Convolution Neural Networks (CNNs) are powerful tools that can process any data that looks like an image (matrices) and find important information from it, however, in standard CNNs, every channel is given the same importance. This is what Squeeze and Excite Network improves, it dynamically gives importance to certain channels only (an attention mechanism for channel correlation).
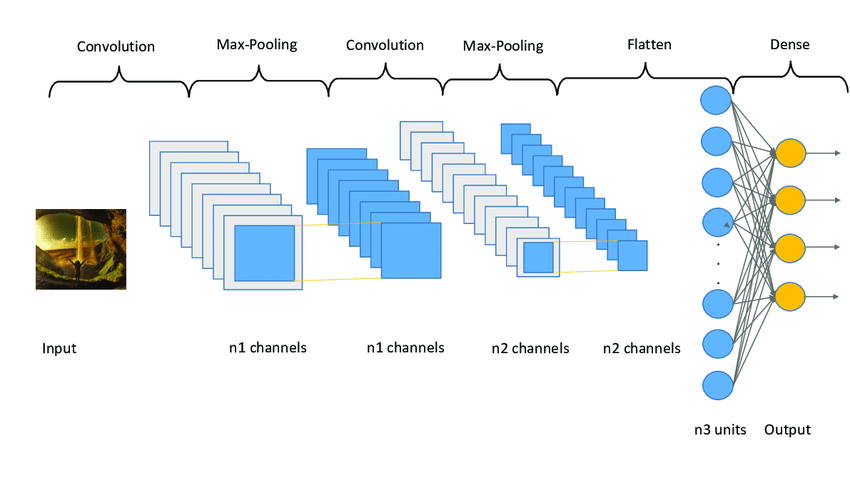
Standard CNNs abstract and extract features of an image with initial layers learning about edges and texture and final layers extracting shapes of objects, performed by convolving learnable filters or kernels, however not all convolution filters are equally important for any given task, and as a result, a lot of computation and performance is lost due to this.
