
In the following, we will explore Convolutional Neural Networks (CNNs), a key element in computer vision and image processing. Whether you’re a beginner or an experienced practitioner, this guide will provide insights into the mechanics of artificial neural networks and their applications.
The History of Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNN) have gone through continual evolution and sophistication. It started back in the 1980s with the development of LeNet by Yann LeCun. LeNet, primarily used for digit recognition tasks, laid the foundational architecture for CNNs. Its architecture model consists of a convolutional, pooling operation, and fully connected layers.
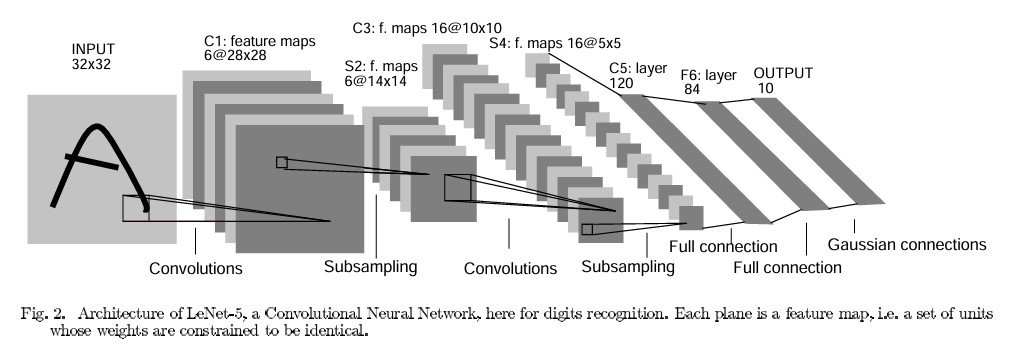
In 2012, the AlexNet architecture, designed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton, marked a breakthrough in the ImageNet challenge by significantly reducing error rates. AlexNet’s success was attributed to its deeper and more complex architecture, use of ReLU (Rectified Linear Unit) as an activation function, and implementation of dropout layers to prevent overfitting.
VGGNet, introduced by Simonyan and Zisserman in 2014, emphasized the importance of depth in CNN architectures through its 16-19 layer CNN network. GoogleNet (or Inception) brought the novel concept of inception modules, enabling efficient computation and deeper networks without a significant increase in parameters.
ResNet, developed by Kaiming He et al., introduced residual connections to facilitate the training of even deeper networks. This surpassed the depth of previous architectures with its 152 convolutional layers.
Recent innovations in CNN design focus on optimizing network efficiency and performance. Computer vision papers such as “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications” by Andrew G. Howard et al. and “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks” by Mingxing Tan and Quoc V. Le propose architectures that balance accuracy and computational efficiency.
This makes them suitable for real-world applications, especially on devices with limited computational capacity.
Learn about two other popular types of regular neural networks: Multi-Layer Perceptrons (MLP) and Recurrent Neural Networks (RNN).
Convolutional Neural Networks in Computer Vision: Beyond Image Classification
CNNs have had a profound impact on computer vision, going far beyond basic image classification. Their ability to interpret visual data has been pivotal in object detection, segmentation, video analysis, and real-time processing.
Object Detection and Segmentation
In object detection, CNN neural networks identify and locate multiple objects within an image. This task is more complex than classification, as it involves recognizing objects and pinpointing their exact locations.
The Region-Based Convolutional Neural Network (R-CNN) architecture and its subsequent iterations, Fast R-CNN and Faster R-CNN, have been instrumental in this. These architectures use a combination of selective search to propose regions and CNNs for classification. Thus, significantly improving the accuracy and speed of object detection.

CNNs enable similar progress in image segmentation. This task involves dividing an image into segments to locate and understand objects at the pixel level. U-Net, a CNN architecture for biomedical image segmentation, is a prime example. Its unique U-shaped design consists of a contracting path to capture context and a symmetric expanding path for precise localization.
Advances in Video Analysis and Real-Time Processing
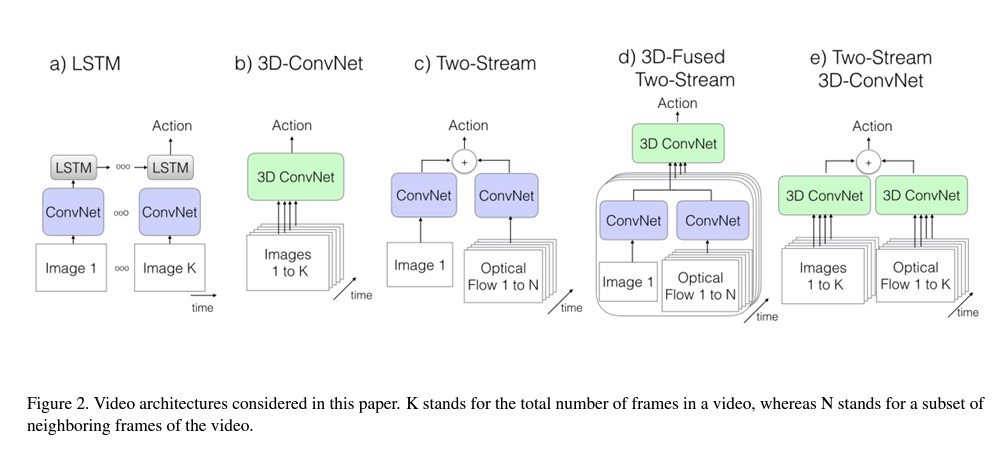
In tasks like action recognition and anomaly detection in videos, CNNs must understand temporal dynamics and spatial features. Architectures like the 3D Convolutional Neural Networks (3D CNNs) extend the conventional 2D convolution to three dimensions. This allows the network to learn both spatial and temporal features.
A recent paper, “Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset” by João Carreira and Andrew Zisserman, presents the Inflated 3D ConvNet (I3D) model that inflates filters and pooling kernels of a 2D CNN into 3D. This enables it to learn spatiotemporal features for video action recognition.
Case Studies From Recent Research
Recent case studies show the application of CNNs in real-time object detection systems in autonomous vehicles. Networks like YOLO (You Only Look Once) and SSD (Single Shot Multibox Detector) have a design that provides fast and efficient object detection suitable for real-time processing.
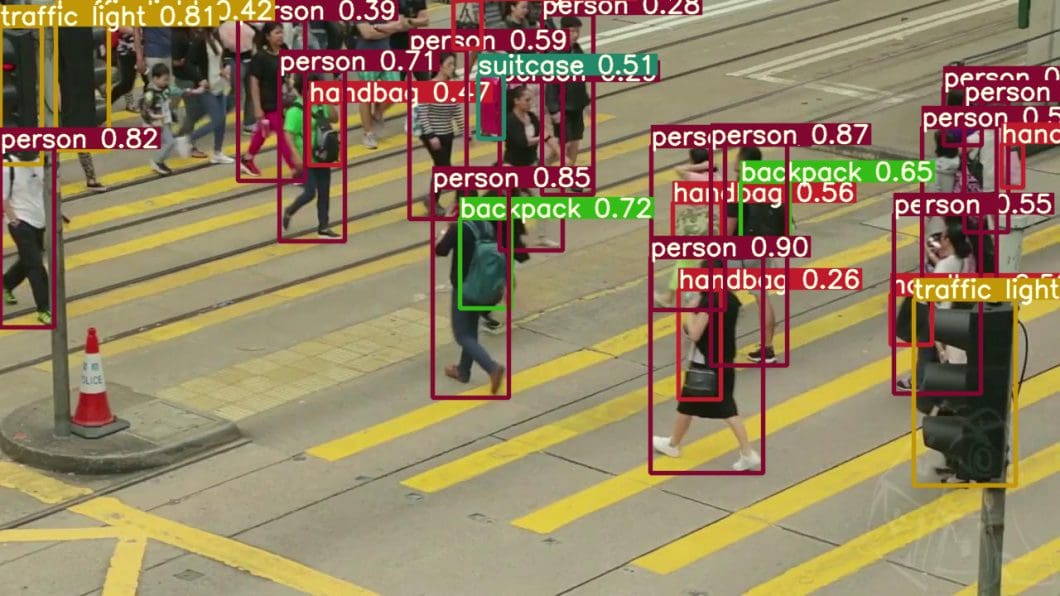
Balancing speed and accuracy, CNNs are ideal for safety-critical applications, such as autonomous driving.
Another groundbreaking application is in environmental monitoring. Research utilizing CNNs for real-time analysis of satellite imagery to detect environmental changes and natural disasters has immense potential for real-time global monitoring and response systems.
Deep Dive: Convolutional Neural Network Algorithms for Specific Challenges
CNNs, while powerful, face distinct challenges in their application, particularly in scenarios like data scarcity, overfitting, and unstructured data environments. Innovative techniques and training algorithms address these challenges, enhancing the robustness and efficacy of CNNs.
Addressing Data Scarcity and Overfitting
A limited dataset can lead to overfitting, where the model performs well on a training set but poorly on unseen data. Data augmentation is becoming a widely adopted technique to overcome this.

It involves artificially expanding the training dataset using various transformations like rotation, scaling, and flipping. This not only diversifies the training data but also helps the model generalize better to new data.
A study titled “Understanding Data Augmentation for Classification: When to Warp?” by Terrance DeVries and Graham W. Taylor provides insights into the effectiveness of different data augmentation techniques in improving model robustness.
They mainly compared two popular methods: data warping and synthetic over-sampling. While data warping was generally more effective, the results depend on the classifier and nature of your data.
CNNs in Unstructured Data Environments
CNNs are traditionally used in structured environments like image processing, where data is in grid-like formats. However, their application in unstructured data environments like irregular graphs or social networks is challenging.
Graph Convolutional Networks (GCNs) are emerging as one potential solution. GCNs extend the concept of convolution to graph-structured data, enabling feature extraction from such unstructured environments effectively.
The paper “Semi-Supervised Classification with Graph Convolutional Networks” by Thomas N. Kipf and Max Welling showcases the application of GCNs in semi-supervised learning on graph-structured data.
Innovations in Training Algorithms
Training CNNs efficiently and effectively is crucial for their performance. Recent innovations in training algorithms focus on optimizing learning processes and improving convergence rates.
One example is Batch Normalization, detailed in the paper “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift” by Sergey Ioffe and Christian Szegedy. Batch Normalization standardizes the image input to a layer for each mini-batch. This stabilizes the learning process and significantly accelerates the training of deep networks.
Another significant advancement is the development of attention mechanisms in CNNs. The paper “Attention Is All You Need” by Vaswani et al. introduced the Transformer model, which relies heavily on attention mechanisms.
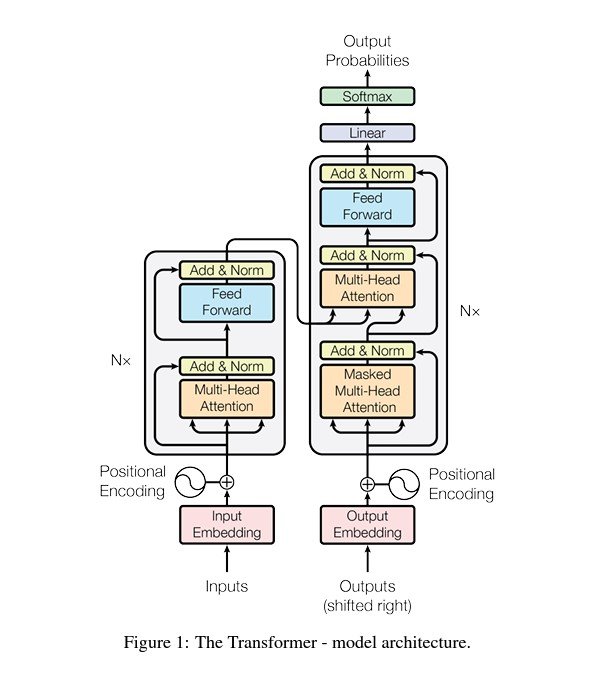
This concept has been adapted in various CNN architectures to improve their ability to focus on relevant features in the data. This leads to better performance, especially in complex tasks like image captioning and visual question answering.
Convolutional Neural Networks in Non-Visual Applications
CNNs excel in handling visual tasks. However, their application extends into non-visual domains such as text and audio processing and even bioinformatics. Some of the architectures included above use this versatility, such as in videos where imagery must be segmented per audio cues.
Text Processing with CNNs
In text processing, CNNs are remarkably efficient, particularly in tasks like sentiment analysis, topic categorization, and language translation. Unlike traditional text processing methods that rely on linear approaches, CNNs can capture hierarchical patterns in text data.
For instance, a CNN model can identify semantic patterns at the character level, then combine these to understand words and ultimately derive sentence-level meanings. This hierarchical processing mirrors human language comprehension, making CNNs effective in complex text analysis tasks.
Other applications of CNNs in text processing include:
- Sentiment Analysis
- Topic Categorization
- Language Translation
Audio Processing with CNNs
In audio processing, CNNs have been instrumental in tasks like speech recognition, sound classification, and even music composition. Their ability to process time-series data and extract features from raw audio makes them well-suited for analyzing intricate patterns in sound.
For example, CNNs can distinguish various sounds in an environment, applicable in use cases like intelligent voice assistants and sound classification systems in urban and wildlife monitoring.
Other applications of CNNs in audio processing include:
- Speech Recognition
- Sound Classification
- Music Composition
Other Uses and Emerging Trends
In bioinformatics, CNNs are increasingly used for tasks such as protein structure prediction and genetic data analysis. Their capacity to process large, complex datasets enables them to uncover patterns in genetic sequences. This has the potential to aid medical practitioners in disease diagnosis and drug discovery.
Recent studies have demonstrated how CNNs can analyze genomic sequences to identify mutations and predict disease susceptibility, transforming personalized medicine and genomics research.
Emerging trends include the integration of CNNs with other AI techniques like reinforcement learning and generative models. This is expanding the capabilities of CNNs in non-visual applications. Thus, leading to more sophisticated and accurate models capable of tackling complex tasks across various fields.
Other applications of CNNs include:
- Protein Structure Prediction
- Genetic Data Analysis
- Mutation Identification
- Integration with Reinforcement Learning
- Combination with Generative Models
Case Study: Real-World Impact of Convolutional Neural Networks
A recent real-world application of CNNs is in the field of Human Activity Recognition (HAR). A study developed an improved CNN-based technique for HAR interpreting sensor sequence data, capturing temporal and spatial information related to human activities.

The proposed model uses a two-dimensional CNN approach to classify different human activities. It achieved an accuracy rate of 97.20%, surpassing previous state-of-the-art techniques.
This demonstrates the potential of CNNs in accurately recognizing and interpreting complex human activities. This capability may have a massive impact on various fields that rely on that benefit from HAR, including:
- Medical image analysis
- Image classification
- Object recognition from videos
- Recommender systems
- Financial time series analysis
- Natural language processing
- Human-computer interfaces
The Future Direction and Challenges in Convolutional Neural Networks
CNNs continue to evolve, opening new frontiers of neural networks in AI and machine learning. However, we can expect to see even more development in terms of:
- Enhanced computational efficiency, making them more viable on smaller devices.
- Advancements in processing 3D data and complex time series.
- Increased integration with other AI domains, like reinforcement learning and unsupervised learning.
However, these advancements come with their own set of challenges:
- Overcoming the heavy reliance on large, labeled datasets.
- Addressing biases to ensure fairness in model training.
- Making CNN models more interpretable and explainable.
- Improving the resilience of CNNs against adversarial attacks and data noise.
- These developments and challenges underscore the dynamic nature of CNNs, highlighting both their vast potential and hurdles to overcome.
As we’ve already seen, some innovative papers have already suggested methods to counteract some of these potential obstacles. There’s no doubt that we’ll see more CNNs developed as we have yet to discover their full potential.