
Object detection is one of the crucial tasks in Computer Vision (CV). The YOLOv6 model localizes a section within an image and classifies the marked region within a predefined category. The output of the object detection is typically a bounding box and a label.
Computer vision researchers introduced the YOLO architecture (You Only Look Once) as an object-detection algorithm in 2015. It was a single-pass algorithm having only one neural network to predict bounding boxes and class probabilities using a full image as input.

An Intro to YOLOv6
In September 2022, C. Li, L. Li, H. Jiang, et al. (Meituan Inc.) published the YOLOv6 paper. Their goal was to create a single-stage object-detection model for industry applications.
They introduced quantization methods to boost inference speed without performance degradation, including Post-Training Quantization (PTQ) and Quantization-Awareness Training (QAT). These methods were utilized in YOLOv6 to achieve the goal of deployment-ready networks.
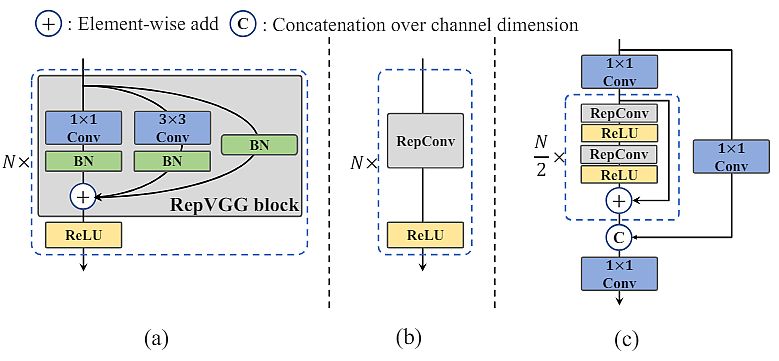
The researchers designed an efficient reparameterizable backbone denoted as EfficientRep. For small models, the main component of the backbone is RepBlock during the training phase. During the inference phase, they converted each RepBlock to 3×3 convolutional layers (RepConv) with ReLU activation functions.
Version History
Here is a rundown of the YOLO models released prior to YOLOv6.
| Release | Authors | Tasks | Paper | |
|---|---|---|---|---|
| YOLO | 2015 | Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi | Object Detection, Basic Classification | You Only Look Once: Unified, Real-Time Object Detection |
| YOLOv2 | 2016 | Joseph Redmon, Ali Farhadi | Object Detection, Improved Classification | YOLO9000: Better, Faster, Stronger |
| YOLOv3 | 2018 | Joseph Redmon, Ali Farhadi | Object Detection, Multi-scale Detection | YOLOv3: An Incremental Improvement |
| YOLOv4 | 2020 | Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao | Object Detection, Basic Object Tracking | YOLOv4: Optimal Speed and Accuracy of Object Detection |
| YOLOv5 | 2020 | Ultralytics | Object Detection, Basic Instance Segmentation (via custom modifications) | no |
YOLOv6 Architecture
YOLOv6 architecture is composed of the following parts: a backbone, a neck, and a head. The backbone mainly determines the feature representation ability. Additionally, its design has a critical influence on the run inference efficiency since it carries a large portion of the computational cost.
The neck’s purpose is to aggregate the low-level physical features with high-level semantic features and build up pyramid feature maps at all levels. The head consists of several convolutional layers and predicts final detection results according to multi-level features assembled by the neck.
Moreover, its structure is anchor-based and anchor-free, or parameter-coupled head and parameter-decoupled head.
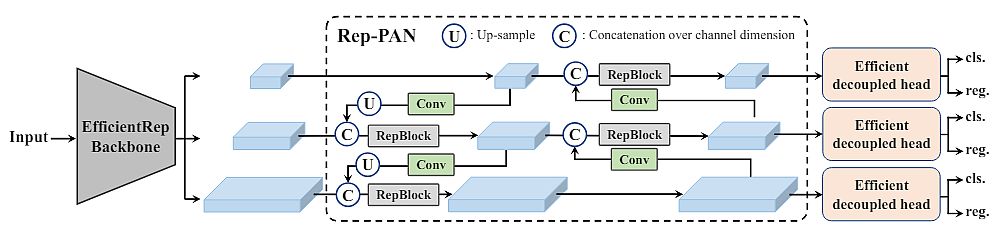
Based on the principle of hardware-friendly network design, researchers proposed two scaled, re-parameterizable backbones and necks to accommodate models of different sizes. Also, they introduced an efficient decoupled head with the hybrid-channel strategy. The overall architecture of YOLOv6 is shown in the figure above.
YOLOv6 Performance
Researchers used the same optimizer and learning schedule as YOLOv5, i.e. Stochastic Gradient Descent (SGD) with momentum and cosine decay on the learning rate. Also, they utilized a warm-up, grouped weight decay strategy, and the Exponential Moving Average (EMA).
They adopted two strong data augmentations (Mosaic and Mixup) following previous YOLO versions. A complete list of hyperparameter settings is located in GitHub. They trained the model on the COCO 2017 training set and evaluated the accuracy of the COCO 2017 validation set.
The researchers utilized eight NVIDIA A100 GPUs for training. In addition, they measured the speed performance of an NVIDIA Tesla T4 GPU with TensorRT version 7.2.
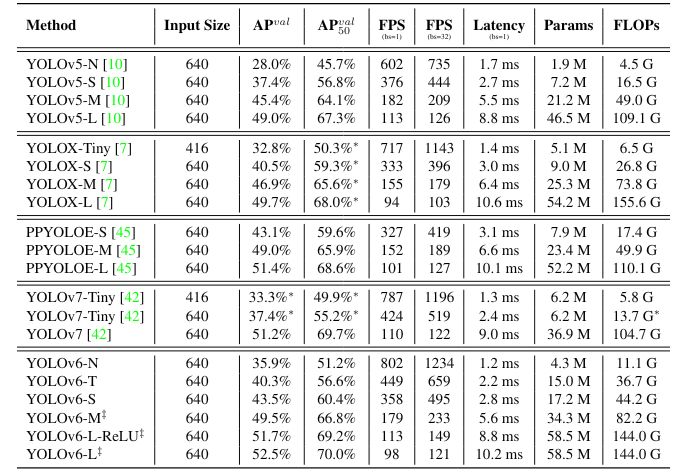
- The developed YOLOv6-N achieves 35.9% AP on the COCO dataset at a throughput of 1234 FPS on an NVIDIA Tesla T4 GPU.
- YOLOv6-S strikes 43.5% AP at 495 FPS, outperforming other mainstream detectors at the same scale (YOLOv5-S, YOLOX-S, and PPYOLOE-S).
- The quantized version of YOLOv6-S even brings a new state-of-the-art 43.3% AP at 869 FPS.
- Furthermore, YOLOv6-M/L achieves better accuracy performance (i.e., 49.5%/52.3%) than other detectors with similar inference speeds.
Industry-Related Improvements
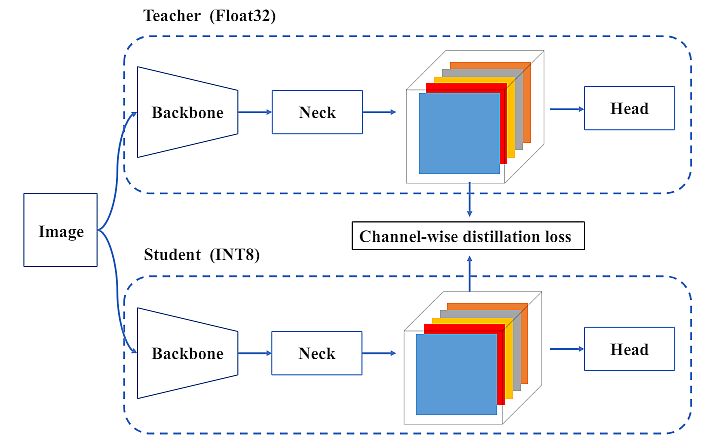
The authors introduced additional common practices and tricks to improve the performance, including self-distillation and more training epochs.
- For self-distillation, they used the teacher model to supervise both classification and box regression loss. They implemented the distillation of box regression using DFL (device-free localization).
- In addition, the proportion of information from the soft and hard labels dynamically declined via cosine decay. This helped them selectively acquire knowledge at different phases during the training process.
- Moreover, they encountered the problem of impaired performance without adding extra gray borders at evaluation, for which they provided some remedies.
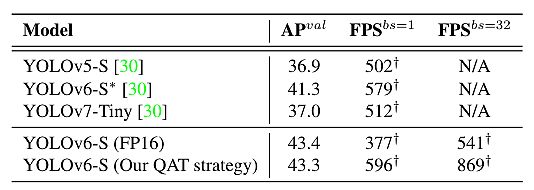
Quantization Results
For industrial deployment, it has been a common practice to apply quantization to further speed up. Also, quantization will not compromise the model’s performance. Post Training Quantization (PTQ) directly quantizes the model with only a small calibration set.
Whereas Quantization Aware Training (QAT) further improves the performance with access to the training set, it is typically used jointly with distillation. However, due to the heavy use of re-parameterization blocks in YOLOv6, previous PTQ techniques fail to produce high performance.
Because of the removal of quantization-sensitive layers in the v2.0 release, researchers directly used full QAT on YOLOv6-S trained with RepOptimizer. Therefore, it was hard to incorporate QAT when it came to matching fake quantizers during training and inference.
Researchers eliminated inserted quantizers through graph optimization to obtain higher accuracy and faster speed. Finally, they compared the distillation-based quantization results from PaddleSlim (table below).
The Latest YOLOv6 Updates
In this latest release, the researchers renovated the network design and the training strategy. They showed the comparison of YOLOv6 with other models at a similar scale in the figure below. The new features of YOLOv6 include the following:
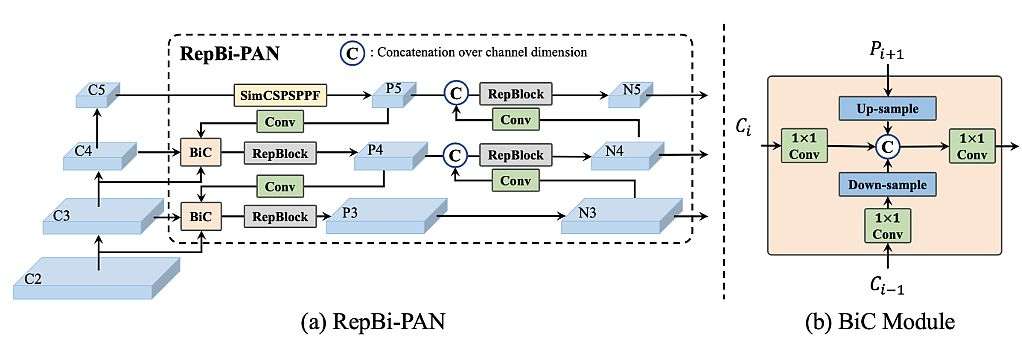
- They renewed the neck of the detector with a Bi-directional Concatenation (BiC) module to provide more accurate localization signals. SPPF was simplified to form the SimCSPSPPF Block, which brings performance gains with negligible speed degradation.
- They proposed an anchor-aided training (AAT) strategy to enjoy the advantages of both anchor-based and anchor-free paradigms without touching inference efficiency.
- They deepened YOLOv6 to have another stage in the backbone and the neck. Therefore, it achieved a new state-of-the-art performance on the COCO dataset at a high-resolution input.
- They involved a new self-distillation strategy to boost the performance of small models of YOLOv6, in which the heavier branch for DFL is taken as an enhanced auxiliary regression branch during training and is removed at inference to avoid the marked speed decline.
Researchers applied feature integration at multiple scales as a critical and effective component of object detection. They used a Feature Pyramid Network (FPN) to aggregate the high-level semantic and low-level features via a top-down pathway, providing more accurate localization.
Further Enhancements
Subsequently, other works on Bi-directional FPN enhance the ability of hierarchical feature representation. PANet (Path Aggregation Network) adds an extra bottom-up pathway on top of FPN to shorten the information path of low-level and top-level features. That facilitates the propagation of accurate signals from low-level features.
BiFPN introduces learnable weights for different input features and simplifies PAN to achieve better performance with high efficiency. They proposed PRB-FPN to retain high-quality features for accurate localization by a parallel FP structure with bi-directional fusion and associated improvements.
Final Thoughts on YOLOv6
The YOLO models are the standard in object detection methods with their great performance and wide applicability. Here are the conclusions about YOLOv6:
- Usage: YOLOv6 is already in GitHub, so the users can implement YOLOv6 quickly through the CLI and Python IDE.
- YOLOv6 tasks: With real-time object detection and improved accuracy and speed, YOLOv6 is very efficient for industry applications.
- YOLOv6 contributions: YOLOv6’s main contribution is that it eliminates inserted quantizers through graph optimization to obtain higher accuracy and faster speed.
Here are some related articles for your reading:
- Learn about Edge Intelligence: Edge Computing and ML
- What are Capsule Networks?
- Recent release of YOLOv10: Real-Time Object Detection Evolved