For example, in an image containing a cat, some channels might capture details like fur texture, while others might focus on the overall shape of the cat, which can be similar to other animals. Hypothetically, to perform better, the network may reap better results if it prioritizes channels containing fur texture.
In this blog, we will look in-depth at how Squeeze and Excitation blocks allow dynamic weighting of channel importance and create adaptive correlations between them. For conciseness, we will refer to Squeeze and Excite Networks as “SE
Introduction to Squeeze and Excite Networks
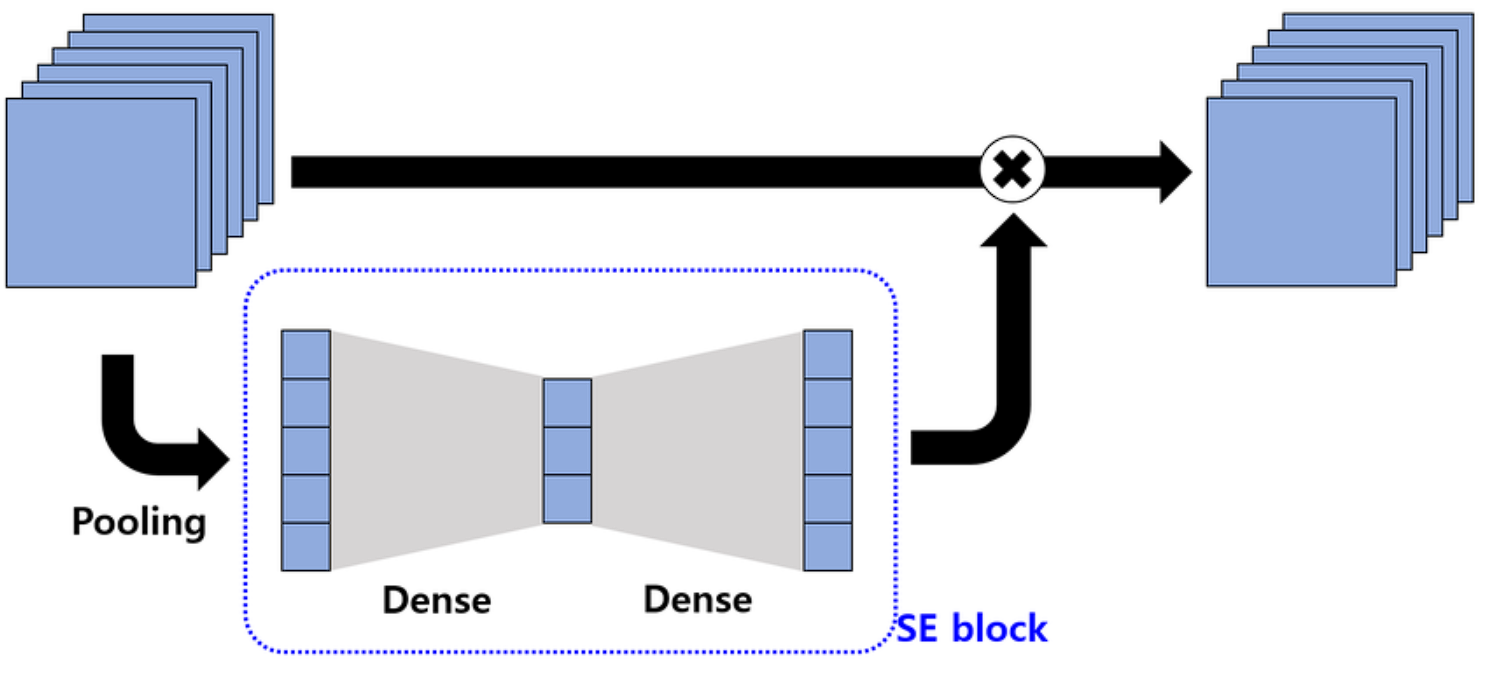
