Since the introduction of GANs (Generative Adversarial Networks) by Goodfellow and his colleagues in 2014, they have revolutionized generative models and have been useful in various fields for image generation, creating synthetic faces and data.
Moreover, beyond image generation, GANs have been used extensively in a variety of tasks such as image-to-image translation (using CycleGAN), super-resolution, text-to-image synthesis, drug discovery, and protein folding.
Image-to-image translation is an area of computer vision that deals with transforming one image to another form while maintaining certain semantic details (e.g. translating the image of a horse into a zebra). CycleGAN is specifically designed to handle this task, where it can perform style transfer, image colorization, converting painting to real image and real image back to painting.
In this blog post, we will look into CycleGAN and how it performs image to image, how it transformed this area of research, and what makes it better than previous models.

What is a GAN?
GAN is a deep learning architecture consisting of two neural networks, a generator and a discriminator, that are trained simultaneously through adversarial learning, which is like a game, where the generator and discriminator try to beat each other.
The goal of the generator is to produce realistic images from random noise that are indistinguishable from real images, while the discriminator attempts to distinguish whether the images are real or synthetically generated. This game continues until the generator learns to generate images that fool the discriminator.
Image-to-Image Translation Tasks
This task involves converting an image from one domain to another. For example, if you trained an ML model on a painting from Picasso, it can convert a normal painting into something that Pablo Picasso would like to paint. When you train a model like CycleGAN, it learns the key features and stylistic elements of the painting and then can be replicated in a normal painting.
Image to Image translation models can be divided into two, based on the training data they use:
- Paired dataset
- Unpaired dataset
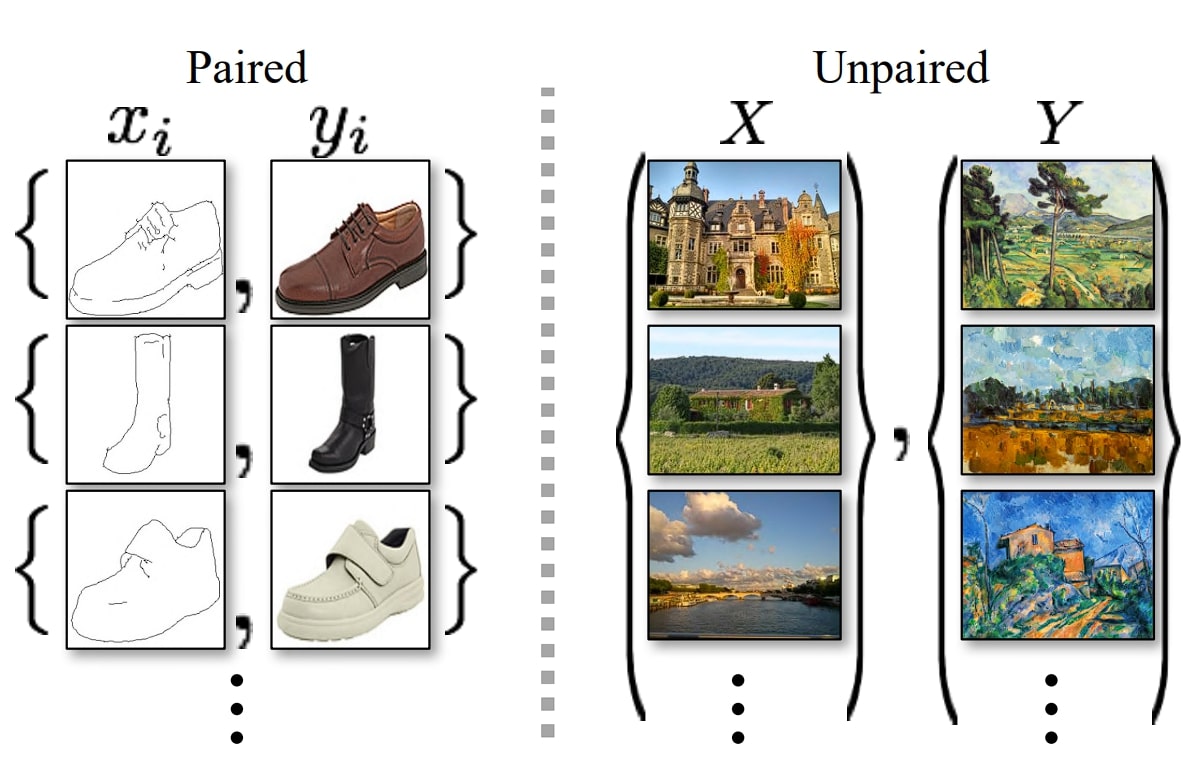
Paired Image Datasets
In paired image datasets, each image in one domain has a corresponding image in the other domain. For example, if you are to convert an image from summer to winter, then these need to be provided in paired form (the before and after images).
This is a task of supervised learning where the model learns a direct mapping from the input image to the output image.
Pix2Pix is one such model that uses paired datasets and can convert sketches into photographs, daytime to night-time photos, and maps to satellite images.
However, such models have a big drawback. Creating paired datasets is difficult, expensive, and sometimes impossible. But such models also have its advantages:
- Direct Supervision: Paired datasets provide direct guidance on how it translate images.
- Higher Quality Outputs: As a result, it generates higher image quality and better results.
Unpaired Image Datasets
In unpaired image datasets, there is no pairing required between images from different domains, and as a result, it is a form of unsupervised learning. Such models are easier to train as unpaired datasets are easier to collect and provide more flexibility since in the real world it is not always possible to get paired images.
CycleGAN is one such model that excels at this task. It can do everything a paired dataset model can do such as converting artwork, creating Google Maps images from satellite images, etc. One major disadvantage of such models is that they are complex.
What is CycleGAN? (CycleGAN Explained)
CycleGAN, short for Cycle-Consistent Generative Adversarial Network, is a type of Generative Adversarial Network (GAN) for unpaired image-to-image translation.
As we discussed above, paired dataset models have a major drawback that you need to have before and after images in pairs, which is not very easy to do. For example, if you want to convert summer photos into winter photos, you need to have them sorted out in pairs
However, CycleGAN overcomes this limitation and provides image-to-image translation without the need for a paired dataset.
The key innovation of CycleGAN in comparison to standard GAN models like Pix2Pix lies in its cycle-consistency loss. Standard GANs learn a direct mapping between the input and output domains. This works well for tasks with clear and consistent correspondences but struggle with tasks where such correspondences are ambiguous or nonexistent.
The key idea in CycleGAN and cycle consistency loss functions is to convert an image from domain A to domain B, and then back from domain B to domain A. The reversed image should resemble the original image. This cycle-consistency mechanism allows the model to learn meaningful mappings and semantic details between domains without the need for direct pairings.

Here is what you can do with CycleGAN:
- Artistic Style Transfer: Automatically convert photos into artistic styles, such as turning a photograph into a painting or vice versa.
- Domain Adaptation: Translate images from one domain to another, for instance, converting day-time photos to night-time photos or winter photos to summer photos.
- Medical Imaging: Translate images from different medical imaging, such as converting MRI scans to CT scans.
- Data Augmentation: Generate new training samples by translating images from one domain to another.

CycleGAN Architecture
CycleGAN is composed of four main components: two generators and two discriminators. These components work together with adversarial loss and cycle consistency loss to perform image translation using unpaired image datasets.
While there are several architectures present, the Generator and Discriminator can be made from various methods such as the Attention mechanism, and U-Net. However, the core concept of CycleGANs remains the same. Therefore, it is safe to say that CycleGAN is a way of performing image translations rather than a distinct architecture model.
Moreover, in the original published paper in 2017, the network contains convolution layers with several residual blocks, inspired by the paper published by Justin Johnson and Co. on Perceptual Losses for Real-Time Style Transfer and Super-Resolution. Read here for more.
Let us look at the core workings of CycleGAN.
Generators
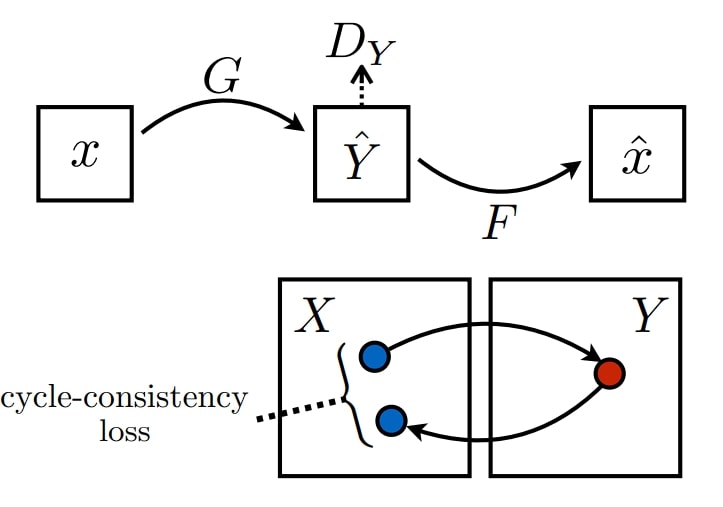
The CycleGAN models use two generators, G and F. G translates images from domain X to domain Y (e.g., horse to zebra), and F translates the images back from domain Y to domain X (e.g., zebra to horse). This is what forms a cycle.
- Domain- X (horse) -> Generator-G -> Domain-Y (zebra)
- Domain-Y (zebra)-> Generator-F -> Domain-X (horse)
Discriminators
There are two discriminators, DX and DY, one for each generator. DX differentiates between real images from domain X and fake images generated by F. DY differentiates between real images from domain Y and fake images generated by G.
Domain-X (horse) -> Generator-G (zebra) -> Discriminator- DX -> [Real/Fake]
Domain-Y (zebra) -> Generator-F (horse) -> Discriminator- DY -> [Real/Fake]
The discriminator and generator models are trained in a typical adversarial zero-sum process, just like normal GAN models. The generators learn to fool the discriminators better and the discriminator learns to better detect fake images.
Adversarial Loss
The adversarial loss is a crucial component of CycleGAN and any other GAN model, driving the generators and discriminators to improve through competition.
- Generator Loss: The generator aims to fool the discriminator by generating realistic images. The generator’s loss measures the success of fooling the discriminator.
- Discriminator Loss: The discriminator aims to classify real images and generate images correctly. The discriminator’s loss measures its ability to distinguish between the two.
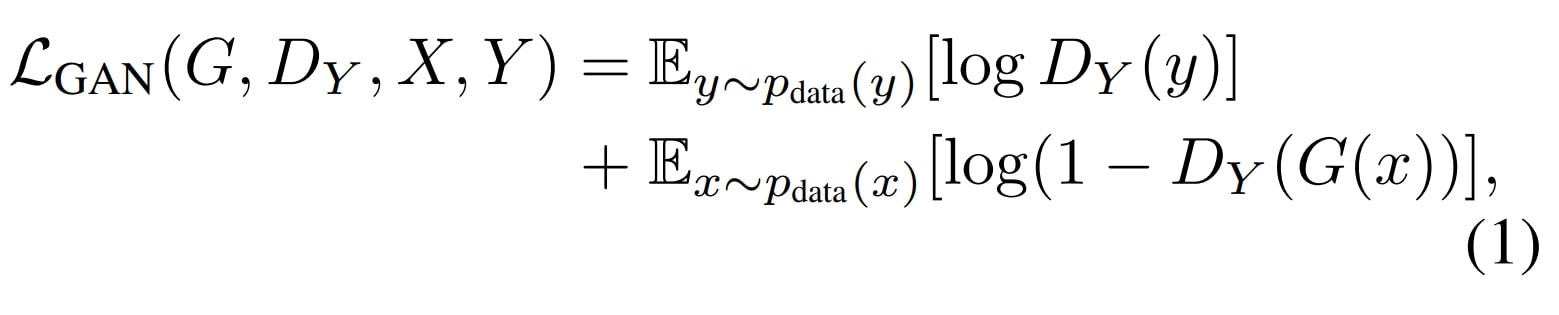
Cycle Consistency Loss
The cycle consistency loss is the most important part of CycleGAN, as it ensures that an image from one domain when translated to the other domain and back, should look like the original image.
This loss is important for maintaining the integrity of the images and enabling the unpaired image-to-image translation using cycle-consistent adversarial networks.
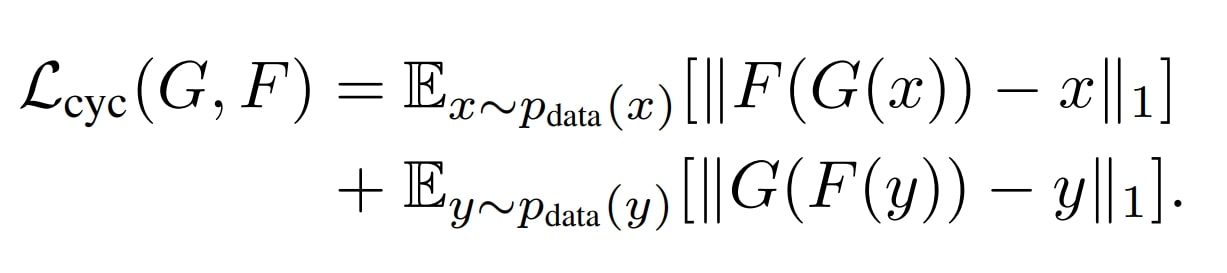
Importance of Cycle Consistency Loss in CycleGAN
Cycle Consistency Loss is what makes CycleGAN special. By just using adversarial loss alone, the GAN can generate an infinite number of scenarios where the discriminator could be fooled.
