This article provides an overview of VGG, also known as VGGNet, a classical convolutional neural network (CNN) architecture. VGG was developed to increase the depth of such CNNs to increase the model performance.
In the past years, deep learning has brought tremendous success in a wide range of computer vision tasks. This new field of machine learning has since been growing rapidly. State-of-the-art performance of deep learning over traditional machine learning approaches enables new applications in image recognition, computer vision, speech recognition, machine translation, medical imaging, robotics, and many more.
What is VGG?
VGG stands for Visual Geometry Group; it is a standard deep Convolutional Neural Network (CNN) architecture with multiple layers. The “deep” refers to the number of layers with VGG-16 or VGG-19 consisting of 16 and 19 convolutional layers.
The VGG architecture is the basis of ground-breaking object recognition models. Developed as a deep neural network, the VGGNet also surpasses baselines on many tasks and datasets beyond ImageNet. Moreover, it is still one of the most popular image recognition architectures.
What is VGG16?
The VGG model, or VGGNet, that supports 16 layers is also referred to as VGG16, which is a convolutional neural network (CNN) model proposed by A. Zisserman and K. Simonyan from the University of Oxford. These researchers published their model in the research paper titled, “Very Deep Convolutional Networks for Large-Scale Image Recognition.”
The VGG16 model achieves almost 92.7% top-5 test accuracy in ImageNet. ImageNet is a dataset consisting of more than 14 million images belonging to nearly 1000 classes. Moreover, it was one of the most popular models submitted to ILSVRC-2014. It replaces the large kernel-sized filters with several 3×3 kernel-sized filters one after the other, thereby making significant improvements over AlexNet. The VGG16 model was trained using Nvidia Titan Black GPUs for multiple weeks.
As mentioned above, the VGGNet-16 supports 16 layers and can classify images into 1000 object categories, including keyboard, animals, pencil, mouse, etc. Additionally, the model has an image input size of 224-by-224.

What is VGG19?
The concept of the VGG19 model (also VGGNet-19) is the same as the VGG16, except that it supports 19 layers. The “16” and “19” stand for the number of weight layers in the model (convolutional layers). This means that VGG19 has three more convolutional layers than VGG16. We’ll discuss more about the characteristics of VGG16 and VGG19 networks in the latter part of this article.
VGG Convolutional Network Architecture
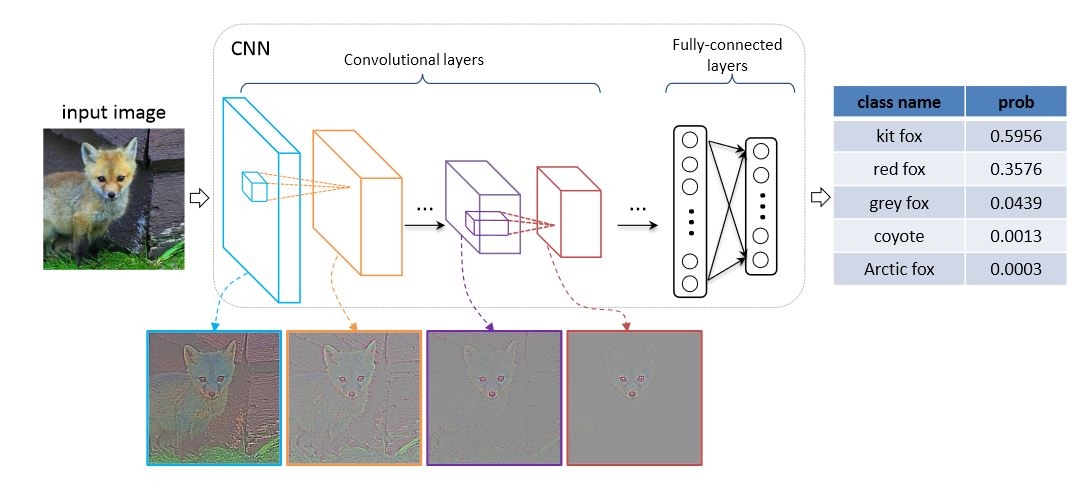
VGGNets are based on the most essential features of convolutional neural networks (CNN). The following graphic shows the basic concept of how a CNN works:
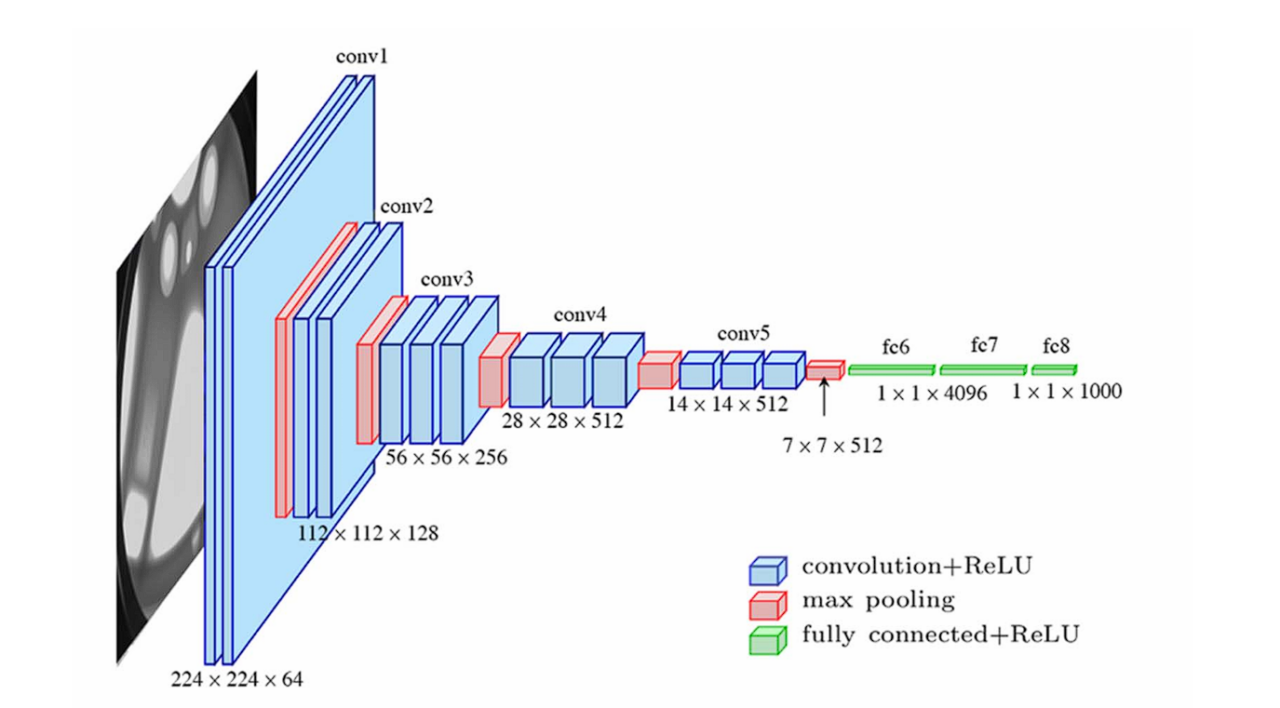
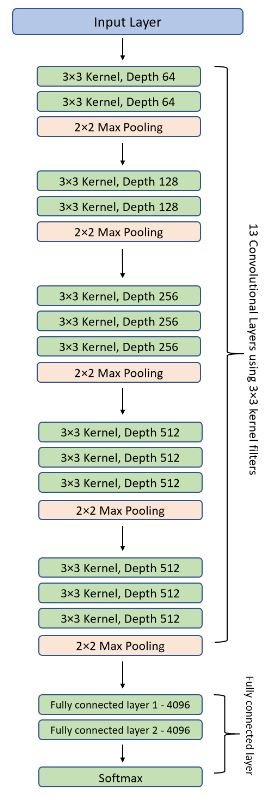
The VGG network is constructed with very small convolutional filters. The VGG-16 consists of 13 convolutional layers and three fully connected layers.