Squeeze and Excite Network is are special block that can be added to any preexisting deep learning architecture such as VGG-16 or ResNet-50. When added to a Network, SE Network dynamically adapts and recalibrates the importance of a channel.
In the original research paper published, the authors show that a ResNet-50 when combined with SENet (3.87 GFLOPs) achieves accuracy that is equivalent to what the original ResNet-101 (7.60GFLOPs) achieves. This means half of the computation is required with the SENet integrated model, which is quite impressive.
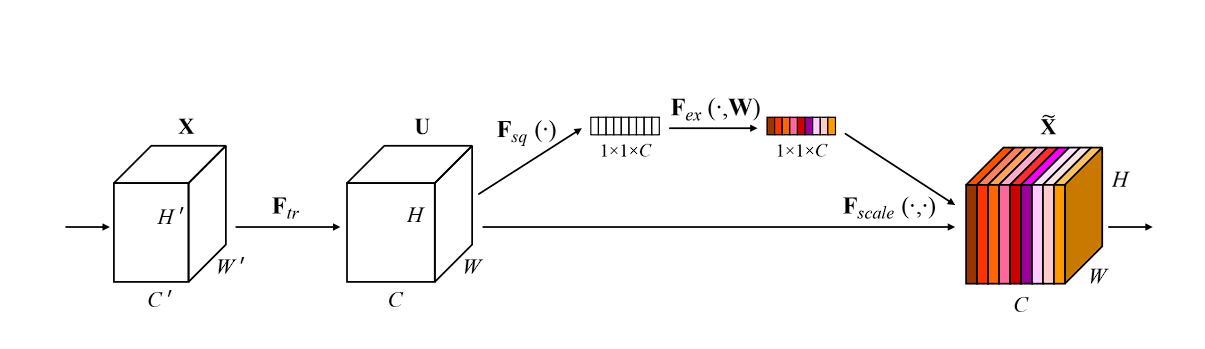
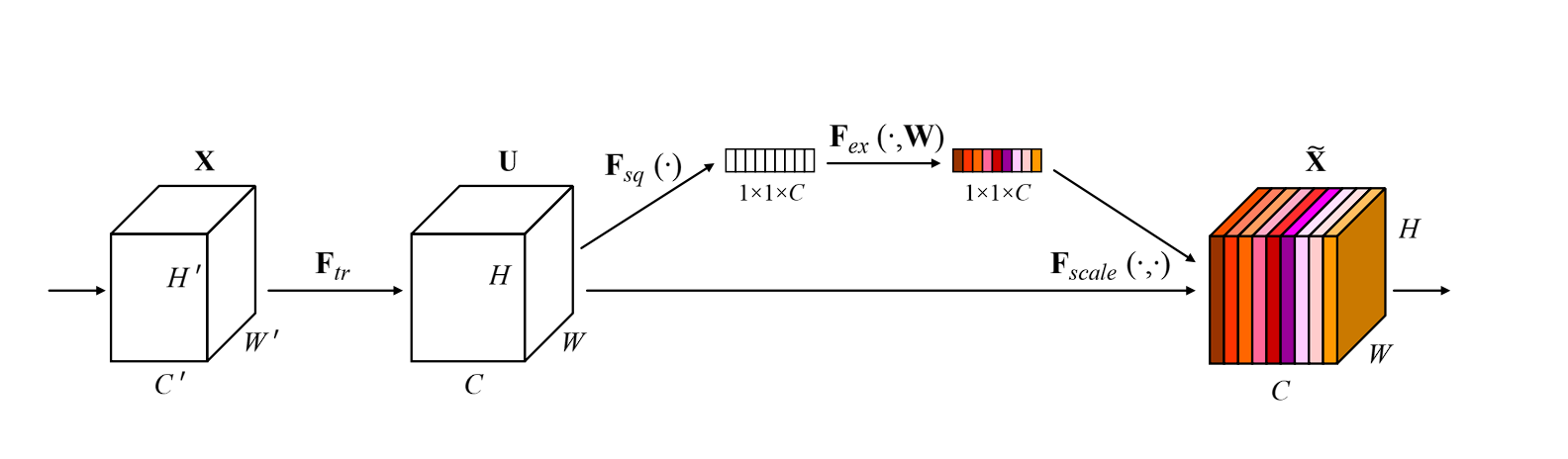
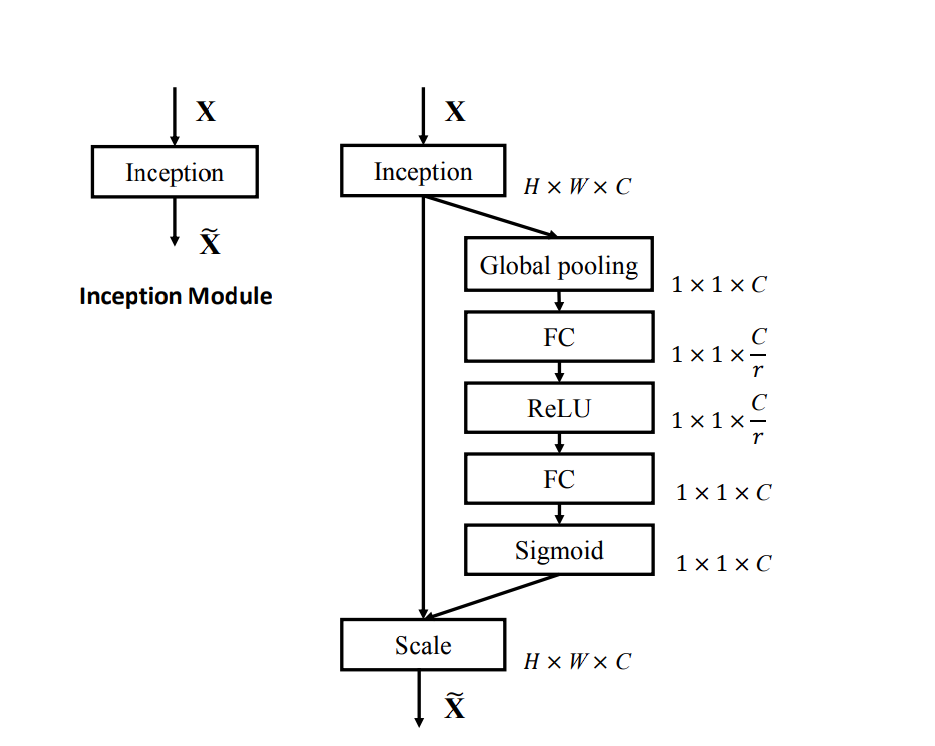
SE Network can be divided into three steps: squeeze, excite, and scale.
- Squeeze: This first step in the network captures the global information from each channel. It uses global average pooling to squeeze each channel of the feature map into a single numeric value. This value represents the activity of that channel.
- Excite: The second step is a small, fully connected neural network that analyzes the importance of each channel based on the information captured in the previous step. The output of the excitation step is a set of weights for each channel that tells which channel is important.
- Scale: At the end, the weights are multiplied by the original channels or feature map, scaling each channel according to its importance. Channels that prove to be important for the network are amplified, whereas unimportant channel is suppressed and given less importance.
Overall, this is an overview of how the SE network works. Now let’s dive deeper into the technical details.
How does SENet Work?
Squeeze Operation
The Squeeze operation condenses the information from each channel into a single vector using global average pooling.
The global average pooling (GAP) layer is a crucial step in the process of SENet, standard pooling layers (such as max pooling) found in CNNs reduce the dimensionality of the input while retaining the most prominent features, in contrast, GAP reduces each channel of the feature map to a single value by taking the average of all elements in that channel.
How GAP Aggregates Feature Maps
- Feature Map Input: Suppose we have a feature map F from a convolutional layer with dimensions H×W×C, where H is the height, W is the width, and C is the number of channels.
- Global Average Pooling: The GAP layer processes each channel independently. For each channel c in the feature map F, GAP computes the average of all elements in that channel. Mathematically, this can be represented as:
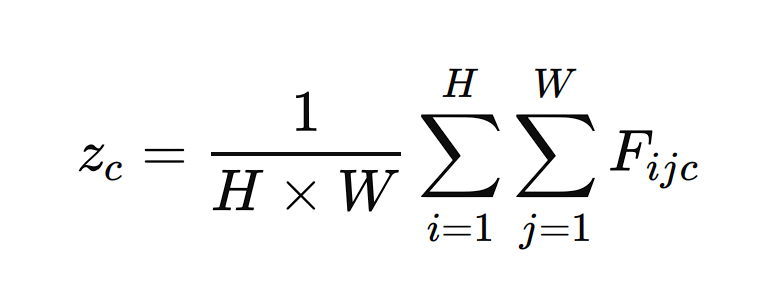
Here, zc is the output of the GAP layer for channel c, and Fijc is the value of the feature map at position (I,j) for channel c.
Output Vector: The result of the GAP layer is a vector z with a length equal to the number of channels C. This vector captures the global spatial information of each channel by summarizing its contents with a single value.
Example: If a feature map has dimensions 7×7×512, the GAP layer will transform it into a 1×1×512 vector by averaging the values in each 7×7 grid for all 512 channels.
Excite Operation
Once the global average pooling is done on channels, it results in a single vector for each channel. The next step the SE network performs is excitation.
In this, using a fully connected Neural Network, channel dependencies are obtained. This is where the important and less important channels are distinguished. Here is how it is performed:
Input vector z is the output vector from GAP.
The two fully connected neural network layers reduce the dimensionality of the input vector to a smaller size C/r, where r is the reduction ratio (a hyperparameter that can be adjusted). This dimensionality reduction step helps in capturing the channel dependencies.