But when we use Cycle loss, the model gets a sense of direction, as the infinite possibilities (useless) previously are turned into a specific set of possibilities (useful).
- The cycle consistency loss ensures that an image from one domain, when translated to the other domain and then back, is similar to the original image. Using this loss makes the model preserve the underlying structure and content of the image and learn useful semantic representation and not output random images.
- Without this loss, the generators will produce arbitrary transformations (that fool the discriminator) and don’t contain any useful features learned, leading to unrealistic or meaningless results.
- Mode collapse is another problem that the GAN model will face (a common problem in GANs where the generator produces a limited variety of output) without the cycle loss.
Moreover, the cycle consistency loss is what provides CycleGAN with a self-supervised signal, guiding the training process even in the absence of paired data.
For example, without cycle consistency loss, the translation from horse to zebra might produce an image that looks like a zebra but has lost the specific features of the horse (e.g., pose, background). The reverse translation from zebra to horse will then produce a horse image that looks very different from the original horse, with a different pose or background.
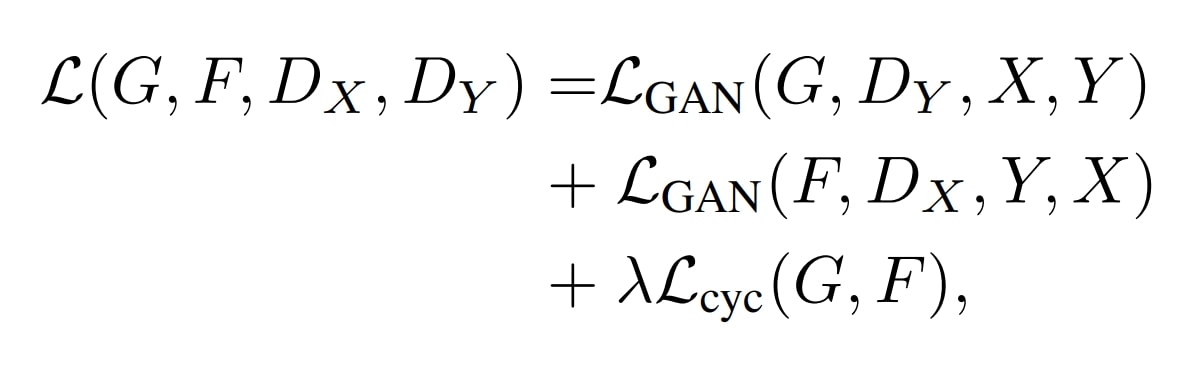
Variants and Improvements
Since the introduction of CycleGAN, several architectures have been introduced that use a variety of techniques to improve the performance of the model. Moreover, as said above cycleGAN is a method and not a discrete architecture, therefore it provides great flexibility.
Here are some versions of CycleGAN.
Mask CycleGAN
The generator in Mask CycleGAN added a masking network in comparison to standard CycleGAN.
This network generates masks that identify regions of the image that need to be altered or transformed. The masks help in focusing the generative process on specific areas, leading to more precise and realistic transformations.
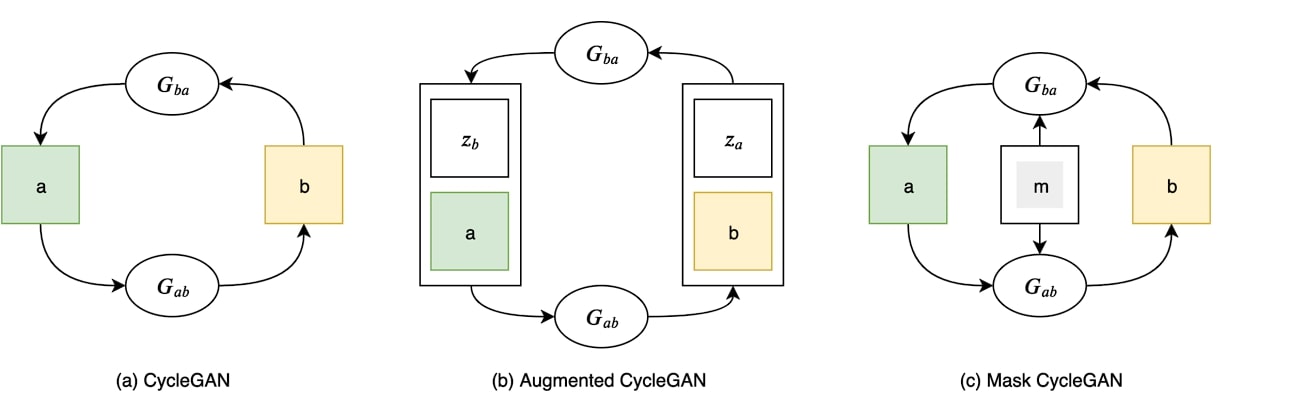
Moreover, mask CycleGAN combines traditional CycleGAN loss with an additional mask loss and identity loss. This ensures the generated masks focus on relevant regions.
This network has several uses, as the masks allow the network to perform transformations on specific regions. This leads to more controlled and accurate results. It can be used for:
- Transforming objects within images while keeping the background unchanged, such as changing the color of a car without affecting the surroundings.
- Image Inpainting: For example, filling in missing parts of an image or removing unwanted objects.
- Altering facial attributes like age, expression, or hairstyle.
- Enhancing or transforming specific regions in medical images, such as highlighting tumors or lesions in MRI scans.
Transformer-based CycleGAN
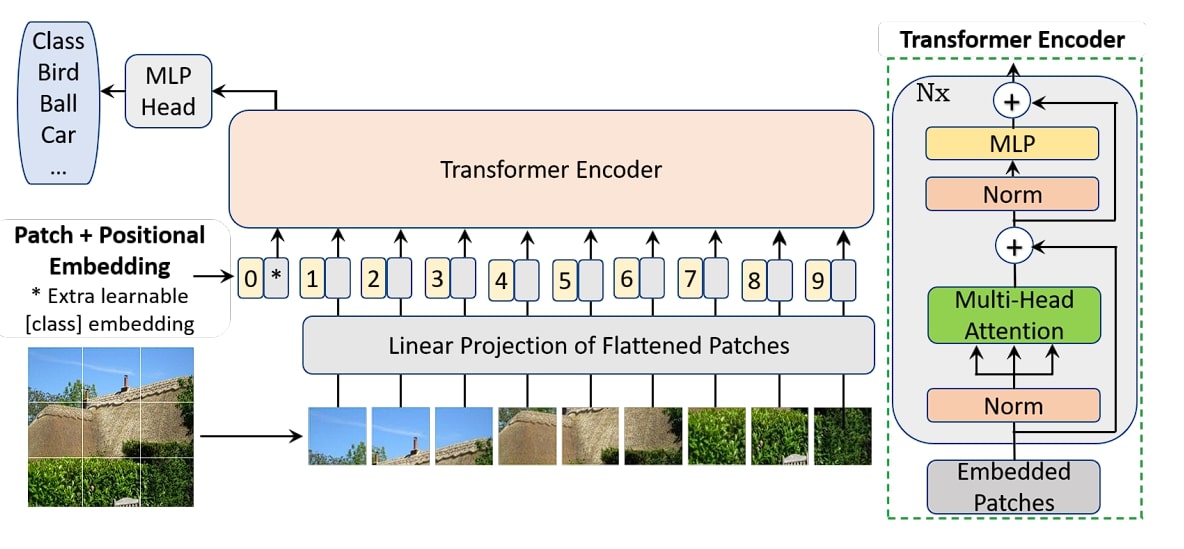
This version of CycleGAN utilizes transformer networks instead of Convolutional Neural Networks (CNNs) in the generator. The generator network of CycleGAN is replaced by a Vision Transformer. This difference in this model gives the ability to handle image context and long-range dependencies.
Examining CycleGAN and Generative AI Further
In this blog, we looked at CycleGAN, a GAN-based model, that enables image-to-image translation without paired training data. The architecture consists of two generators and two discriminators that are guided by adversarial and cycle loss.
We then looked at the core working of CycleGAN, that is it generates an image for target domain B from domain A, then tries to bring the original image as accurately as possible. This process allows CycleGAN to learn the key features of the generated image. Moreover, we also looked at what we could do with the model, such as converting Google Maps images to satellite images and vice versa or creating a painting from the original image.
Finally, we looked at the variants of CycleGAN, mask cycle GAN, and transformer-based CycleGAN, and how they differ from the original proposed model.
please provide a valid slug