Sora is a text-to-video artificial intelligence model developed by OpenAI that can create realistic and imaginative scenes from text instructions. OpenAI considers Sora as a path towards creating a simulator for the physical and digital world.
This blog post will explore Sora, diving into how it works and its potential applications. We’ll also examine its capabilities for video generation and the risks associated with its use.
What Does Sora Do?
Apart from text-to-video generation, Sora can also do several other tasks. Here is the list of things you can do using Sora.
- Text-to-Video: Using Sora, you can create videos by simply giving it instructions.
- Generate video in any format: From 1920 x 1080 to 1080 x 1920 and everything in between.
- Image Animation: Sora can animate an image; you just have to provide an image to it, and it will create a video of it
- Extending Videos: Sora can extend videos, either forward or backward in time.
- Video Editing: Sora can transform and change the styles and environments of input videos according to the text prompts provided.
- Image Generation: Sora is capable of generating images.
- Simulate virtual worlds and games: Minecraft and other video games.
Distinctive Capabilities of Sora
OpenAI, in their published paper, discussed that when trained at scale, Sora showed interesting capabilities, some of which are:
- Realistic 3D Worlds: Sora creates videos with smooth camera movement, maintaining consistent depth and object positions despite changes in perspective.
- Long Videos with Memory: Unlike some video generators, Sora can keep track of objects and characters throughout a video, even if they disappear for a while. It can also show the same character multiple times with a consistent appearance.
- Simple Interactions: Sora can simulate basic interactions like painting leaving marks or a character eating something that changes their appearance.
- Simulating Games: Sora can even be used to control characters in simple video games like Minecraft, generating the game world and the character’s actions simultaneously.
How Does Sora Work?
Sora utilizes diffusion transformer architecture to generate videos. As the name suggests, Sora is a diffusion model combined with a transformer (more on this below).
Moreover, at the core, Sora does something different, it uses visual patches as tokens, inspired by LLMs like ChatGPT (GPT uses words as tokens).
Visual Patches
Video data is made of frames, subsequently, Sora treats them as a collection of frames. Then each frame is decomposed into a group of pixels. Here is what Sora does differently, it treats the pixels not just as ordinary pixels, but as a 3D structure, capturing temporal (time) information of pixels.

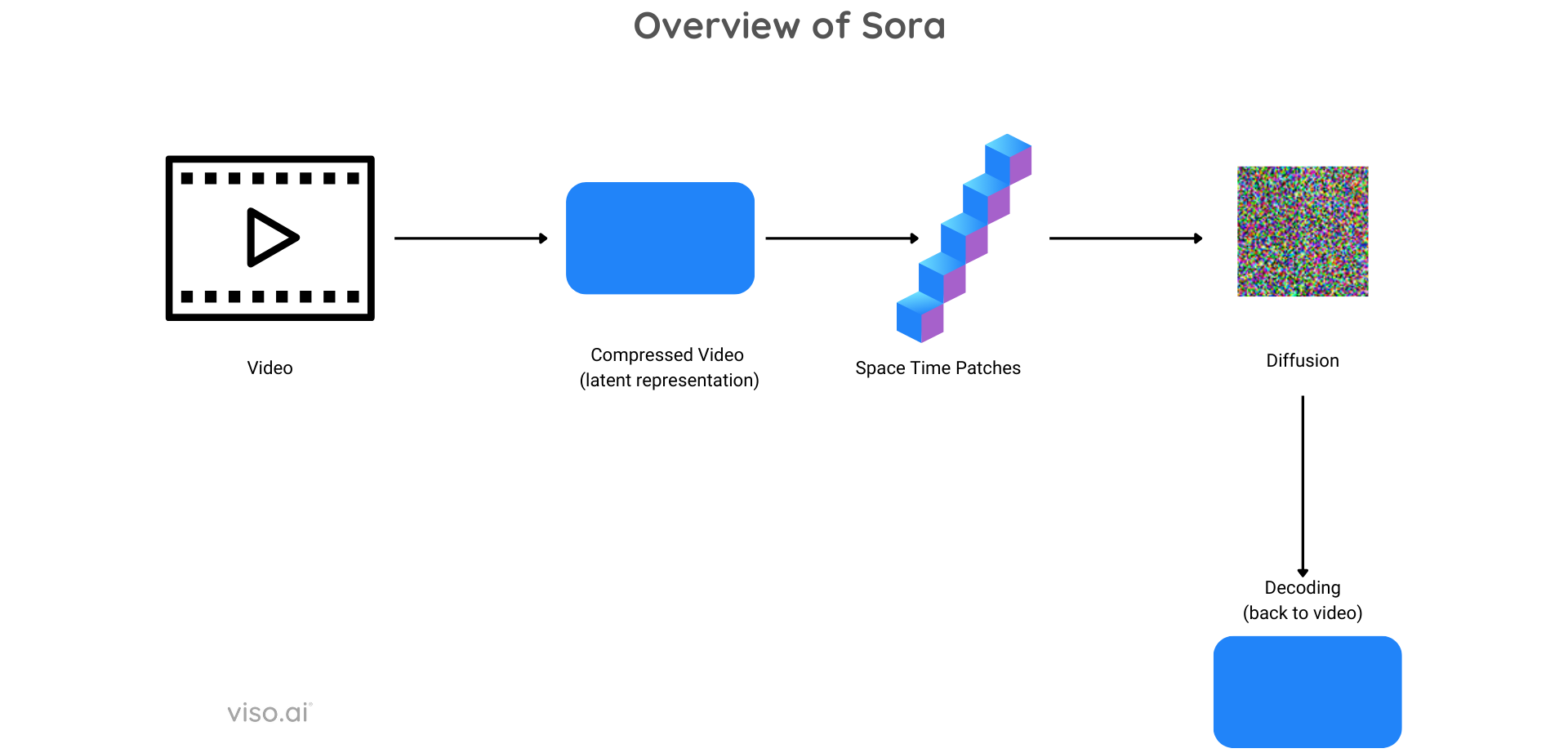
Sora Architecture
To understand the role of visual patches, we need to look at the architecture of Sora, which is as follows:
- Compression: Sora takes raw video as input, and then compresses it into a latent representation that stores information regarding spatial (the location of pixels) and temporal (the relation of pixels with time).
- Space-Time Patches: The compressed latent representation is then converted into space-time patches and then used as tokens for the transformer, similar to LLMs.
- Diffusion: The space-time patches are filled with noise and then go through a diffusion process where they are denoised.