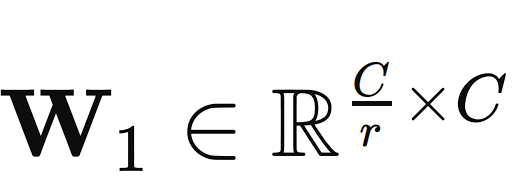
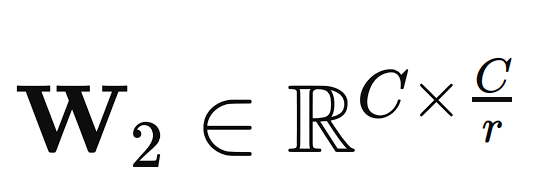
The first layer is a ReLU (Rectified Linear Unit) activation function that is applied to the output of the first FC layer to introduce non-linearity
s= ReLU(s)
The second layer is another fully connected layer
Finally, the Sigmoid activation function is applied to scale and smooth out the weights according to their importance. Sigmoid activation outputs a value between 0 and 1.
w=σ(w)
Scale Operation
The Scale operation uses the output from the Excitation step to rescale the original feature maps. First, the output from the sigmoid is reshaped to match the number of channels, broadcasting w across dimensions H and W.
The final step is the recalibration of the channels. This is done by element-wise multiplication. Each channel is multiplied by the corresponding weight.
Fijk=wk⋅Fijk
Here, Fijk is the value of the original feature map at position (i,j) in channel k, and is the weight for channel k. The output of this function is the recalibrated feature map value.
The Excite operation in SENet leverages fully connected layers and activation functions to capture and model channel dependencies that generate a set of importance weights for each channel.
The Scale operation then uses these weights to recalibrate the original feature maps, enhancing the network’s representational power and improving performance on various tasks.
Integration with Existing Networks
Squeeze and Excite Networks (SENets) are easily adaptable and can be easily integrated into existing convolutional neural network (CNN) architectures, as the SE blocks operate independently of the convolution operation in whatever architecture you are using.
Moreover, talking about performance and computation, the SE block introduces negligible added computational cost and parameters, as we have seen that it is just a couple of fully connected layers and simple operations such as GAP and element-wise multiplication.
These processes are cheap in terms of computation. However, the benefits in accuracy they provide are great.
Model Integrations with SENets
SE-ResNet: In ResNet, SE blocks are added to the residual blocks of ResNet. After each residual block, the SE block recalibrates the output feature maps. The result of adding SE blocks is visible with the increase in the performance on image classification tasks.
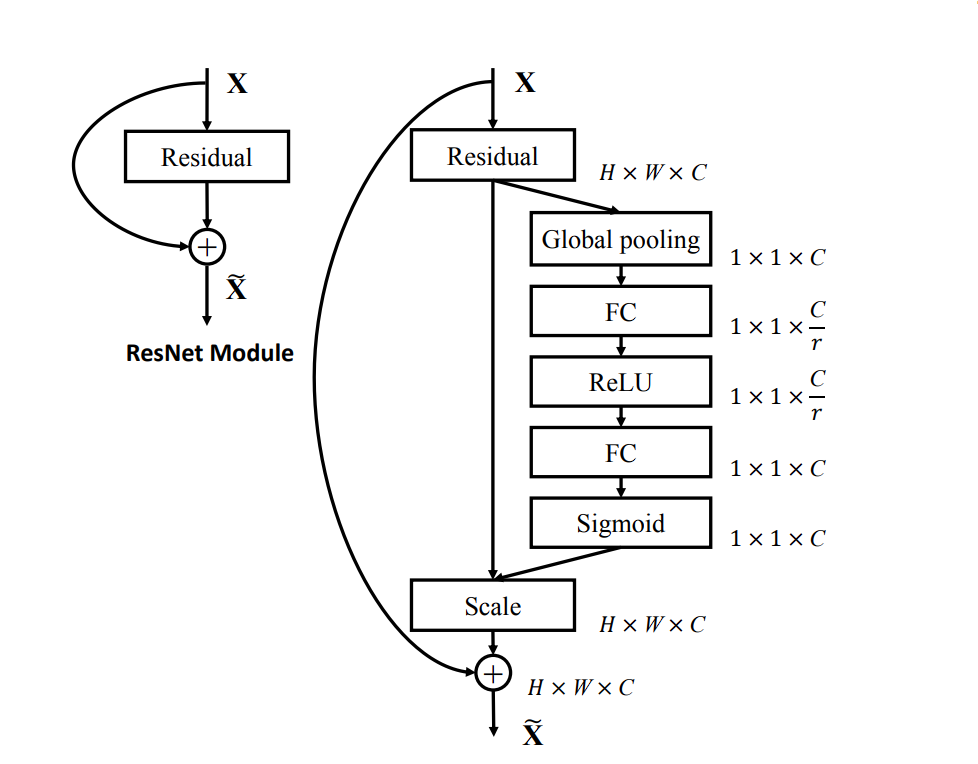
SE-Inception: In SE-Inception, SE blocks are integrated into the Inception modules. The SE block recalibrates the feature maps from the different convolutional paths within each Inception module.
SE-MobileNet: In SE-MobileNet, SE blocks are added to the depthwise separable convolutions in MobileNet. The SE block recalibrates the output of the depthwise convolution before passing it to the pointwise convolution.
SE-VGG: In SE-VGG, SE blocks are inserted after each group of convolutional layers. That is, an SE block is added after each pair of convolutional layers followed by a pooling layer.
Benchmarks and Testing

Mobile Net
- The original MobileNet has a top-1 error of 29.4%. After re-implementation, this error is reduced to 28.4%. However, when we couple it with SENet, the top-1 error drastically reduces to 25.3%, showing a significant improvement.
- The top-5 error is 9.4% for the re-implemented MobileNet, which improves to 7.7% with SENet.
- However, using the SENet increases the computation cost from 569 to 572 MFLOPs with SENet, which is quite good for the accuracy improvement achieved.
ShuffleNet
- The original ShuffleNet has a top-1 error of 32.6%. The re-implemented version maintains the same top-1 error. When enhanced with SENet, the top-1 error reduces to 31.0%, showing an improvement.
- The top-5 error is 12.5% for the re-implemented ShuffleNet, which improves to 11.1% with SENet.
- The computational cost increases slightly from 140 to 142 MFLOPs with SENet.
In both MobileNet and ShuffleNet models, the addition of the SENet block significantly improves the top-1 and top-5 errors.
Benefits of SENet
Squeeze and Excite Networks (SENet) offer several advantages. Here are some of the benefits we can see with SENet:
Improved Performance
SENet improves the accuracy of image classification tasks by focusing on the channels that contribute the most to the detection task. This is just like adding an attention mechanism to channels (SE blocks provide insight into the importance of different channels by assigning weights to them). This results in increased representation by the network, as the better layers are focused more and further improved.
Negligible Computation Overhead
The SE blocks introduce a very small number of additional parameters in comparison to scaling a model. This is possible because SENet uses Global average pooling that summarizes the model channel-wise and is a couple of simple operations.
Easy Integration With Existing Models
SE blocks seamlessly integrate into existing CNN architectures, such as ResNet, Inception, MobileNet, VGG, and DenseNet.
Moreover, these blocks can be applied as many times as desired:
- In various parts of the network
- From the earlier layers to the final layers of the network
- Adapting to continuous, diverse tasks performed throughout the deep learning model, you integrate SE into
Robust Model
Finally, SENet makes the model tolerant towards noise, because it downgrades the channels that might be contributing negatively to the model performance. Thus, making the model ultimately generalize on the given task better.
What’s Next with Squeeze and Excite Networks
In this blog, we looked at the architecture and benefits of Squeeze and Excite Networks (SENet), which serve as an added boost to the already developed model. This is possible due to the concept of “squeeze” and “excite” operations which makes the model focus on the importance of different channels in feature maps, this is different from standard CNNs which use fixed weights across all channels and give equal importance to all the channels.
We then looked in-depth into the squeeze, excite, and scale operation. Where the SE block first performs a global average pooling layer, which compresses each channel into a single value. Then, fully connected layers and activation functions model the relationship between channels. Finally, the scale operation rescales the importance of each channel by multiplying the output weight from the excitation step.
Additionally, we also looked at how SENet can be integrated into existing networks such as ResNet, Inception, MobileNet, VGG, and DenseNet with minimally increased computations.
Overall, the SE block results in improved performance, robustness, and generalizability of the existing model.