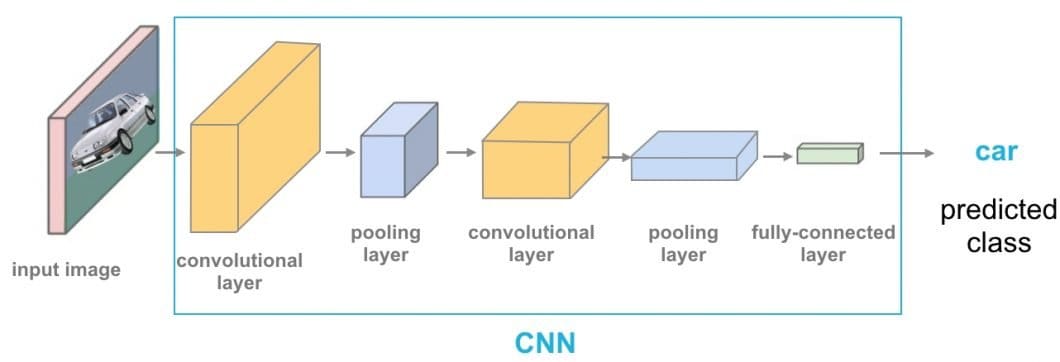
Difference Between CNN and ViT (ViT vs. CNN)
Vision Transformer (ViT) achieves remarkable results compared to CNNs while obtaining substantially fewer computational resources for pre-training. In comparison to CNNs, Vision Transformer (ViT) shows a generally weaker inductive bias resulting in increased reliance on model regularization or data augmentation (AugReg) when training on smaller datasets.
The ViT is a visual model based on the architecture of a transformer originally designed for text-based tasks. The ViT model represents an input image as a series of image patches, like the series of word embeddings used when using transformers to text, and directly predicts class labels for the image. ViT exhibits an extraordinary performance when trained on enough data, breaking the performance of a similar SOTA CNN with 4x fewer computational resources.
These transformers have high success rates when it comes to NLP models and are now also applied to images for image recognition tasks. CNN uses pixel arrays, whereas ViT splits the input images into visual tokens. The visual transformer divides an image into fixed-size patches, correctly embeds each of them, and includes positional embedding as an input to the transformer encoder. Moreover, ViT models outperform CNNs by almost four times when it comes to computational efficiency and accuracy.
The self-attention layer in ViT makes it possible to embed information globally across the overall image. The model also learns from training data to encode the relative location of the image patches to reconstruct the structure of the image.
Transformer Encoder
- Multi-Head Self-Attention Layer (MSP): This layer concatenates all the attention outputs linearly to the right dimensions. The many attention heads help train local and global dependencies in an image.
- Multi-Layer Perceptrons (MLP) Layer: This layer contains a two-layer network with Gaussian Error Linear Unit (GELU).
- Layer Norm (LN): This is added before each block as it does not include any new dependencies between the training images. This thereby helps improve the training time and overall performance.
Moreover, residual connections are included after each block as they allow the components to flow through the network directly without passing through non-linear activations.
In the case of image classification, the MLP layer implements the classification head. It does it with one hidden layer at pre-training time and a single linear layer for fine-tuning.
What is the Self-attention of Vision Transformers?
The self-attention mechanism is a key component of the transformer architecture for capturing long-range dependencies and contextual information in the input data. The self-attention mechanism allows a ViT model to attend to different regions of the input data, based on their relevance to the task at hand.
Therefore, the self-attention mechanism computes a weighted sum of the input data, where the weights are computed based on the similarity between the input features. This allows the model to give more importance to the relevant input features, which helps it capture more informative representations of the input data.
Hence, self-attention is a computational primitive used to quantify pairwise entity interactions that help a network learn the hierarchy and alignment present inside input data. Attention has proven to be a key element for vision networks to achieve higher robustness.
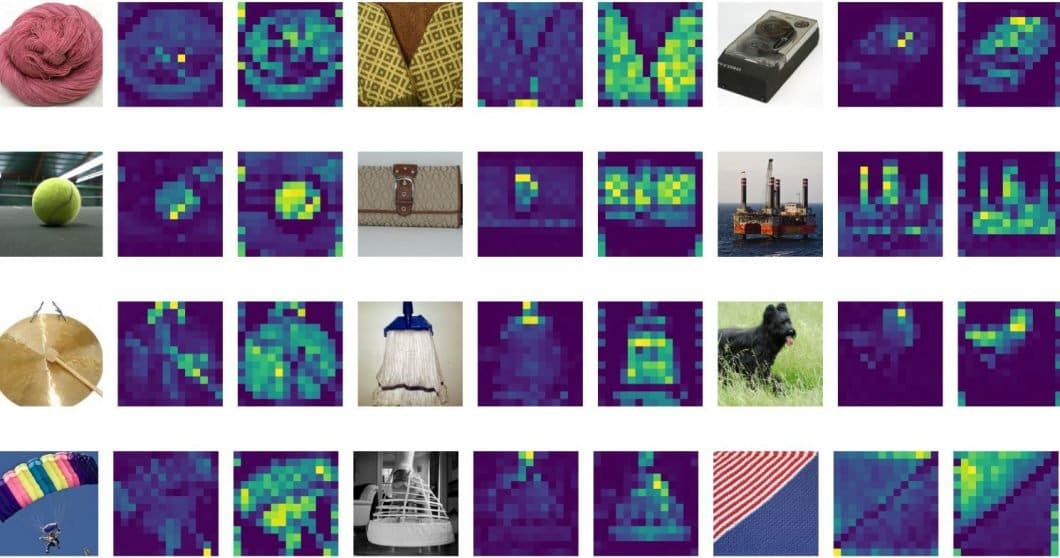
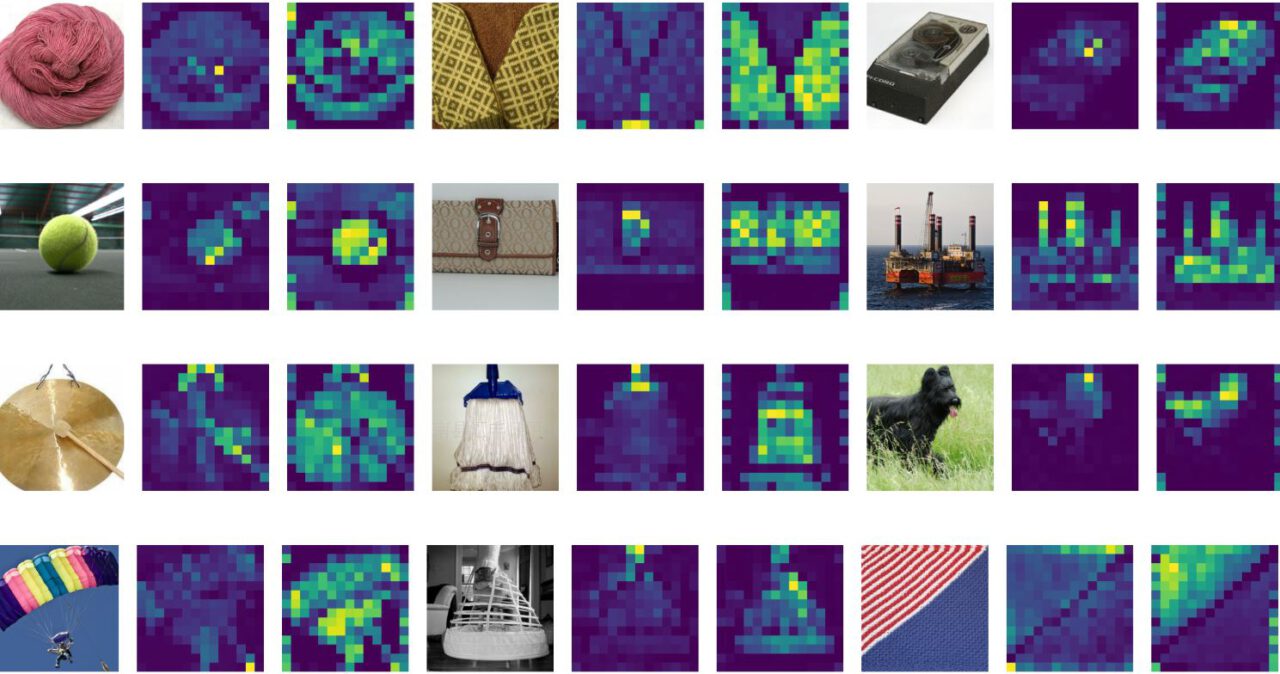
What are the Attention Maps of ViT?
The attention maps of Vision Transformer (ViT) are matrices that represent the importance of different parts of an input image to different parts of the model’s learned representations. In ViT, the entire image of the input data is first divided into non-overlapping patches. We then flatten and feed them into the transformer encoder (more about the architecture below).
Attention maps refer to the visualizations of the attention weights that are calculated between each token (or patch) in the image and all other tokens. These attention maps are calculated using a self-attention mechanism, where each token attends to all other tokens to obtain a weighted sum of their representations.
We can visualize attention maps as a grid of heatmaps, where each heatmap represents the attention weights between a given token and all other tokens. The brighter the color of a pixel in the heatmap, the higher the attention weight between the corresponding tokens. By analyzing the attention maps, we can gain insights into which parts of the image are most important for the classification task at hand.

Vision Transformer ViT Architecture
We can find several proposals for vision transformer models in the literature. The overall structure of the vision transformer architecture consists of the following steps:
- Split an image into patches (fixed sizes)
- Flatten the image patches
- Create lower-dimensional linear embeddings from these flattened image patches
- Include positional embeddings
- Feed the sequence as an input to a SOTA transformer encoder
- Pre-train the ViT model with image labels, then fully supervise on a big dataset
- Fine-tune the downstream dataset for image classification
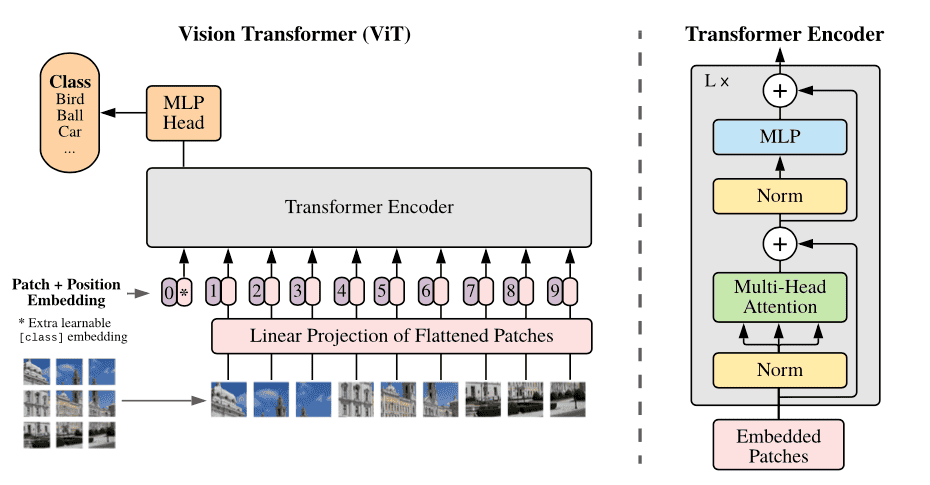
Vision Transformers (ViT) is an architecture that uses self-attention mechanisms to process images. The Vision Transformer Architecture consists of a series of transformer blocks. Each transformer block consists of two sub-layers: a multi-head self-attention layer and a feed-forward layer.
ViT Layers
The self-attention layer calculates attention weights for each pixel in the image based on its relationship with all other pixels, while the feed-forward layer applies a non-linear transformation to the output of the self-attention layer. The multi-head attention extends this mechanism, seen by the model attending to different parts of the input sequence simultaneously.
ViT also includes an additional patch embedding layer, which divides the image into fixed-size patches and maps each patch to a high-dimensional vector representation. These patch embeddings are then fed into the transformer blocks for further processing.
The final output of the ViT architecture is a class prediction, obtained by passing the output of the last transformer block through a classification head. This typically consists of a single fully connected layer.
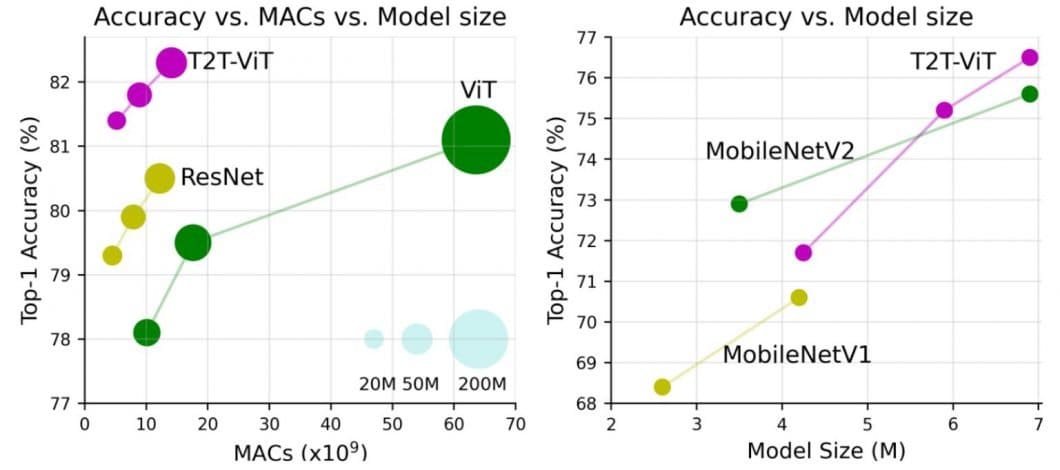
While the ViT full-transformer architecture is a promising option for vision processing tasks, the performance of ViTs is still inferior to that of similar-sized CNN alternatives (such as ResNet) when trained from scratch on a mid-sized dataset such as ImageNet. Overall, the ViT architecture allows for a more flexible and efficient way to process images, without relying on pre-defined handcrafted features.
How does a Vision Transformer (ViT) Work?
The performance of a vision transformer model depends on decisions such as that of the optimizer, network depth, and dataset-specific hyperparameters. Compared to ViT, CNNs are easier to optimize.
The disparity of a pure transformer is to marry a transformer to a CNN front end. The usual ViT stem leverages a 16*16 convolution with a 16 stride. In comparison, a 3*3 convolution with stride 2 increases the stability and improves precision.
CNN turns basic pixels into a feature map. Later, a tokenizer translates the feature map into a sequence of tokens and inputs them into the transformer. The transformer then applies the attention technique to create a sequence of output tokens.
Eventually, a projector reconnects the output tokens to the feature map. The latter allows the examination to navigate potentially crucial pixel-level details. This thereby lowers the number of tokens that need to be studied, lowering costs significantly.
Particularly, if the ViT model is trained on huge datasets that are over 14M images, it can outperform the CNNs. If not, the best option is to stick to ResNet or EfficientNet. The vision transformer model is trained on a huge dataset even before the process of fine-tuning. The only change is to disregard the MLP layer and add a new D times KD*K layer. This is where K is the number of classes of the small dataset.
To fine-tune in better resolutions, we perform the 2D representation of the pre-trained position embeddings. This is because the trainable liner layers model the positional embeddings.
Challenges of Vision Transformers
The challenges of vision transformers are many, and they include issues related to architecture design, generalization, robustness, interpretability, and efficiency.
In general, transformers lack some inductive biases compared to CNNs and rely heavily on massive amounts of data for large-scale training. This is why the quality of data significantly influences the generalization and robustness of transformers in computer vision tasks.
Whilst ViT shows exceptional performance on downstream image classification tasks, for example, VTAB and CIFAR, directly applying the ViT backbone on object detection has failed to surpass the results of CNNs
Additionally, it remains a challenge to fully understand why transformers work well on visual tasks. Furthermore, developing efficient transformer models for computer vision deployable on resource-limited devices is a challenging issue.
Real-World Vision Transformer (ViT) Use Cases and Applications
Vision transformers have extensive applications in popular image recognition tasks such as object detection, segmentation, image classification, and action recognition. Moreover, ViTs are useful in generative modeling and multi-model tasks, including visual grounding, visual-question answering, and visual reasoning.
Video forecasting and activity recognition are all parts of video processing that require ViT. Moreover, image enhancement, colorization, and image super-resolution also use ViT models. Last but not least, ViTs have numerous applications in 3D analysis, such as segmentation and point cloud classification.

Wrapping Up
The vision transformer model uses multi-head self-attention in Computer Vision without needing image-specific biases. The model splits the images into a series of positional embedding patches, the transformer encoder then processes these.
It does so to understand the local and global features that the image possesses. Last, but not the least, the ViT has a higher precision rate on a large dataset with reduced training time.
Further Computer Vision Learning
Read more about related AI topics and machine learning technology, image processing, and recognition.