Diffusion by Sora – source - Decoding: Once the diffusion process is completed on the latent representation, they are converted back to video format.

Sora Architecture

Video Compression
Sora compresses the video into a latent representation for:
- Efficiency: Working with videos in compressed form is cheaper (fewer resources are utilized) and faster.
- Effectiveness: Latent representation space helps the AI model pay attention to what matters. Instead of looking at every pixel of the image, the model processes an equivalent representation that is significantly smaller in size.
Transformers
Transformer is a deep learning model that utilizes a mechanism called “self-attention” to process sequential input data. It can process the entire input data at once, capturing context and relevance.
Attention Mechanisms
In transformers, the “attention mechanism” allows the model to focus on different parts of the input data at different times and to consider the context of each piece of data relative to the rest of the elements in the sequence.
To understand better, we can look at the difference between CNNs and Transformers. CNNs process an area by giving equal importance to each element, whereas in transformers, the attention mechanism allows it to process elements with varying importance, resulting in it focusing on what is important and what is not.
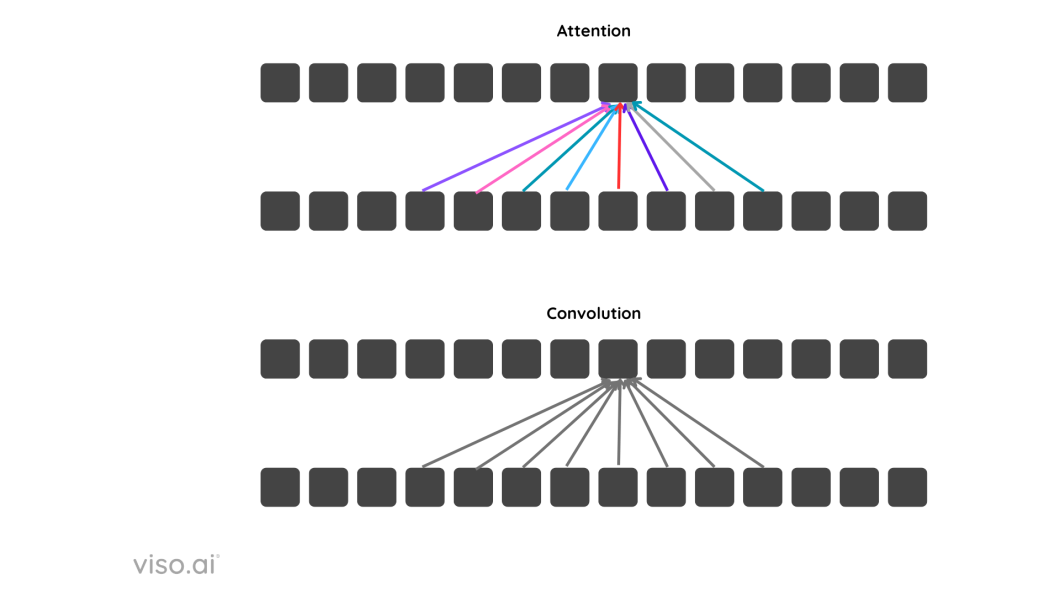
In the diagram above, the colored arrows in attention denote different weights assigned.
To understand this better, let us look at how ChatGPT utilizes the attention mechanism.
For example, consider these two sentences, “The bat flew out of the cave at dusk to hunt insects” and “He swung the bat hard, hoping to hit a home run”. The word “bat” here has a different meaning based on the context of the rest of the words in the sentence. ChatGPT tries to figure this context out.
Similarly, Sora utilizes space-time patches as tokens for the attention mechanism for:
- Frame-Level Understanding: Understand what’s going on at the frame level.
- Frame-Sequence: To understand the relationships between the different frames.
This is what enables Sora to generate videos with complex and abstract scenarios.
Generating Video from Text
To generate videos from text, during training, Sora is given two things:
- Video
- Text description of the video
To train at a large scale (internet level), OpenAI used a separate model to generate text captions for the training videos (similar to DALL-E 3). Moreover, they also used GPT to generate a detailed caption from user prompts, so that the model can generate video accurately. Moreover, Sora utilizes another important technique, called diffusion.
Diffusion
Diffusion is the process of adding noise to an image until it becomes unrecognizable, and then making the model reverse that image by denoising. The idea might seem confusing, but it powers Open AI Sora and DALL-E 3.

