
The rise of computer vision is largely based on the success of deep learning methods that use Convolutional Neural Networks (CNN). However, these neural networks are heavily reliant on a lot of training data to avoid overfitting and poor model performance. Unfortunately, in many cases, such as real-world applications, there is limited data available, and gathering enough training data is very challenging and expensive.
What Is Data Augmentation?
Data augmentation is a set of techniques that enhance the size and quality of machine learning training datasets so that better deep learning models can be trained with them.
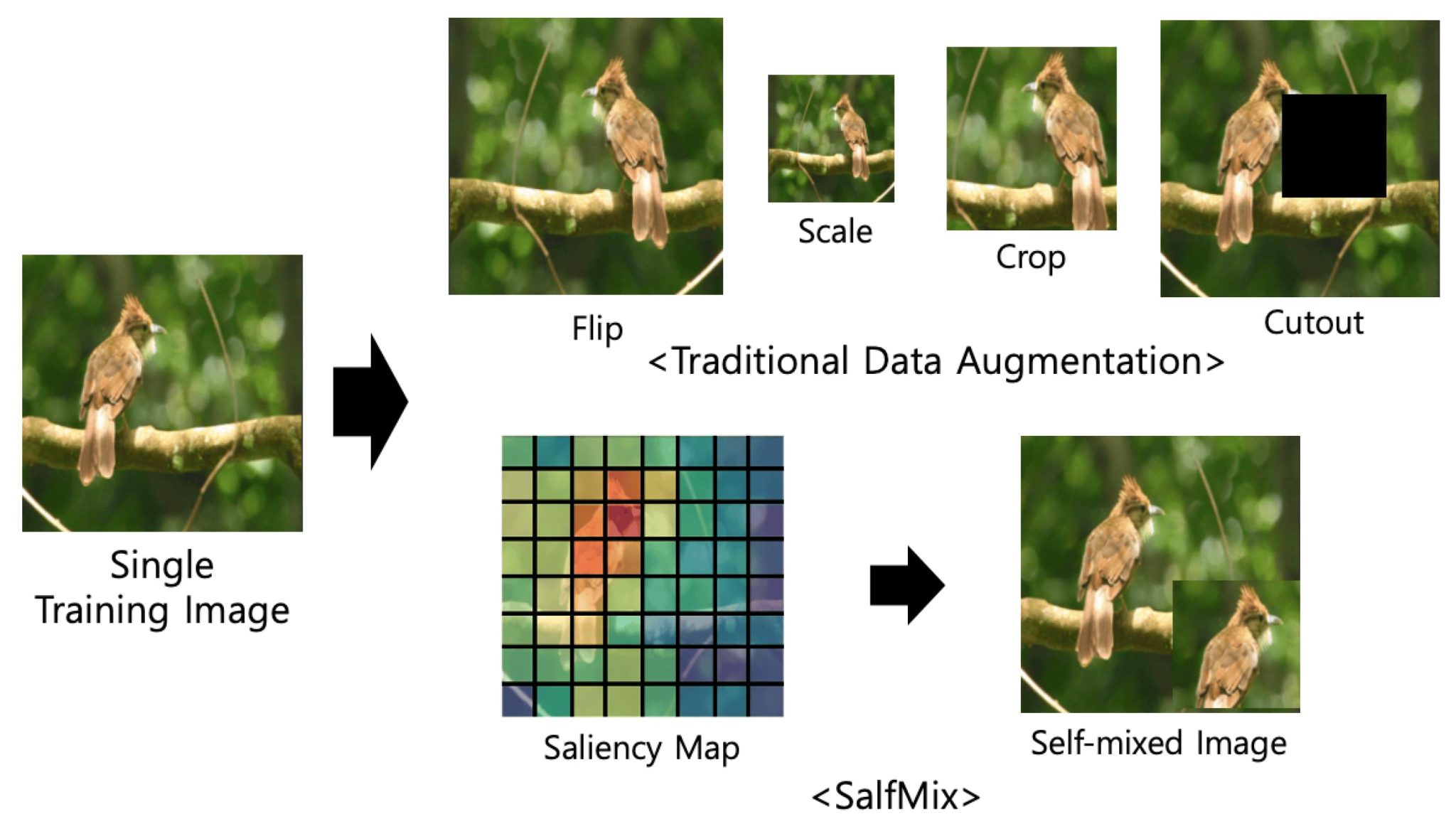
Popular Techniques
Image augmentation algorithms include geometric transformations, color space augmentation, kernel filtering, mixing images, random erasing, feature space augmentation, adversarial training, generative adversarial networks (GAN), meta-learning, and neural style transferring.
Importance of Data Augmentation
Reduction of Overfitting
The recent advances in deep learning technology have been driven by the advancement of deep network architectures, powerful computation, and access to big data. Deep convolutional neural networks (CNNs) have achieved great success in many computer vision tasks such as image classification, object detection, and image segmentation.
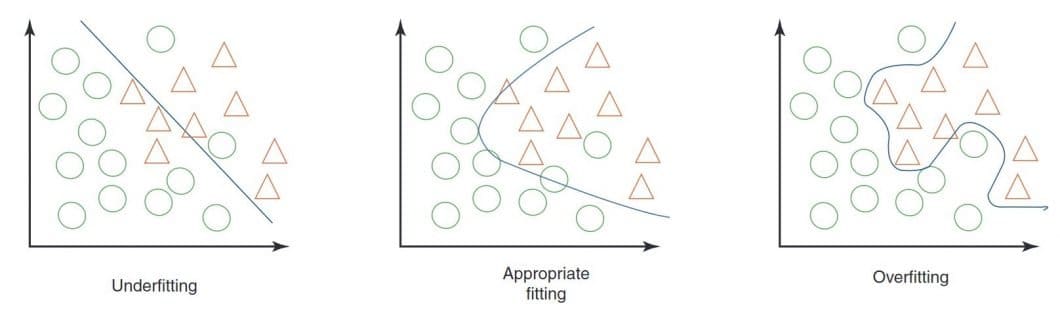
One of the most difficult challenges is the generalizability of deep learning models that describe the performance difference of a model when evaluated on previously seen data (training data) versus data it has never seen before (testing data). Models with poor generalizability have overfitted the training data (Overfitting).
To build useful deep learning models, Data Augmentation is a very powerful method to reduce overfitting by providing a more comprehensive set of possible data points to minimize the distance between the training and testing sets.
Artificial Inflation of the Original Dataset
Data Augmentation approaches overfitting from the root of the problem, the training dataset. The underlying idea is that more information can be gained from the original image dataset through the creation of augmentations.
These augmentations artificially inflate the training dataset size by data warping or oversampling.
- Data warping augmentations transform existing images while preserving their label (annotated information). This includes augmentations such as geometric and color transformations, random erasing, adversarial training, and neural style transfer.
- Oversampling augmentations create synthetic data instances and add them to the training set. This includes mixing images, feature space augmentations, and generative adversarial networks (GANs).
- Combined approaches: Those methods can be applied in combination, for example, GAN samples can be stacked with random cropping to further inflate the dataset.

Superiority of Larger Datasets
In general, bigger datasets result in better deep learning model performance. However, assembling very large datasets can be very difficult and requires an enormous manual effort to collect and label image data.
The challenge of small, limited datasets with few data points is especially common in real-life applications, for example, in medical image analysis in healthcare or industrial manufacturing. With big data, convolutional networks have shown to be very powerful for medical image analysis tasks such as brain scan analysis or skin lesion classification.

However, data collection for computer vision training is expensive and labor-intensive. It’s especially challenging to build big image datasets due to the rarity of events, privacy, the requirements of industry experts for labeling, and the expense and manual effort needed to record visual data. These obstacles are the reason why image data augmentation has become an important research field.
Challenges of Data Collection for Augmentation
Data collection is needed where public computer vision datasets are not sufficient. The computer vision community has created huge datasets such as PASCAL VOC, MS COCO, NYU-Depth V2, and SUN RGB-D with millions of annotated data points. However, those cannot cover all the scenarios, especially not for purpose-built computer vision applications.
There are several problems with data collection:
- Applications require more data: Real-world computer vision applications involve highly complex computer vision tasks that require increasingly complex models, datasets, and labels
- Limited availability of data: As tasks become more complex and the range of possible variations expands, the requirements of data collection become more challenging. Some scenarios may rarely occur in the real world, yet correctly handling these events is critical.
- Data collection is difficult: The process of generating high-quality training data is difficult and expensive. Recording image or video data requires a combination of workflows, software tools, cameras, and computing hardware. Depending on the applications, it requires domain experts to gather useful training data.
- Increasing costs: Image annotation requires expensive human labor to create the ground-truth data for model training. The cost of annotating increases with the task complexity, and shifts from labeling frames to labeling objects, keypoints, and even pixels in the image. This, in turn, drives the need to review or audit annotations, leading to additional costs for each labeled image.
- Data Privacy: Privacy in computer vision is becoming a key issue and further complicating data collection. Consumer data usage to train machine learning models is limited by regulations such as the EU General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA). The extent to which real-world data can be gathered is limited, driving the need for training deep learning models on smaller datasets.

These challenges drive the need for data augmentation in computer vision, and to achieve sufficient model performance and optimize computer vision costs in challenging tasks such as video and image recognition.
Challeges of Image Recognition
In classic recognition tasks, the image recognition software must overcome issues of lighting, occlusion (partially hidden objects), background, scale, angle, and more. The task of data augmentation is to create instances of these translational invariances and add them to the dataset so that the resulting model will perform well despite these challenges.
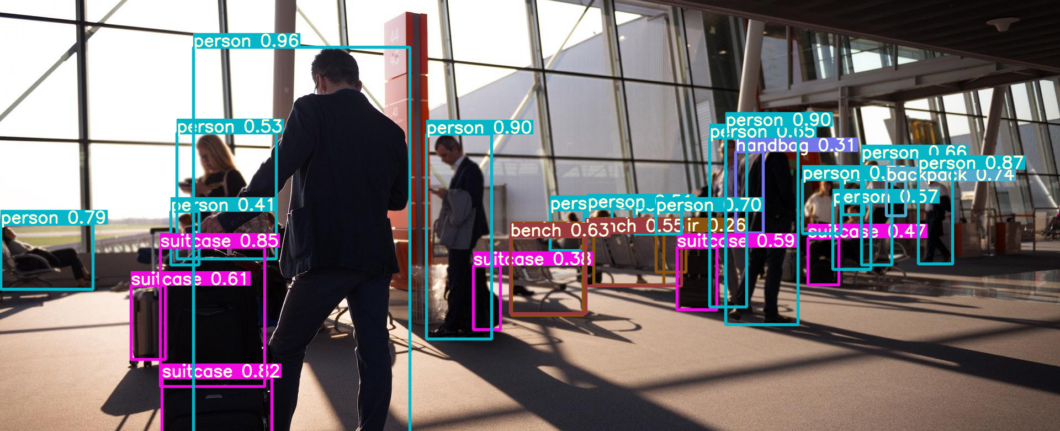
Cutting-edge algorithms like the Segment Anything Model (SAM) from Meta AI introduced a new method for recognizing objects and images without additional training, using a zero-shot generalization segmentation system. This makes it possible to cut out any object in any image, and do so with a single click.

Popular Methods
Early experiments showing the effectiveness of data augmentations come from simple image transformations. For example, horizontal flipping, color space augmentations, and random cropping. Such transformations encode many of the invariances that present challenges to image recognition tasks.

There are different methods for image data augmentation:
- Geometric transformations: Augmenting image data using flipping horizontally or vertically, random cropping, rotation augmentation, translation to shift images left/right/up/down, or noise injection.
- Color distortion contains changing brightness, hue, or saturation of images. Altering the color distribution or manipulating the RGB color channel histogram is used to increase model resistance to lighting biases.
- Kernel filters use image processing techniques to sharpen and blur images. Those methods aim to increase details about objects of interest or to improve motion blur resistance.
- Mixing images applies techniques to blend different images by averaging their pixel values for each RGB channel, or with random image cropping and patching. While counterintuitive to humans, the method is effective in increasing model performance.
- Information deletion uses random erasing, cutout, and hide-and-seek methods to mask random image parts. Deleting a level of information increases occlusion resistance in image recognition, resulting in a notable increase in model robustness.
Applying Augmentations
In computer vision, deep artificial neural networks require a large collection of training data to effectively learn. However, the collection of such training data is expensive and laborious. Data augmentation overcomes this issue by artificially inflating the training set with label-preserving transformations. Recently, there has been extensive use of generic image data augmentation to improve Convolutional Neural Network (CNN) task performance.
Read more about related topics: