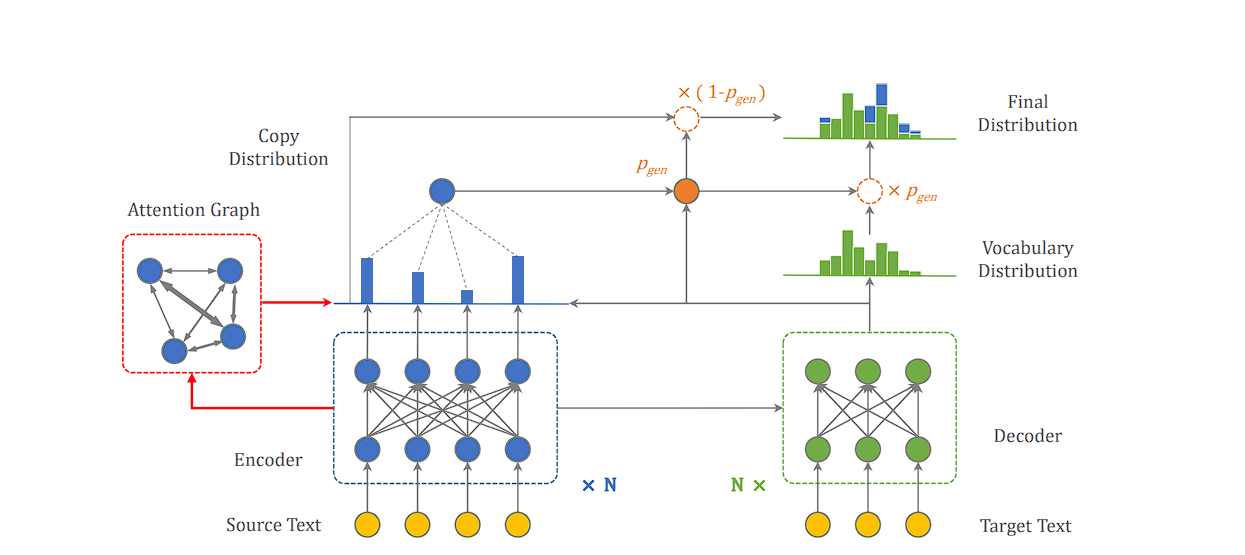
Attention mechanisms allow artificial intelligence (AI) models to dynamically focus on individual elements within visual data. This mimics the way humans concentrate on specific visual elements at a time. This enhances the interpretability of AI systems for applications in computer vision and natural language processing (NLP).
The introduction of the Transformer model was a significant leap forward for the concept of attention in deep learning. Vaswani et al. described this model in the seminal paper titled “Attention is All You Need” in 2017.
Uniquely, this model did not rely on conventional neural network architectures like convolutional or recurrent layers. without conventional neural networks. This represented a significant departure in how machine learning models process sequential data.
Addressing Data Processing
Attention mechanisms address a critical challenge in AI: the efficient processing of vast and complex data sets. By enabling models to selectively weigh the importance of different input features, they improve both accuracy and efficiency. This makes these models perform better for tasks such as image recognition, text translation, and speech recognition.
For instance, in computer vision, models with attention mechanisms can better understand scenes by focusing on relevant objects. This has positive implications for applications like autonomous vehicles and facial recognition systems.
Furthermore, attention mechanisms work to enhance the explainability or interpretability of AI models. This involves developing insights into which parts of the data the model considers most important. In a way, you can consider it offering a window into the “thought processes” of AI.
Types of Attention Mechanisms
Attention mechanisms are a vital cog in modern deep learning and computer vision models. The ability to focus and interpret specific elements in input data is important in many different applications. As a result, different types of attention mechanisms have emerged to better serve this wide array of use cases.
Content-based Attention
Content-based attention mechanisms are pivotal in tasks like machine translation and speech recognition. This model type is rooted in the principle of aligning model focus according to the relevance of input content. A seminal implementation is the Neural Machine Translation (NMT) system by Bahdanau et al. Using content-based attention, it focuses on relevant words to improve accuracy when translating to the target language.
This approach is widely adopted in both image recognition and natural language processing use cases. It improves the ability of models to focus on pertinent image regions and to handle long-range dependencies.
Location-based Attention
In contrast, location-based mechanisms prioritize the positional aspect of the input data. Typically, this is crucial for tasks requiring spatial awareness, like image captioning and object tracking. In these instances, the interpretation of spatial relations and the sequence of objects is vital to produce accurate output.
One of its benefits is empowering models to maintain a spatial map of input features. This enhances their ability to process sequences in tasks like robotic navigation and augmented reality applications.
Self-attention (Transformer models)
As mentioned, self-attention mechanisms in the “Attention Is All You Need” paper have revolutionized the field. Self-attention allows layers to weigh the importance of different parts of the input data independently.
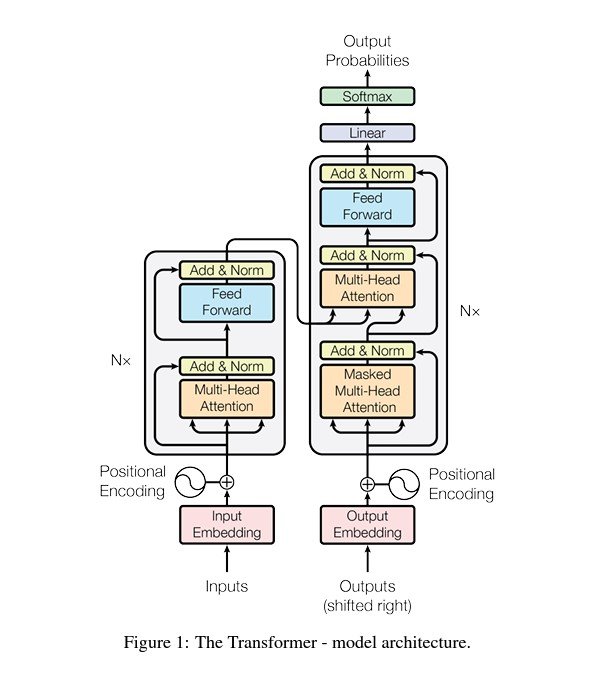
This has led to groundbreaking models like GPT for generative tasks and BERT for understanding context in Natural Language Processing (NLP). Vision Transformers (ViT) also adapt the Transformer model to achieve state-of-the-art results in image classification. It does this by applying self-attention to sequences of image patches.
Multi-head Attention
An extension of self-attention, multi-head attention processes the input data through multiple attention heads simultaneously. Each head attends to different parts of the input, allowing the model to capture a richer diversity of features.
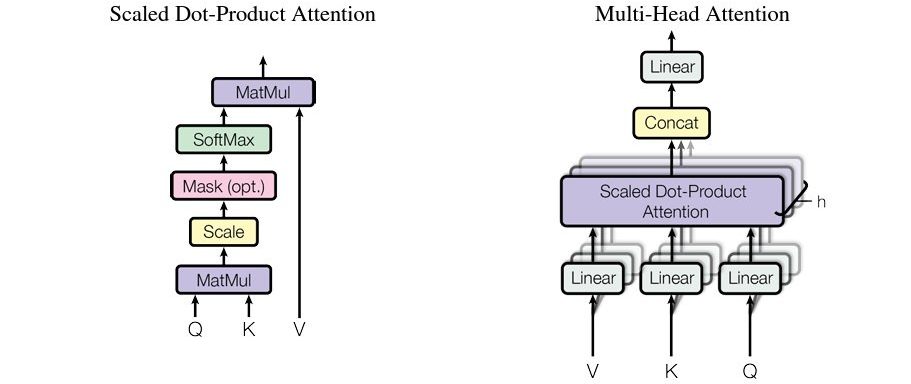
This architecture improves the model’s ability to discern subtle nuances in data. This often proves essential in complex tasks across various use cases, from language understanding to detailed image analysis.
Attention Mechanisms in Deep Learning
Attention mechanisms are helping reimagine both convolutional neural networks (CNNs) and sequence models. By integrating attention with CNNs, the networks can selectively focus on certain areas within an image or video frame. This leads to improved feature extraction by forming context vectors that are a weighted sum of the input data. This has immense potential for tasks that require object detection and fine-grained recognition, like Optical Character Recognition (OCR).
Sequence models, especially those based on recurrent neural networks (RNNs), leverage attention to manage long-term dependencies. These models can benefit from using attention weights to improve each step’s outputs. It effectively allows the model to ‘pay attention’ to particular segments of the input sequence. This is especially beneficial in NLP tasks like image captioning and video understanding.
Categorizations
- Additive Attention: Computes alignment scores using a feed-forward network with a single hidden layer. This assists models in focusing on different parts at different time steps.
- Dot-Product Attention: A faster variant that calculates scores based on the dot product of the query with the keys. The results are often scaled down to produce more stable gradients.
- Multi-Head Attention: Allows the model to jointly attend to information from different representation subspaces at different positions. In effect, increasing the capacity to learn from the input data.
Graph Attention Networks (GATs) improve how AI understands and uses data with interconnected points. You can think of this as social media users or cities on a map with connections between them. GATs pinpoint the most consequential connections by assigning a ‘score’ to each one based on its importance.
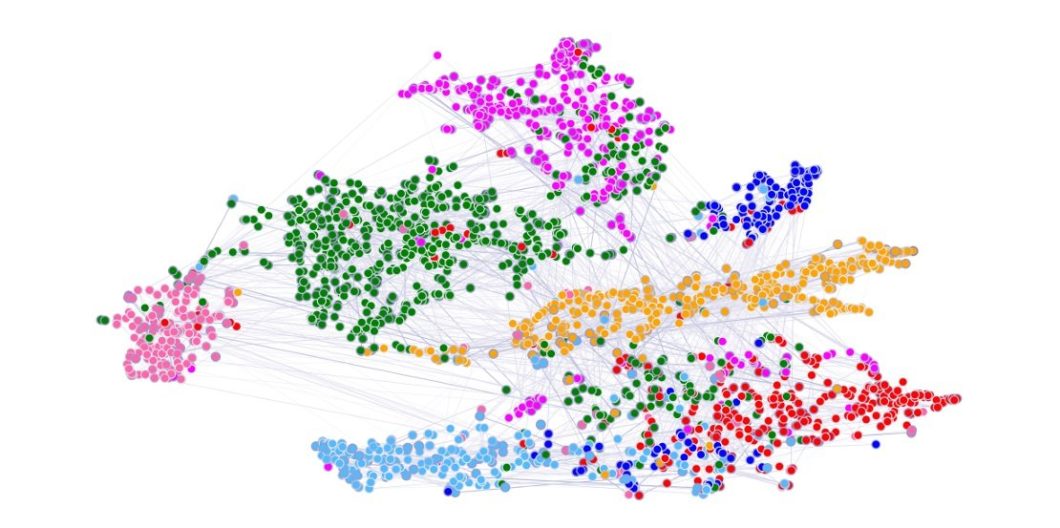
It’s similar to focusing on a friend in a crowded room; GATs focus on what’s important and tune out the rest. This approach helps GATs make better predictions and understand the data more effectively than older methods.
Each of these mechanisms relies on weight matrices to transform, score, and normalize attention across inputs. This is crucial for tasks like node classification and link prediction concerning graph data, for example.
Practical Applications of Attention in Computer Vision
Attention mechanisms are already a pivotal component in advancing computer vision tasks. They enable models to mimic a crucial human visual trait – focusing on the most informative parts of an image. In image classification, attention-based models allow the network to focus on salient features, significantly improving accuracy over traditional CNNs. Examples include the likes of the Residual Attention Network.
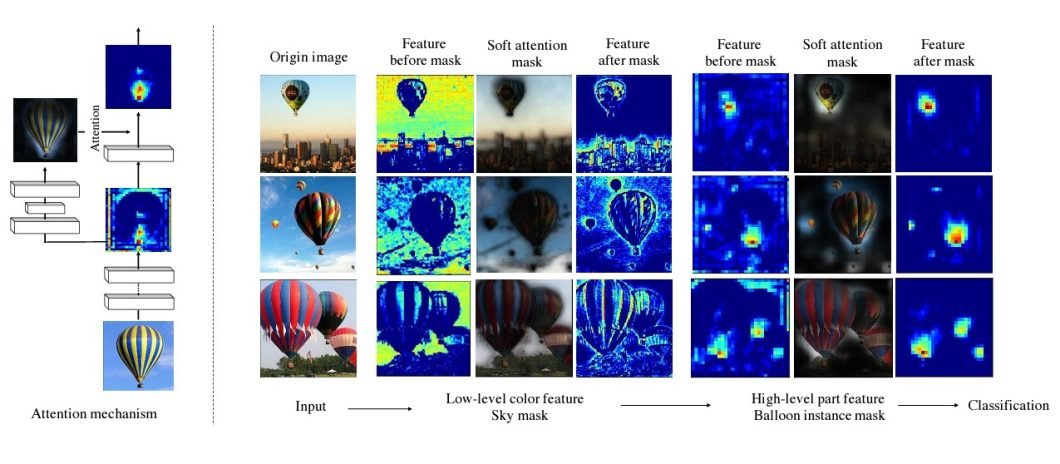
Object detection and segmentation are also advancing thanks to attention mechanisms. Models like Mask R-CNN are instrumental, incorporating a Region of Interest (RoI) Align to distinguish and segment objects with high precision. Attention in Fully Convolutional Networks (FCNs) for semantic segmentation helps outline detailed object boundaries by weighting pixel contributions.
Visual Question Answering (VQA) also benefits from dual attention networks. These systems must attend to both the textual question and visual features of the image. They must also reserve computational resources on relevant image regions and question words to generate accurate answers. The Stacked Attention Network (SAN), for example, employs a multi-stage attention process to iteratively refine the focus area.
In medical imaging, attention mechanisms are useful for tools like U-Net. Attention gates guide the model to pay more attention to abnormal tissue patterns while suppressing the irrelevant regions. Thereby increasing sensitivity and specificity in diagnostic predictions for tasks like tumor detection.
Implementing Attention Mechanisms
You must weigh several technical considerations when incorporating attention mechanisms into sequence-to-sequence models. Attention adds considerable computational overhead at scale, especially in encoder-decoder architectures, due to its quadratic dependency on sequence length. In particular, practitioners have to optimize data throughput and memory usage. Mechanisms like sparse attention or reversible layers can mitigate this to some extent.
Furthermore, data requirements for attention-based models are often substantial. These models need a large and diverse data set to learn the nuanced patterns necessary to focus attention effectively.
Existing frameworks and libraries are central in developing and implementing attention-based models. TensorFlow and PyTorch are leading deep learning platforms that offer comprehensive toolkits, including specialized modules. For example, tf.keras.layers.Attention and torch.nn.MultiheadAttention allows for a more streamlined integration of attention into models.
These libraries also facilitate the instantiation of both the encoder and decoder components with built-in attention capabilities. This helps facilitate rapid prototyping and benchmarking, essential for exploring different applications of attention mechanisms.
As a best practice, integrating attention into existing models should go through rigorous evaluation. Monitoring metrics such as attention distribution can surface insights into the model’s focus and interpretability. Attention weight visualization or attention rollout provides qualitative analysis to supplement quantitative performance metrics.
For encoder-decoder models, best practices for embedding attention include attentive initialization. This ensures the attention mechanism makes a constructive contribution from early in its training.
Key Tips
- Implement attention mechanisms progressively. Start with simpler forms like additive attention before moving to multi-head configurations.
- Utilize attention masking and normalization to maintain stability in training.
- Leverage pre-trained models, such as those available in Hugging Face’s Transformers library, to utilize attention mechanisms fine-tuned on large datasets.
Use Case: Improving Detection of Retinal Diseases
In a partnership between Google’s DeepMind and Moorfields Eye Hospital, an AI model with attention mechanisms significantly advanced the diagnosis of retinal diseases. Utilizing OCT images, the model focused on specific disease markers, enhancing its ability to detect abnormalities.
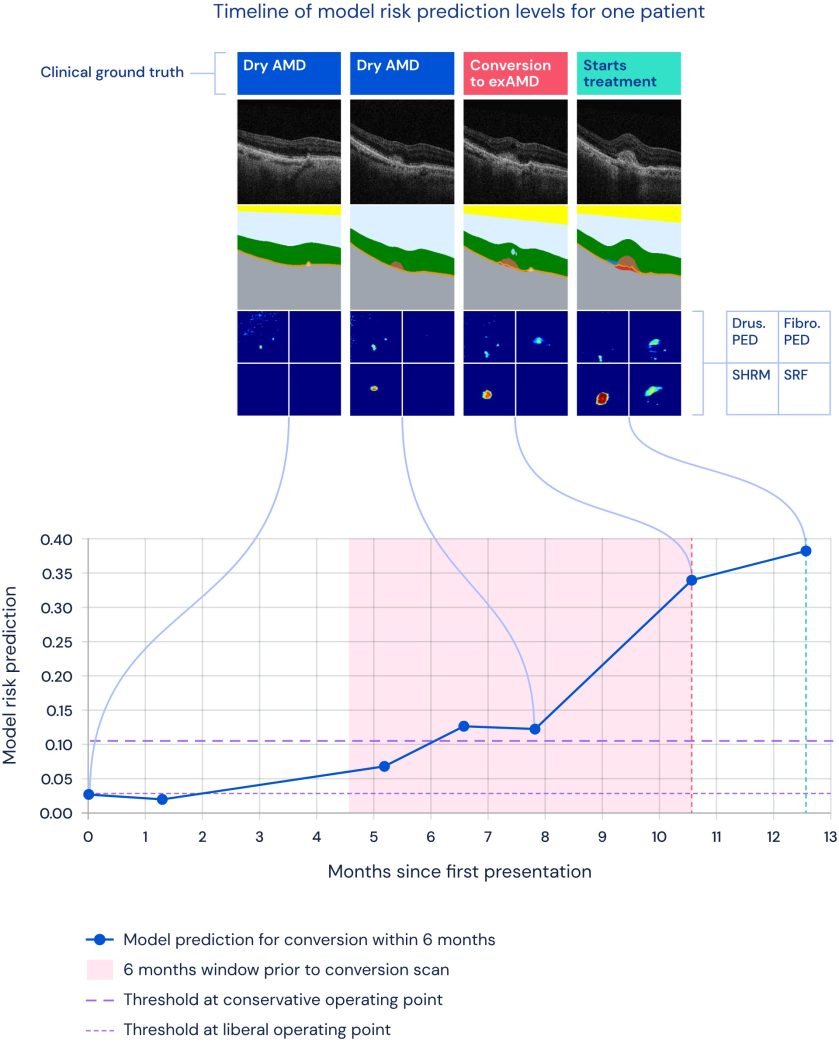
This approach matched the accuracy of top medical experts and provided interpretable diagnostic data, which is vital for clinician acceptance. The resulting efficiencies improved patient outcomes by enabling earlier treatment while optimizing clinicians’ workflow.
What’s Next for Attention Mechanisms in ML?
Attention mechanisms represent advancements in machine learning and computer vision, enabling models to prioritize relevant information for better performance. As research progresses, attention mechanisms will further enhance the capabilities and interpretability of deep learning models.
To continue learning about the world of computer vision, check out our other blogs:
- Representation Learning: Unlocking the Hidden Structure of Data
- Grounded-SAM Explained: A New Image Segmentation Paradigm?
- OpenAI Sora: the Text-Driven Video Generation Model
- YOLOX Explained: Features, Architecture, and Applications
- Image Registration and Its Applications
- The 3 Types of Artificial Intelligence: ANI, AGI, and ASI