The process is as follows:
- Forward Diffusion (Adding Noise): The model has a clear image, and gradually adds noise to it over many steps. This creates a series of noisy versions of the original data.
- Reverse Diffusion (Removing Noise): The model is then trained to learn how to remove the noise and recover the original data (by learning a function that maps the noised version back to the original image). It does this one step at a time, going from the very noisy version back to the clean image.
By learning to remove noise effectively, the model captures the underlying patterns and structures of the real data. This allows it to generate entirely new data samples that are similar to what it has seen before.
Use Cases of OpenAI Sora
Sora, with its realistic video-generating abilities, can be used for the following;
Media Production: Sora can be used to create short films, animations, or video content for individuals and social media.
Advertising and Marketing: Companies can generate custom video ads or promotional content for specific products without the need for extensive video production resources.
Education and Training: Explainer videos and simulations that can be generated for children, students, and employees for interactive learning.
Gaming and Virtual Reality: Sora can generate dynamic backgrounds, cutscenes, or interactive elements for games and VR experiences. Reducing production costs extensively and allowing creators to focus on the gameplay to make the games more fun.
Art and Creative Exploration: Artists and creators can explore new dimensions of digital art by generating unique videos that express their ideas and convey their message.
Simulations for Drug Discovery: Sora can simulate drug interactions with molecules based on scientific descriptions. This would allow researchers to virtually test potential drugs before conducting real-world experiments.
Challenges of OpenAI Sora
Although Sora generates videos with high accuracy and realism, it still struggles with perfect realism in videos and produces inaccurate videos. Some of the issues it faces are:
- Real-world physics: Struggles with simulating complex scene physics and cause-effect relationships, such as a bitten cookie not showing a bite mark.
- Spatial inaccuracy: Confuses spatial details (e.g., mixing up left and right) and precise event descriptions over time, like specific camera movements.

Considerations Regarding OpenAI Sora
Sora can generate close to real videos and thus presents a lot of risks. Here are a few things to remember for potential misuse risks:
Risks and Ethics of Sora AI
- Social Unrest:
- Fabrication of videos inciting violence, discrimination, or social unrest.
- Ambiguity: Difficulty in distinguishing what is real and what is not.
- Harmful Content Generation: Videos containing explicit, NSFW, or other unsavory content.
- Misinformation and Disinformation:
- Spreading false information through realistic videos.
- Creation of deepfakes for manipulating real people and situations.
- For example could be used in elections to spread propaganda.
- Biases and Stereotypes: Perpetuation of cultural biases or stereotypes present in training data.
OpenAI has said that it will be taking the following steps to ensure the safe usage of Sora:
- Testing by Experts: Red teamers (experts in misinformation, hateful content, bias, etc.) will test Sora to identify potential risks.
- Misleading Content Detection: Tools are being built to detect videos generated by Sora and flag misleading content.
- Metadata for Transparency: C2PA metadata (identifying AI-generated content) will be included in future deployments.
- Leveraging Existing Safety Methods: Existing safety measures from DALL-E 3 will be applied to Sora, including:
- Text prompt filtering to prevent harmful content generation.
- Image classification to ensure adherence to usage policies before the user views the generated content.
- Collaboration & Education: OpenAI will engage policymakers, educators, and artists to:
- Understand concerns about Sora’s potential misuse.
- Identify positive use cases for the technology.
- Learn from real-world use to continuously improve safety.
Future of OpenAI Sora
OpenAI plans to use Sora as a foundation for models in the future that understand and simulate the real world.
Meanwhile, they are confident that further scaling of Sora will yield improvements. Moreover, In the future, we might see a more realistic Sora and similar models that can understand the physical dynamics of the world better, and generate more realistic videos.
To continue learning about the world of AI, check out our other blogs: