YOLO (You Only Look Once) is a family of object detection models popular for their real-time processing capabilities, delivering high accuracy and speed on mobile and edge devices. Released in 2020, YOLOv4 enhances the performance of its predecessor, YOLOv3, by bridging the gap between accuracy and speed.
While many of the most accurate object detection models require multiple GPUs running in parallel, YOLOv4 can be operated on a single GPU with 8GB of VRAM, such as the GTX 1080 Ti, which makes widespread use of the model possible.
In this blog, we will look deeper into the architecture of YOLOv4, what changes were made that made it possible to run in a single GPU, and finally look at some of its real-life applications.
The YOLO Family of Models
The first YOLO model was introduced back in 2016 by a team of researchers, marking a significant advancement in object detection technology. Unlike the two-stage models popular at the time, which were slow and resource-intensive, YOLO introduced a one-stage approach to object detection.
YOLOv1
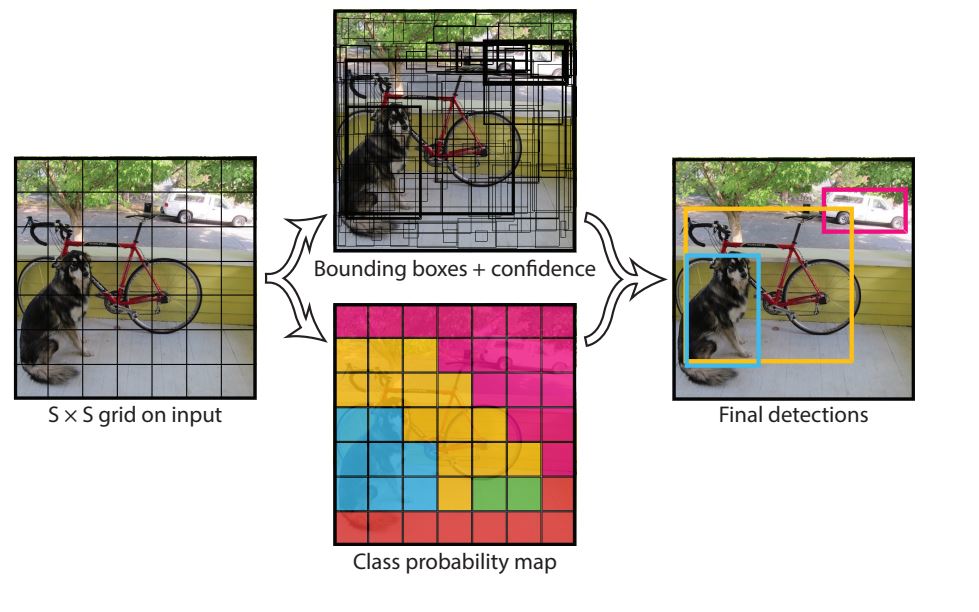
The architecture of YOLOv1 was inspired by GoogLeNet and divided the input size image into a 7×7 grid. Each grid cell predicted bounding boxes and confidence scores for multiple objects in a single pass. With this, it was able to run at over 45 frames per second and made real-time applications possible. However, accuracy was poorer compared to two-stage models such as Faster RCNN.
YOLOv2
The YOLOv2 object detector model was introduced in 2016 and improved upon its predecessor with better accuracy while maintaining the same speed. The most notable change was the introduction of predefined anchor boxes into the model for better bounding box predictions. This change significantly improved the model’s mean average precision (mAP), particularly for smaller objects.
YOLOv3
| Type | Filters | Size | Output | |
|---|---|---|---|---|
| Convolutional | 32 | 3 × 3 | 256 × 256 | |
| Convolutional | 64 | 3 × 3 / 2 | 128 × 128 | |
| 1× | Convolutional | 32 | 1 × 1 | 128 × 128 |
| Convolutional | 64 | 3 × 3 | ||
| Residual | ||||
| Convolutional | 128 | 3 × 3 / 2 | 64 × 64 | |
| 2× | Convolutional | 64 | 1 × 1 | 64 × 64 |
| Convolutional | 128 | 3 × 3 | ||
| Residual | ||||
| Convolutional | 256 | 3 × 3 / 2 | 32 × 32 | |
| 8× | Convolutional | 128 | 1 × 1 | 32 × 32 |
| Convolutional | 256 | 3 × 3 | ||
| Residual | ||||
| Convolutional | 512 | 3 × 3 / 2 | 16 × 16 | |
| 8× | Convolutional | 256 | 1 × 1 | 16 × 16 |
| Convolutional | 512 | 3 × 3 | ||
| Residual | ||||
| Convolutional | 1024 | 3 × 3 / 2 | 8 × 8 | |
| 4× | Convolutional | 512 | 1 × 1 | 8 × 8 |
| Convolutional | 1024 | 3 × 3 | ||
| Residual | ||||
| Avgpool | Global | |||
| Connected | 1000 | |||
| Softmax | ||||
YOLOv3 was released in 2018 and introduced a deeper backbone network, the Darknet-53, which had 53 convolutional layers. This deeper network helped with better feature extraction. Additionally, it introduced Objectness scores for bounding boxes (predicting whether the bounding box contains an object or background). Additionally, the model introduced Spatial Pyramid Pooling (SPP), which increased the receptive field of the model.
Key Innovation introduced in YOLOv4
YOLOv4 improved the efficiency of its predecessor and made it possible for it to be trained and run on a single GPU. Overall, the architecture changes made throughout the YOLOv4 are as follows:
- CSPDarknet53 as backbone: Replaced the Darknet-53 backbone used in YOLOv3 with CSP Darknet53
- PANet: YOLOv4 replaced the Feature Pyramid Network (FPN) used in YOLOv3 with PANet
- Self-Adversarial Training (SAT)
Additionally, the authors did extensive research on finding the best way to train and run the model. They categorized these experiments as Bag of Freebies (BoF) and Bag of Specials (BoS).
Bag of Freebies are changes that take place during the training process only and help improve the model performance, therefor,e it only increases the training time while leaving the inference time the same. Whereas, Bag of Specials introduces changes that slightly increase inference computation requirements but offer greater accuracy gain. With this, a user could select what freebies they need to use while also being aware of its costs in terms of training time and inference speed against accuracy.
Architecture of YOLOv4
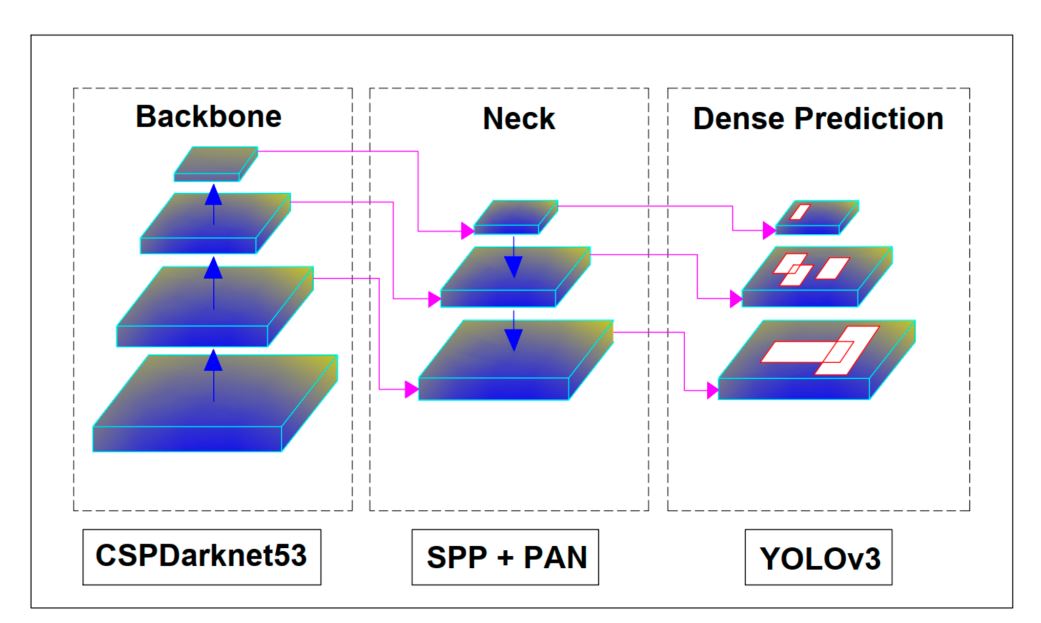
Although the architecture of YOLOv4 seems complex at first, overall, the model has the following main components:
- Backbone: CSPDarkNet53
- Neck: SSP + PANet
- Head: YOLOv3
Apart from these, everything is left up to the user to decide what they need to use with Bag of Freebies and Bag of Specials.
CSPDarkNet53 Backbone
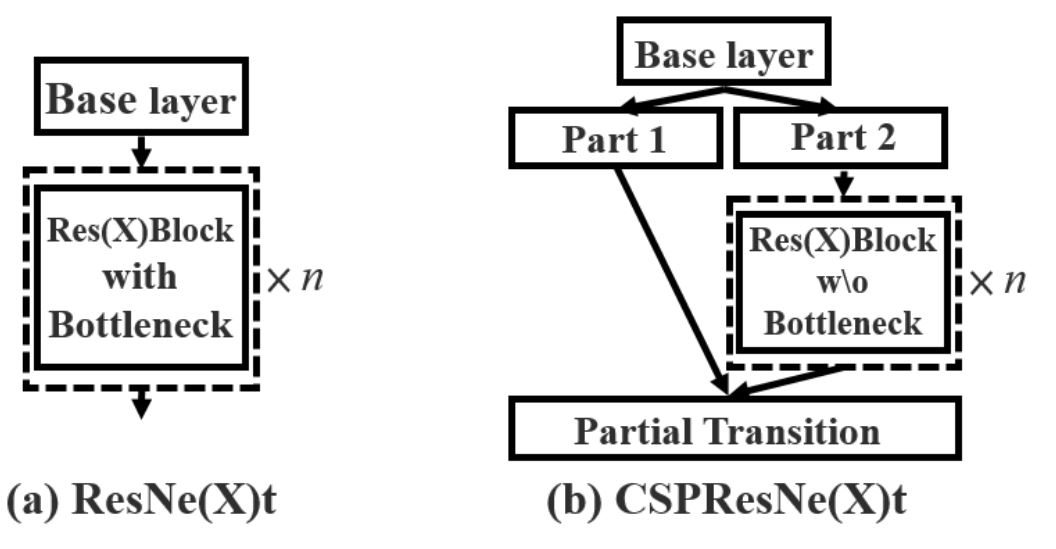
A Backbone is a term used in the YOLO family of models. In YOLO models, the sole purpose is to extract features from images and pass them forward to the model for object detection and classification. The backbone is a CNN architecture made up of several layers. In YOLOv4, the researchers also offer several choices for backbone networks, such as ResNeXt50, EfficientNet-B3, and Darknet-53, which has 53 convolution layers.
YOLOv4 uses a modified version of the original Darknet-53, called CSPNetDarkNet53, and is an important component of YOLOv4. It builds upon the Darknet-53 architecture and introduces a Cross-Stage Partial (CSP) strategy to enhance performance in object detection tasks.
The CSP strategy divides the feature maps into two parts. One part flows through a series of residual blocks while the other bypasses them and concatenates them later in the network. Although Darknet (inspired by ResNet uses a similar design in the form of residual connections, the difference lies in addition and concatenation. Residual connections add feature maps, whereas CSP concatenates them.
Concatenation feature maps side by side along the channel dimension increases the number of channels. For example, concatenating two feature maps, each with 32 channel,s results in a new feature map with 64 channels. Due to this nature, features are preserved better and improve the object detection model accuracy.
Also, the CSP strategy uses less RAM, as half of the feature maps go through the network. Due to this, CSP strategies have been shown to reduce computation needs by 20%.
SSP and PANet Neck
The neck in YOLO models collects feature maps from different stages of the backbone and passes them down to the head. The YOLOv4 model uses a custom neck that consists of a modified version of PANet, spatial pyramid pooling (SPP), and spatial attention module (SAM).
SPP
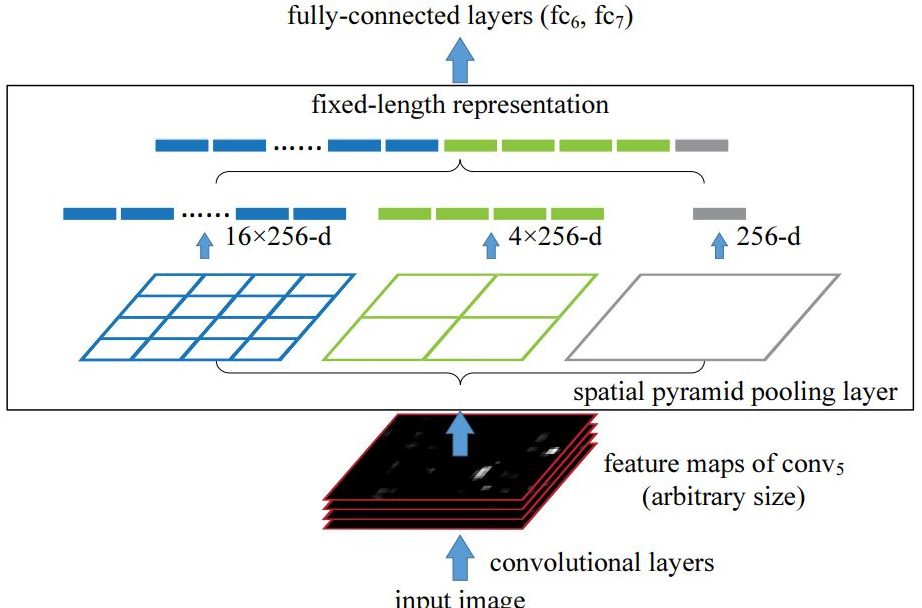
In the traditional Spatial Pyramid Pooling (SPP), fixed-size max pooling is applied to divide the feature map into regions of different sizes (e.g., 1×1, 2×2, 4×4), and each region is pooled independently. The resulting pooled outputs are then flattened and combined into a single feature vector to produce a fixed-length feature vector that does not retain spatial dimensions. This approach is ideal for classification tasks, but not for object detection, where the receptive field is critical.
In YOLOv4, this is modified and uses fixed-size pooling kernels with different sizes (e.g., 1×1, 5×5, 9×9, and 13×13) but keeps the same spatial dimensions of the feature map.
Each pooling operation produces a separate output, concatenated along the channel dimension rather than flattened. By using large pooling kernels (like 13×13) in YOLOv4, the SPP block expands the receptive field while preserving spatial details, allowing the model to better detect objects of various sizes (large and small objects). Additionally, this approach adds minimal computational overhead, supporting YOLOv4 for real-time detection.
PAN
YOLOv3 made use of FPN, but it was replaced with a modified PAN in YOLOv4. PAN builds on the FPN structure by adding a bottom-up pathway in addition to the top-down pathway. This bottom-up path aggregates and passes features from lower levels back up through the network, reinforcing lower-level features with contextual information and enriching high-level features with spatial details.
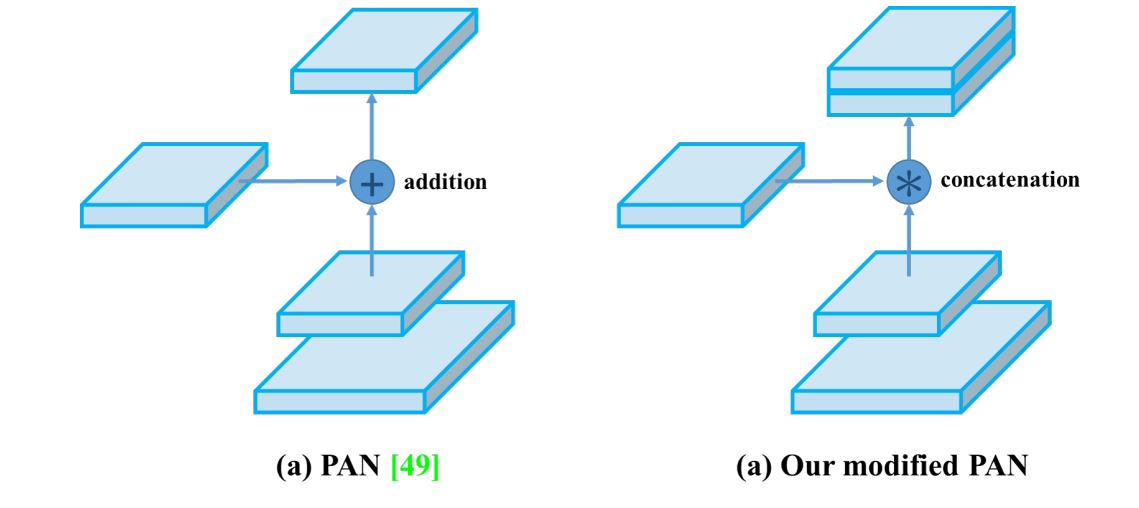
However, in YOLOv4, the original PANet was modified and used concatenation instead of aggregation. This allows it to use multi-scale features efficiently.
Modified SAM
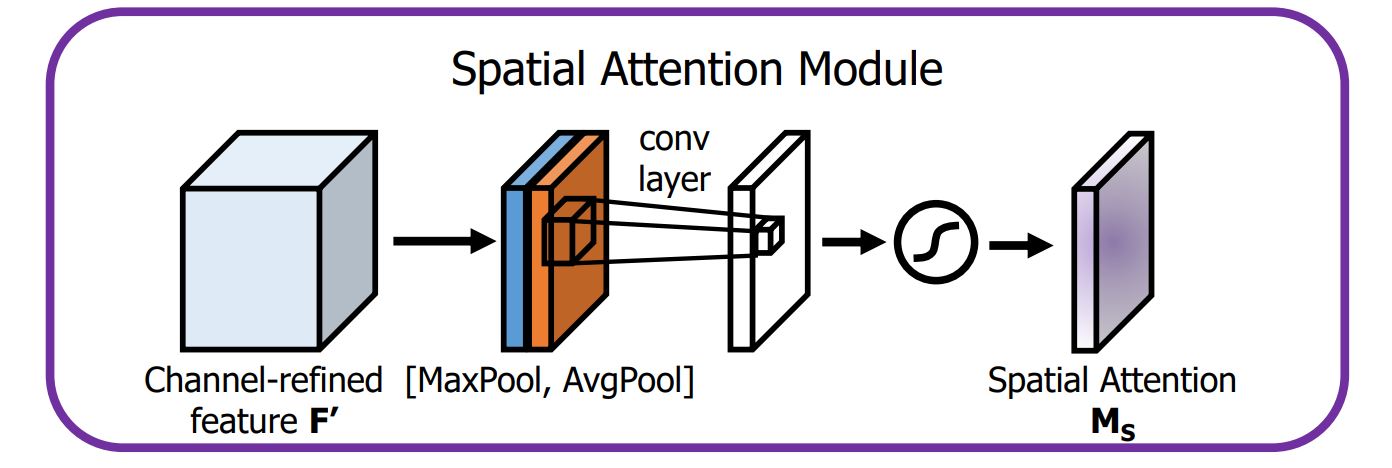
The standard SAM technique uses both maximum and average pooling operations to create separate feature maps that help focus on significant areas of the input.
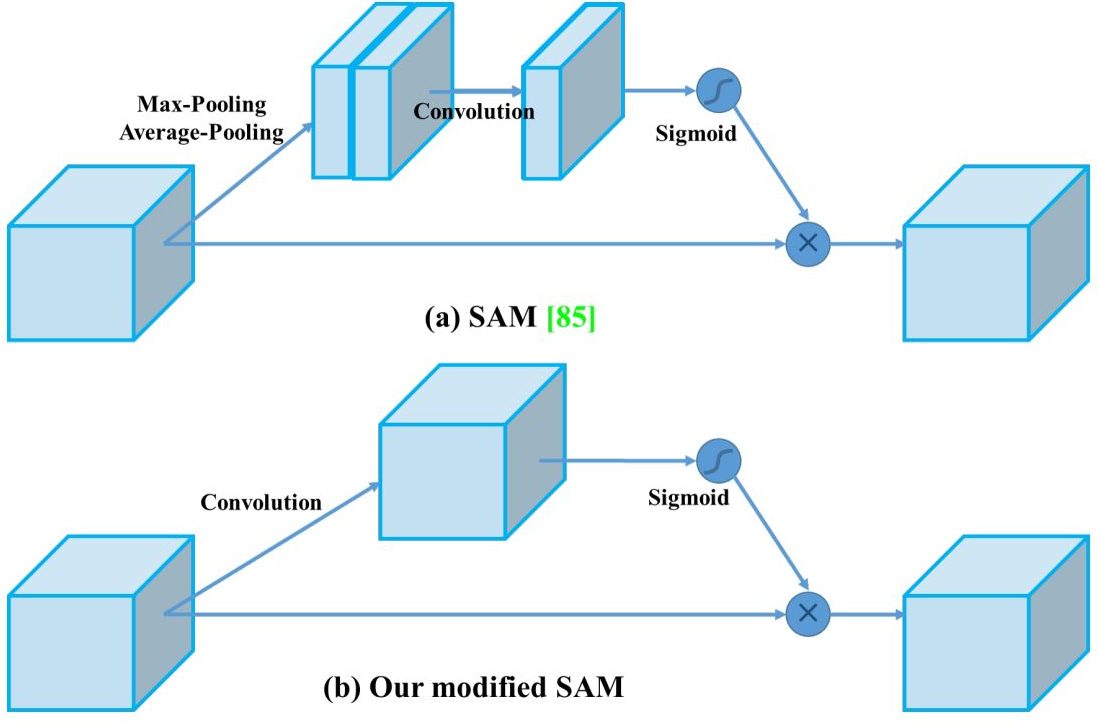
However, in YOLOv4, these pooling operations are omitted (because they reduce the information contained in feature maps). Instead, the modified SAM directly processes the input feature maps by applying convolutional layers followed by a sigmoid activation function to generate attention maps.
How does a Standard SAM work?
The Spatial Attention Module (SAM) is important for its role in allowing the model to focus on features that are important for detection and depressing the irrelevant features.
- Pooling Operation: SAM begins by processing the input feature maps in YOLO layers through two types of pooling operations—average pooling and max pooling.
- Average Pooling produces a feature map that represents the average activation across channels.
- Max Pooling captures the most significant activation, emphasizing the strongest features.
- Concatenation: The outputs from average and max pooling are concatenated to form a combined feature descriptor. This step outputs both global and local information from the feature maps.
- Convolution Layer: The concatenated feature descriptor is then passed through a Convolution Neural Network. The convolutional operation helps to learn spatial relationships and further refines the attention map.
- Sigmoid Activation: A sigmoid activation function is applied to the output of the convolution layer, resulting in a spatial attention map. Finally, this attention map is multiplied element-wise with the original input feature map.
YOLOv3 Head
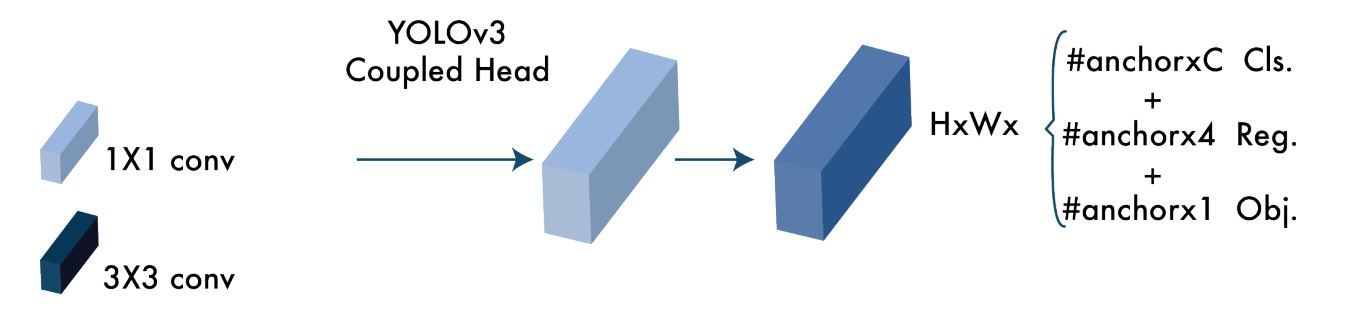
The head of YOLO models is where object detection and classification happens. Despite YOLOv4 being the successor it retains the head of YOLOv3, which means it also produces anchor box predictions and bounding box regression.
Therefore, we can see that the optimizations performed in the backbone and neck of YOLOv4 are the reason we see a noticeable improvement in efficiency and speed.
What is Self-Adversarial Training (SAT)
Self-Adversarial Training (SAT) in YOLOv4 is a data augmentation technique used in training images (train data) to enhance the model’s robustness and improve generalization.
How SAT Works
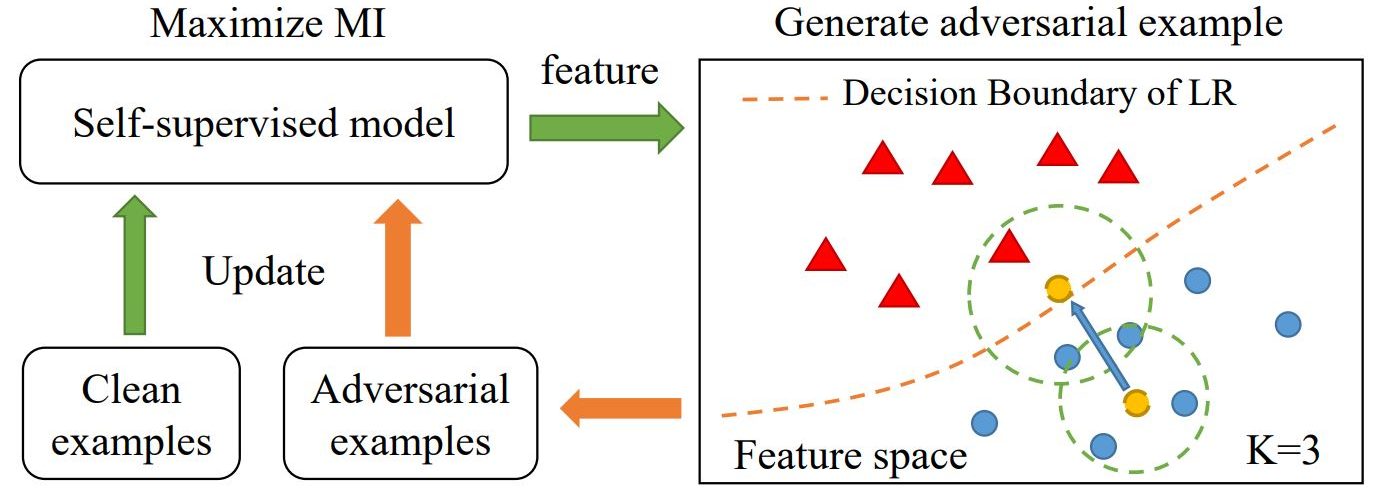
The basic idea of adversarial training is to improve the model’s resilience by exposing it to adversarial examples during training. These examples are created to mislead the model into making incorrect predictions.
In the first step, the network learns to alter the original image to make it appear that the desired object is not present. In the second step, the modified images are used for training, where the network attempts to detect objects in these altered images against the ground truth. This technique intelligently alters images to push the model to learn better and generalize to images not included in the training set.
Real-Life Application of Application of YOLOv4
YOLOv4 has been used in a wide range of applications and scenarios, including embedded systems. Some of these are:
- Harvesting Oil Palm: A group of researchers used YOLOv4 paired with a camera and laptop device with an Intel Core i7-8750H processor and GeForce DTX 1070 graphics card to detect ripe fruit branches. During the testing phase, they achieved 87.9 % mean Average Precision (mAP) and 82 % recall rate while running at a real-time speed of 21 FPS.

Ripe palm tree detection using YOLOv4 –source - Animal Monitoring: In this study, the researchers used YOLOv4 to detect foxes and monitor their movement and activity. Using CV, the researchers were able to automatically analyze the videos and monitor animal activity without human interference.

Silver fox detection using YOLOv4 –source - Pest Control: Accurate and efficient real-time detection of orchard pests is important to improve the economic benefits of the fruit industry. As a result, researchers trained the YOLOv4 model for the intelligent identification of agricultural pests. The mAP obtained was at 92.86%, and a detection time of 12.22ms, which is ideal for real-time detection.

Pest detection –source - Pothole Detection: Pothole repair is an important challenge and task in road maintenance, as manual operation is labor-intensive and time-consuming. As a result, researchers trained YOLOv4 and YOLOv4-tiny to automate the inspection process and received an mAP of 77.7%, 78.7%

Pothole detection using YOLOv4 –source - Train detection: Detection of a fast-moving train in real-time is crucial for the safety of the train and people around train tracks. A group of researchers built a custom object detection model based on YOLOv4 for fast-moving trains and achieved an accuracy of 95.74%, with 42.04 frames per second, which means detecting a picture only takes 0.024s.




What’s Next
In this blog, we looked into the architecture of the YOLO v4 model and how it allows training and running object detection models using a single GPU. Additionally, we looked at additional features the researchers released, termed as Bag of Freebies and Bag of Specials. Overall, the model introduces three key features. The use of the CSPDarkNet53 as the backbone, modified SSP, and PANet. Finally, we also looked at how researchers have incorporated the mode for various CV applications.