
During machine learning model training, there are seven common errors that engineers and data scientists typically run into. While receiving errors is frustrating, teams must know how to address these and how they can avoid them in the future.
In the following, we will offer in-depth explanations, preventative measures, and quick fixes for known model training issues while addressing the question of “What does this model error mean?”.
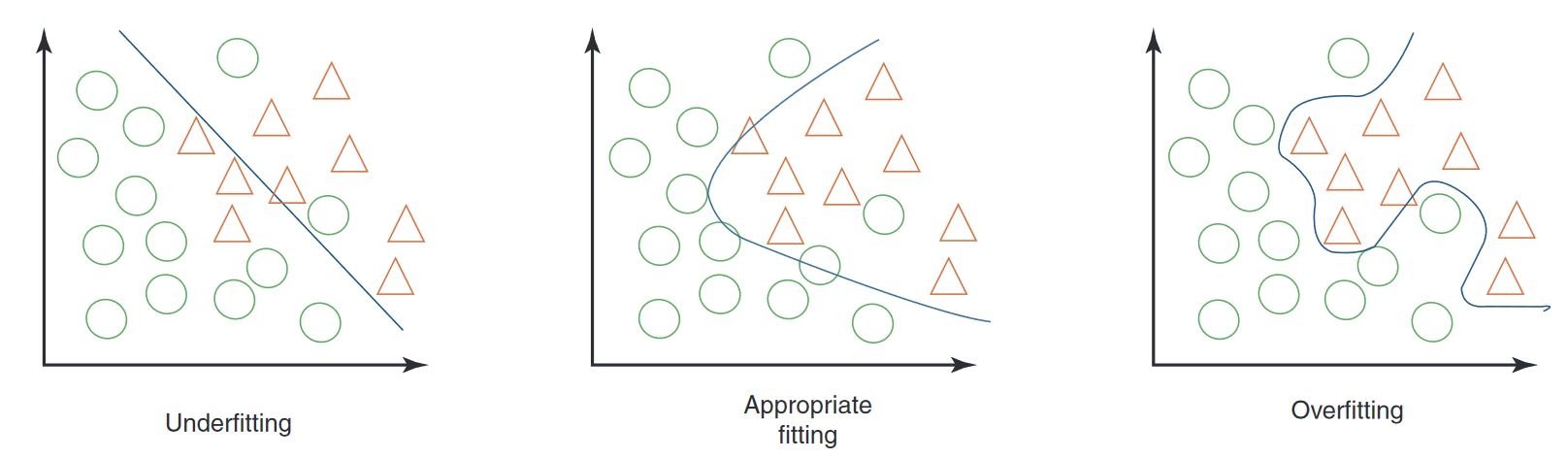
Model Error No. 1: Overfitting and Underfitting
What is Underfitting and Overfitting?
One of the most common problems in machine learning happens when the training data is not well fitted to what the machine learning model is supposed to learn.
In overfitting, there are too few examples for the ML model to work on. It fails to come up with the type of robust analysis that it is supposed to do. Underfitting is the opposite problem – there’s too much to learn, and the machine learning program is, in a sense, overwhelmed by too much data.
How to Fix Underfitting and Overfitting
In this case, fixing the issue has a lot to do with framing a machine-learning process correctly. Proper fitting is like matching data points to a map that is not too detailed, but just detailed enough. Developers are trying to use the right dimensionality to make sure that the training data matches its intended job.
To fix an overfitting problem, it is recommended to reduce layers and pursue cross-validation of the training set. Feature reduction and regularization can also help. For underfitting, on the other hand, the goal is often to build in complexity, although experts also suggest that removing noise from the data set might help, too.
For the computer vision task of classification, you can use a confusion matrix to evaluate model performance, including underfitting and overfitting scenarios, on a separate test set.
Model Error No. 2: Data Imbalance Issues in Machine Learning
Even if you’re sure that you have given the machine learning model enough examples to do its job, but not too many, you might run into something called ‘class imbalance’ or ‘data imbalance’.
Data imbalance, a common issue in linear regression models and prediction models, represents a lack of a representative training dataset for at least some of the results that you want. In other words, if you want to study four or five classes of images or objects, all of the training data is from one or two of those classes. That means the other three are not represented in the training data at all, so the model will not be able to work on them. It’s unfamiliar with these examples.
How to Fix Data Imbalance
To address an imbalance, teams will want to make sure that every part of the focus class set is represented in the training data. Tools for troubleshooting bias and variance include auditing programs and detection models like IBM’s AI Fairness 360.
There’s also the bias/variance problem, where some associate bias with training data sets that are too simple, and excessive variance with training data sets that are too complex. In some ways, though, this is simplistic.
Bias has to do with improper clustering or grouping of data, and variance has to do with data that is too spread out. There’s a lot more detail to this, but in terms of fixing bias, the goal is to add more relevant data that is diverse, to reduce bias that way. For variance, it often helps to add data points that will make trends clearer to the ML.
Model Error No. 3: Data Leakage
If this brings to mind the image of a pipe leaking water, and you worry about data being lost from the system, that’s not really what data leakage is about in the context of machine learning.
Instead, this is a situation where information from the training data leaks into the program’s operational capacity, where the training data is going to have too much of an effect on the analysis of real-world results.
In data leakage situations, models can, for instance, return perfect results that are “too good to be true”, which may be an example of data leakage.
How to Fix Data Leakage
During model development, there are a couple of ways to minimize the risk of data leakage occurring:
- Data Preparation within Cross-Validation Folds is performed by recalculating scaling parameters separately for each fold.
- Withholding the Validation Dataset until the model development process is complete allows you to see whether the estimated performance metrics were overly optimistic and indicative of leakage.
Platforms like R and scikit-learn in Python are useful here. They use automation tools like the caret package in R and Pipelines in scikit-learn.
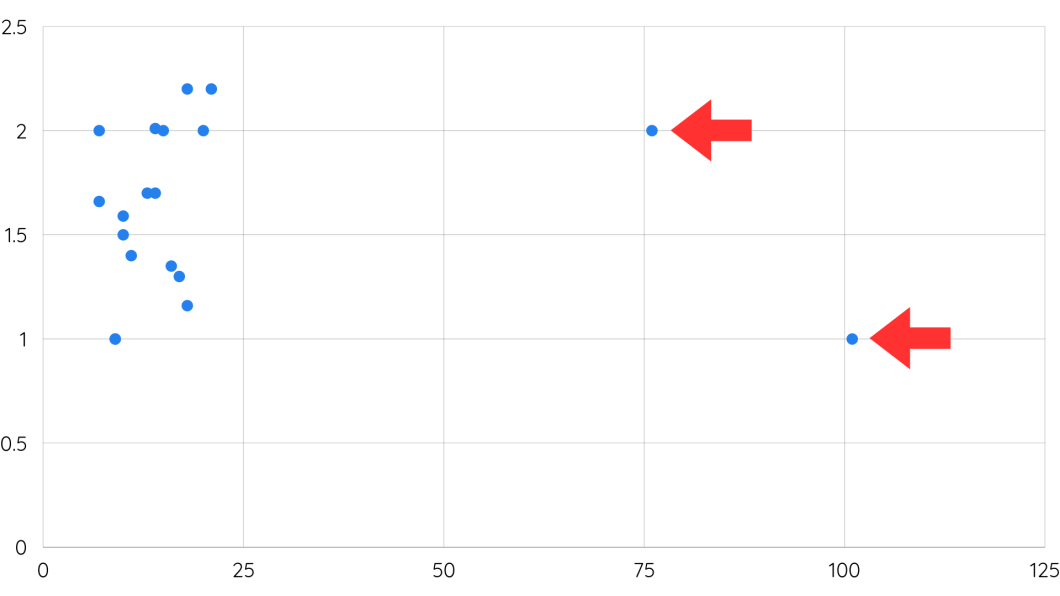
Model Error No. 4: Outliers and Minima
It’s important to look out for data outliers, or more extreme data points in a training data set, which can throw the model off during training or later provide false positives.
In machine learning, outliers can disrupt model training by leading to premature convergence or suboptimal solutions, particularly in local minima. Taking care of outliers will help make sure that the model converges towards patterns in the data distribution.
How to Fix Data Outliers
Some experts discuss challenges with global and local minima – again, the idea that the data points are changing dynamically across a range. However, the machine learning program might get trapped in a cluster of more local results, without recognizing some of the outlier data points in the global set. The principle of looking globally at data is important. It’s something that engineers should always build into models.
- Algorithms like Random Forests or Gradient Boosting Machines are less sensitive to outliers in general.
- Algorithms like Isolation Forests and Local Outlier Factor manage outliers separately from the main dataset.
- You can alter skewed features or create new features less sensitive to outliers by using techniques such as log transformations or scaling methods.
Model Error No. 5: Clerical Errors – Data and Labeling Problems
Aside from all of these engineering issues with machine learning, there’s a whole set of other AI model errors that can be problematic. These have to do with poor data hygiene.
These are very different kinds of issues. Here, it’s not the program’s method that’s in error – instead, there are errors in the data itself that trained the model on.
One of these types of errors is called a labeling error. In supervised or semi-supervised learning systems, data is typically labeled. If the labels are wrong, you’re not going to get the right result. So labeling errors are something to look out for early on in the process.
How to Fix Data Labeling Problems
Then, there’s the problem of partial data sets or missing values. This is a bigger deal with raw or unstructured data that engineers and developers might be using to feed the machine learning program.
Data scientists know about the perils of unstructured data – but it’s not always something that ML engineers think about – until it’s too late. Making sure that the training data is correct is imperative in the process.
In terms of labeling and data errors, the real solution is precision. Or call it ‘due diligence’ or ‘doing your homework’. Going through the data with a fine-toothed comb is often what’s called for. However, before the training process, preventative measures are going to be key:
- Data quality assurance processes
- Iterative labeling
- Human-in-the-loop labeling (for verifying and correcting labels)
- Active learning
Model Error No. 6: Data Drift
There’s another fundamental type of model training error in ML to look out for: it’s commonly called data drift.
Data drift happens when a model becomes less able to perform well because of changes in data over time. Sometimes, data drift happens when a model’s performance on new data differs from how it deals with the training or test data.
There are different types of data drift, including concept drift and drift in the actual input data. When the distribution of the input data changes over time, that can throw off the program.
In other cases, the program may not be designed to handle the kinds of change that programmers and engineers subject it to. That can be, again, an issue of scope, targeting, or the timeline that people use for development. In the real world, data changes often.
How to Fix Data Drift
There are several approaches you can take to fixing data drift, including implementing algorithms such as the Kolmogorov-Smirnov test, Population Stability Index, and Page-Hinkley method. This resource from Datacamp mentions some of the finer points of each type of data drift example:
- Continuous Monitoring: Regularly analyzing incoming data and comparing it to historical data to detect any shifts.
- Feature Engineering: Selecting features that are less sensitive to transforming features to make them more stable over time.
- Adaptive Model Training: Algorithms can adjust the model parameters in response to changes in the data distribution.
- Ensemble Learning: Ensemble learning techniques combine multiple models trained on different subsets of data or using different algorithms.
- Data Preprocessing and Resampling: Regularly preprocess the data and resample it with techniques such as data augmentation, synthetic data generation, or stratified sampling so it remains representative of the population.
Model Error No. 7: Lack of Model Experimentation
Model experimentation is the iterative process of testing and refining model designs to optimize performance. It entails exploring different architectures, hyperparameters, and training strategies to identify the most effective model for a given task.
However, a major AI model training error can arise when developers don’t cast a wide enough net in designing ML models. This happens when users prematurely settle on the first model they train without exploring other designs or considering alternate possibilities.
How to Fix a Lack of Model Experimentation
Rather than making the first model the only model, many experts would recommend trying out several designs and triangulating which one is going to work best for a particular project. A step-by-step process for this could look like:
- Step One: Establish a framework for experimentation to examine various model architectures and configurations. To assess model performance, you would test other algorithms, adjust hyperparameters, and experiment with different training datasets.
- Step Two: Use tools and methods for systematic model evaluation, such as cross-validation techniques and performance metrics analysis.
- Step Three: Prioritize continuous improvement during the model training process.
Staying Ahead of Model Training Errors
When fine-tuning your model, you’ll need to continue to create an error analysis. This will help you keep track of errors and encourage continuous improvements. Thus, helping you maximize performance to yield valuable results.
Dealing with machine learning model errors will become more familiar as you go. Like testing for AI software packages, error correction for machine learning is a key part of the value process.