Let’s take a brief look at the architecture of VGG:
- Input: The VGGNet takes in an image input size of 224×224. For the ImageNet competition, the creators of the model cropped out the center 224×224 patch in each image to keep the input size of the image consistent.
- Convolutional Layers: VGG’s convolutional layers leverage a minimal receptive field, i.e., 3×3, the smallest possible size that still captures up/down and left/right. Moreover, there are also 1×1 convolution filters acting as a linear transformation of the input. This is followed by a ReLU unit, which is a huge innovation from AlexNet that reduces training time. ReLU stands for rectified linear unit activation function; it is a piecewise linear function that will output the input if positive; otherwise, the output is zero. The convolution stride is fixed at 1 pixel to keep the spatial resolution preserved after convolution (stride is the number of pixel shifts over the input matrix).
- Hidden Layers: All the hidden layers in the VGG network use ReLU. VGG does not usually leverage Local Response Normalization (LRN) as it increases memory consumption and training time. Moreover, it makes no improvements to overall accuracy.
- Fully-Connected Layers: The VGGNet has three fully connected layers. Out of the three layers, the first two have 4096 channels each, and the third has 1000 channels, 1 for each class.
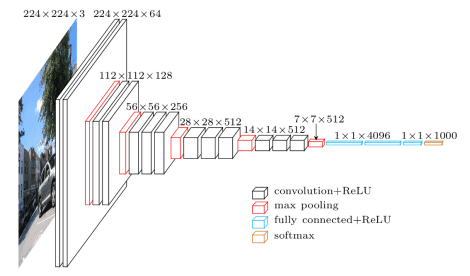
VGG16 Architecture
The number 16 in the name VGG refers to the fact that it is a 16-layer deep neural network (VGGnet). This means that VGG16 is a pretty extensive network and has a total of around 138 million parameters. Even according to modern standards, it is a huge network. However, VGGNet16 architecture’s simplicity is what makes the network more appealing. Just by looking at its architecture, it can be said that it is quite uniform.
There are a few convolution layers followed by a pooling layer that reduces the height and the width. If we look at the number of filters that we can use, around 64 filters are available that we can double to about 128 and then to 256 filters. In the last layers, we can use 512 filters.
Complexity and Challenges of VGG
The number of filters we can use doubles on every step or through every stack of the convolution layer. This is a major principle used to design the architecture of the VGG16 network. One of the crucial downsides of the VGG16 network is that it is a huge network, which means that it takes more time to train its parameters.
Because of its depth and number of fully connected layers, the VGG16 model is more than 533 MB. This makes implementing a VGG network a time-consuming task.
The VGG16 model is used in several deep learning image classification problems, but smaller network architectures such as GoogLeNet and SqueezeNet are often preferable. In any case, the VGGNet is a great building block for learning purposes as it is straightforward to implement.
Performance of VGG Models
VGG16 highly surpasses the previous versions of models in the ILSVRC-2012 and ILSVRC-2013 competitions. Moreover, the VGG16 result is competing for the classification task winner (GoogLeNet with 6.7% error) and considerably outperforms the ILSVRC-2013 winning submission, Clarifai. It obtained 11.2% with external training data and around 11.7% without it. In terms of the single-net performance, the VGGNet-16 model achieves the best result with about 7.0% test error, thereby surpassing a single GoogLeNet by around 0.9%.
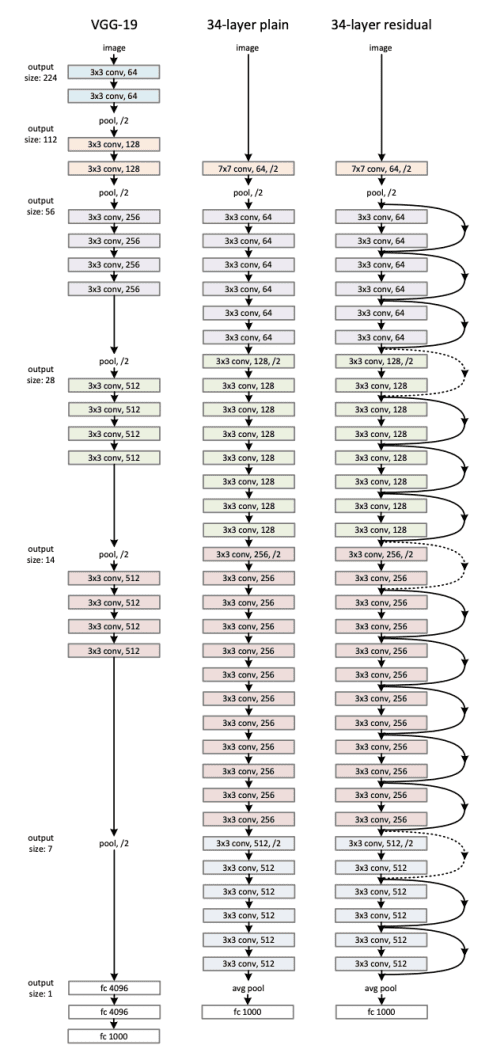
VGGNet vs. ResNet
VGG stands for Visual Geometry Group and consists of blocks, where each block is composed of 2D Convolution and Max Pooling layers. It comes in two models — VGG16 and VGG19 — with 16 and 19 weight layers.
As the number of layers increases in CNN, the ability of the model to fit more complex functions also increases. Hence, more layers promise better performance. This should not be confused with an Artificial Neural Network (ANN), where an increase in the number of layers doesn’t necessarily result in a better performance.
Now the question is, why shouldn’t you use a VGGNet with more layers, such as VGG20, VGG50, or VGG100? This is where the problem arises. The weights of a neural network are updated through the backpropagation algorithm, which makes a minor change to each weight so that the loss of the model decreases.
But how does it occur? It updates each weight so that it takes a step in the direction along which the loss decreases. This is nothing but the gradient of this weight, which can be found using the chain rule.
However, as the gradient keeps flowing backward to the initial layers, the value keeps increasing with each local gradient. This results in the gradient becoming smaller and smaller, thereby making changes to the initial layers very small. This, in turn, increases the training time significantly.
How to Solve?
The problem can be solved if the local gradient becomes 1. This is where ResNet comes into the picture since it achieves this through the identity function. So, as the gradient is back-propagated, it does not decrease in value because the local gradient is 1.
Deep residual networks (ResNets), such as the popular ResNet-50 model, are another type of convolutional neural network architecture (CNN) that is 50 layers deep. A residual neural network uses the insertion of shortcut connections to turn a plain network into its residual network counterpart. Compared to VGGNets, ResNets are less complex since they have fewer filters.
ResNet also referred to as Residual Network, does not allow the vanishing gradient problem to occur. The skip connections act as gradient superhighways, which allow the gradient to flow undisturbed. This is also one of the most important reasons why ResNet comes in versions like ResNet50, ResNet101, and ResNet152.
Implementing VGG Convolutional Network
Read more about related topics in deep learning and using VGGNet models in practical applications of computer vision and image recognition:
- TensorFlow Lite: Real-Time Computer Vision on Edge Devices
- Edge Intelligence: Deep Learning And Edge Computing
- AGI Meaning AI: What are the Different Types of AI?
- Automatic Number Plate Recognition: Building Real-World Computer Vision Apps
- OpenPose: An Open-Source Model for Pose Estimation