Skip to main content
Skip to footer
Platform
Viso Suite
Viso Suite is the leading end to end computer vision infrastructure to build, deploy, and scale AI vision dramatically faster and better.
All features
The Platform
Viso Suite
Feature index
Security
Privacy
Viso Suite whitepaper
ROI impact study
Pricing
Evaluation guide
Picking the right computer vision platform is difficult.
Help you choose an enterprise-grade platform to build, deploy and scale your computer vision applications.
Read more
Solutions
Industries
Construction
Manufacturing
Agriculture
Healthcare
Retail
Transportation
All industries
Suites
Manufacturing Health and Safety
Manufacturing Lean and Efficiency Suite
Applications
Equipment inspection
Restricted and hazard zone intrusion
Object counting
Predictive maintenance
Analog instruments reading
Crowd analytics
All applications
Spotlight application
Detect PPE
Automated safety and compliance monitoring to minimize accidents and increase efficiency.
Read more
Resources
Viso Suite
Viso Suite is the leading end to end computer vision infrastructure to build, deploy, and scale AI vision dramatically faster and better.
All features
Resources
Whitepapers
Industry Reports
Upcoming Webinars
On-Demand Webinars
HSE Toolkit
All resources
The viso Blog
Company news
Deep learning
Edge AI
Product
Computer vision
All posts
Spotlight article
How to Convince Your Team to Invest in Computer Vision
Technical teams can easily recognize the necessity of computer vision solutions, but securing executive buy-in is often the bigger challenge.
Read more
Company
Viso Suite
Viso Suite is the leading end to end computer vision infrastructure to build, deploy, and scale AI vision dramatically faster and better.
All features
Company
About viso
Partners
Ambassador programme
Careers
Contact
Spotlight customer
Reduce construction worksite accidents
Read more
Customers
Log in
Request a demo
Platform
Viso Suite
Feature index
Secure computer vision built with Viso Suite
Ensuring full data privacy for computer vision with Viso Suite
Pricing
Evaluation Guide
Industries
Resources
The viso blog
Company
About viso
Partners
Careers
Contact
Customers
Request a demo
Deep Learning
News about Deep Learning Technology and visual AI. Find industry updates, expert interviews, and the latest insights in one place.
Search Deep Learning
Filter by
All Industries
Hospitality
Change topic
All
Change topic
All
Blog
Deep Learning
Subscribe
Deep Learning
OpenAI Sora: the Text-Driven Video Generation Model
OpenAI Sora is a text-to-video model that creates realistic and imaginative scenes from textual prompts with a diffusion transformer model.
Deep Learning
Midjourney vs. Stable Diffusion: Which should you use?
Midjourney vs Stable Diffusion are two of the leading AI art generators from the AI boom. We explore their strengths and weaknesses.
Deep Learning
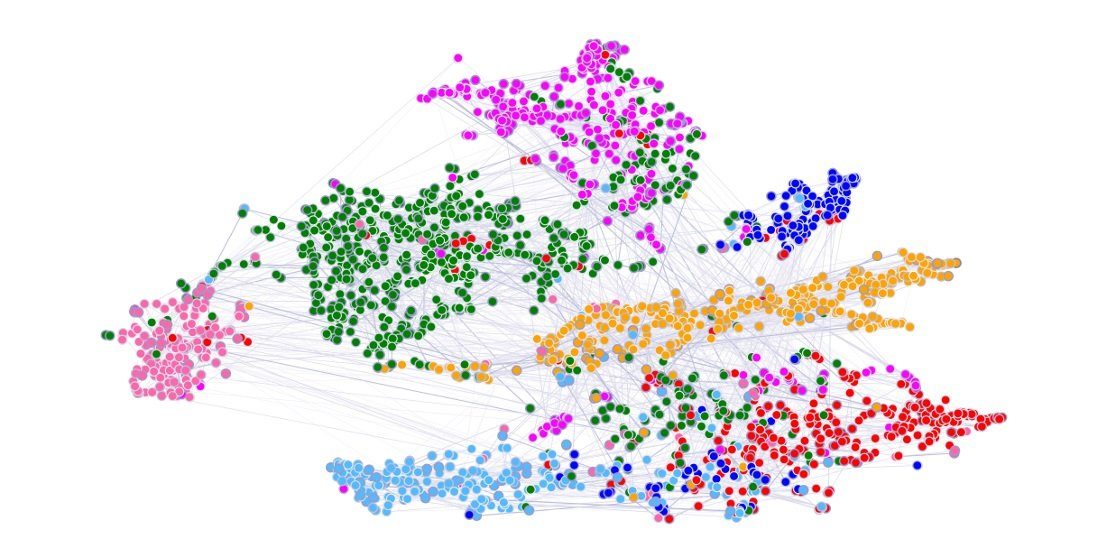
Graph Neural Networks (GNNs) – Comprehensive Guide
Graph Neural Networks (GNNs) operate on graph-structured data, enabling them to learn relationships and patterns within complex networks.
Deep Learning
DETR: End-to-End Object Detection With Transformers
DETR is a method for object detection with transformers. Explore its architecture, how it predicts bounding boxes and labels, and use cases.
Deep Learning
The 3 Types of Artificial Intelligence: ANI, AGI, and ASI
Is AGI already here? We discuss everything you need to know about the 3 types of artificial intelligence in a complete guide.
Deep Learning
How to Detect AI-Generated Content
With the ubiquity of generative AI tools, we now see their outputs everywhere. Learn how to spot different types of AI-generated content.
Deep Learning
Detectron2: A Rundown of Meta’s Computer Vision Framework
Our guide to Detectron2 dives into the framework's computer vision capabilities, covering everything from its architecture to use cases.
Deep Learning
Deep Belief Networks (DBNs) explained
We deep dive into the foundations of deep learning with deep belief networks: their architecture, capabilities, applications and challenges.
Deep Learning
Action Localization: Everything You Need To Know
Action localization identifies and localizes human actions within video sequences, making them searchable, analyzable, and more meaningful.
Deep Learning
Experiment Tracking in Machine Learning – Everything You Need to Know
From definition to implementation to tools, this guide offers a complete rundown on experiment tracking in machine learning.
Deep Learning
7 Critical Model Training Errors: What They Mean & How to Fix Them
In this blog, we break down 7 of the most common AI model training errors, what you can do to fix them, and how avoid
Deep Learning
Deepfakes in the Real World – Applications and Ethics
Deepfakes have the potential to democratize content creation or undermine public trust. We explore the ethics and state of this technology.
Load more