
Deep residual networks like the popular ResNet-50 model are a convolutional neural network (CNN) that is 50 layers deep. A Residual Neural Network (ResNet) is an Artificial Neural Network (ANN) of a kind that stacks residual blocks on top of each other to form a network.
Deep Residual Learning for Image Recognition
In recent years, the field of computer vision has undergone far-reaching transformations due to the introduction of new technologies. As a direct result of these advancements, it has become possible for computer vision deep models to surpass humans in efficiently solving different problems related to image recognition, object detection, face recognition, image classification, etc.
In this regard, the introduction of deep convolutional neural networks or CNNs deserves special mention. These networks have been extensively used for analyzing visual imagery with remarkable accuracy.
But, while it gives us the option of adding more fully connected layers to the CNNs to solve more complicated tasks in computer vision, it comes with its own set of issues. It has been observed that training the neural networks becomes more difficult with the increase in the number of added layers, and in some cases, the accuracy dwindles as well.
It is here that the use of ResNet assumes importance. Deeper neural networks are more difficult to train. With ResNet, it becomes possible to surpass the difficulties of training very deep neural networks.
What is ResNet?
ResNet stands for Residual Network. It is an innovative neural network architecture that was first introduced by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun in their 2015 computer vision research paper titled ‘Deep Residual Learning for Image Recognition’.
This model was immensely successful, as can be ascertained from the fact that its ensemble won the top position at the ILSVRC 2015 classification competition with a training error of only 3.57%. Additionally, it also came first in ImageNet detection, ImageNet dataset localization, COCO detection, and COCO segmentation in the ILSVRC & COCO in 2015 competitions.
Additionally, ResNet has many variants that run on the same concept but have different numbers of pooling layers. Resnet50 is used to denote the variant that can work with 50 neural network layers.
ResNet Importance
Deep Neural Networks in Computer Vision
When working with deep convolutional neural networks to solve a problem related to computer vision, machine learning experts engage in stacking more layers. These additional layers help solve complex problems more efficiently as the different layers could be trained for varying tasks to get highly accurate results.
While the number of stacked layers can enrich the features of the model, a deeper network can show the issue of degradation. In other words, as the number of layers of the neural network increases, the accuracy levels may get saturated and slowly degrade after a point. As a result, the performance of the model deteriorates both on the training and testing data.
This degradation is not a result of overfitting. Instead, it may result from the initialization of the network, optimization function, or, more importantly, the problem of vanishing or exploding gradients.

Application
ResNet was created to tackle this exact problem. Deep residual nets make use of residual mapping blocks to improve the accuracy of the models. The concept of “skip connections,” which lies at the core of the residual blocks, is the strength of this type of neural network.
Skip Connections
These skip connections work in two ways. Firstly, they alleviate the issue of vanishing gradient by setting up an alternate shortcut for the gradient to pass through. In addition, they enable the model to learn an identity function. This ensures that the higher layers of the model do not perform any worse than the lower layers.
In short, the residual connection blocks make it considerably easier for the layers to learn identity functions. As a result, ResNet improves the efficiency of deep neural networks with more neural layers while minimizing the percentage of test errors. In other words, the skip connections add the outputs from previous layers to the outputs of stacked layers, making it possible to train much deeper networks than previously possible.
ResNet Architecture
In the following, we will introduce the architecture of the most popular ResNets and show how they are different.
ResNet-34
The first ResNet architecture was the Resnet-34 (find the research paper here), which involved the insertion of shortcut connections in turning a plain network into its residual network counterpart. In this case, the plain network was inspired by VGG neural networks (VGG-16, VGG-19), with the convolutional networks having 3×3 filters. However, compared to VGGNets, ResNets have fewer filters and lower complexity. The 34-layer ResNet achieves a performance of 3.6 bn FLOPs, compared to 1.8bn FLOPs of smaller 18-layer ResNets.
It also followed two simple design rules – the layers had the same number of filters for the same output feature map size, and the number of filters doubled in case the feature map size was halved in order to preserve the time complexity per layer. It consisted of 34 weighted layers.
The shortcut connections were added to this plain network. While the input and output dimensions were the same, the identity shortcuts were directly used. With an increase in the dimensions, there were two options to be considered. The first was that the shortcut would still perform identity mapping, while extra zero entries would be padded for increasing dimensions. The other option was to use the projection shortcut to match dimensions.
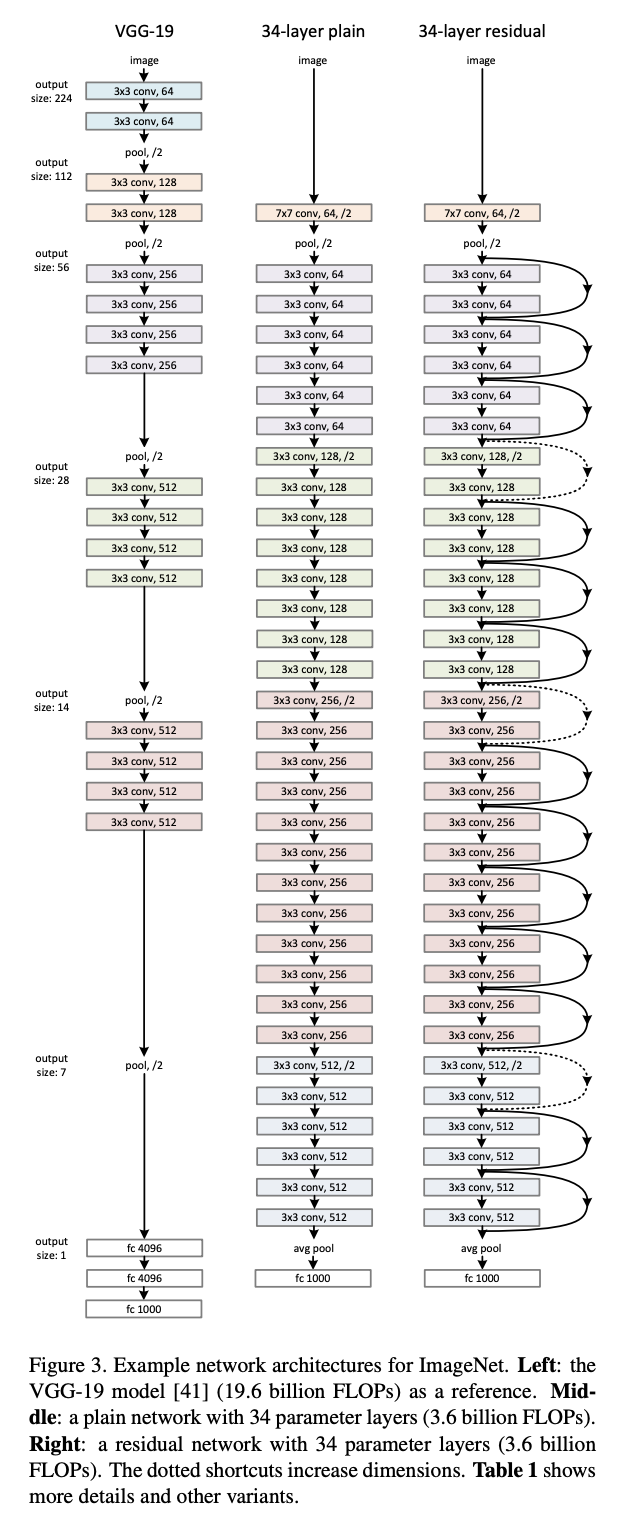
ResNet-50
While the ResNet50 architecture is based on the above model, there is one major difference. In this case, the building block was modified into a bottleneck design due to concerns over the time taken to train the layers. This used a stack of 3 layers in ResNet-50 instead of the earlier 2.
Therefore, each of the 2-layer blocks in Resnet34 was replaced with a 3-layer bottleneck block, forming the Resnet-50 architecture. This has much higher accuracy than the 34-layer ResNet model. The 50-layer ResNet-50 achieves a performance of 3.8 bn FLOPS.
ResNet-101 and ResNet-152
Large Residual Networks such as 101-layer ResNet101 or ResNet152 are constructed by using more than 3-layer blocks. And even at increased network depth, the 152-layer ResNet has much lower complexity (at 11.3bn FLOPS) than VGG-16 or VGG-19 nets (15.3/19.6bn FLOPS).

ResNet-50 With Keras
Keras is a deep learning API that is popular due to the simplicity of building models using it. Keras comes with several pre-trained models, including Resnet50, that anyone can use for their experiments.
Therefore, building a residual network in Keras for computer vision tasks like image classification is relatively simple. You only need to follow a few simple steps.
How to Use ResNet 50 with Keras
- Step #1: Firstly, you need to run a code to define the identity blocks to transform the CNN into a residual network and build the convolution block.
- Step #2: The next step is building the 50-layer ResNet model by combining both blocks.
- Step #3: Finally, you need to train the model for the required task. Keras allows you to easily generate a detailed summary of the network architecture you built. This can be saved or printed for future use.
Starting with Computer Vision Algorithms
To sum up, residual network or ResNet was a major innovation that has changed the training of deep convolutional neural networks for tasks related to computer vision. While the original Resnet had 34 layers and used 2-layer blocks, other advanced variants, such as the Resnet50, made use of 3-layer bottleneck blocks to ensure improved accuracy and lesser training time.
If you need a future-proof way to use ResNet and other computer vision algorithms in commercial applications, check out our computer vision platform. The solution is used by leading companies to build, deploy, and operate their AI vision applications. Get a demo for your organization.
Read our other articles about related neural networks and state-of-the-art deep learning algorithms, and methods.
- Mask R-CNN: A Beginner’s Guide
- The Most Popular Deep Learning Software Today
- Deep Neural Network: The 3 Popular Types (MLP, CNN, and RNN)
- Machine Learning Algorithms: Mathematical Deep Dive
- Supervised vs Unsupervised Learning for Computer Vision
- YOLOv7: The Most Powerful Object Detection Algorithm
- A Guide to Pattern Recognition