
Action localization has the power to transform how we interact with videos, making them searchable, analyzable, and infinitely more meaningful. Action localization in videos is about finding exactly where and when a particular action is happening within a video footage. Consider a city street: cars driving by, people walking, and kids eating ice cream. With action localization, you can detect and identify these actions and answer what, when, and where an action is happening autonomously.
To get started, action localization, action recognition, and action detection are tasks that represent distinct but related aspects of computer vision. Each of these tasks serves unique purposes in analyzing and understanding human activities seen in videos or image sequences. While these terms are sometimes used interchangeably, they represent different goals, methodologies, and outputs.
What is Action Recognition?
Goal
The primary goal of action recognition is to analyze entire video sequences, identify actions, and classify them into predefined categories, such as walking, running, jumping, or eating.
Output
The expected output of action recognition is the classification of an entire video sequence into one or several action categories. This is done without providing temporal localization information. Action recognition is typically applied in scenarios where understanding the overall action category is enough, such as video tagging, content-based video retrieval, and activity monitoring.

What is Action Detection?
Goal
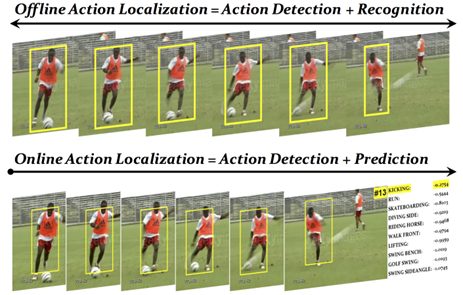
Action detection is the next step up from action recognition. Here, the algorithm recognizes actions AND localizes the temporal segments within the video where the actions occur.
Output
The output of action detection includes both the classification of actions and the temporal localization information, providing readings of timing and duration for each action instance. Action detection is used in applications where it is necessary to know when and where actions occur within the video. This could include surveillance systems, human-computer interaction, sports analysis, and autonomous driving.
Networks for Fine-Grained Action Detection” – source.
What is Action Localization?
Goal
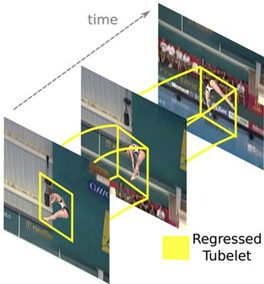
Finally, action localization is the step above action detection. This is the process of identifying and localizing the temporal and spatial extent of specific actions in video sequences, aka determining the actions present in a video as well as where and when they occur.
Output
The output of action localization algorithms can look like temporal segments or bounding boxes, indicating time intervals and spatial regions of actions within videos. This is useful for tasks such as event detection and behavior analysis.
- Spatial Understanding identifies the location of the action in a video frame. This is done by drawing bounding boxes around the actors or objects involved in the action.
- Temporal Understanding determines the duration of the action in a video sequence. This aids in understanding the action context and differentiating it from similar actions occurring before or after.
Implementing Action Localization
Before deep learning took center stage in action localization, older, more traditional methods were used. These methods captured motion patterns or spatial characteristics, which were relevant to specific actions.
- The Sliding Window approach scans the video frame-by-frame, analyzing each frame for the presence of the target action.
- The Feature-Based Methods approach extracts various features like motion vectors, optical flow, or histograms of gradients from each frame, instead of analyzing raw frames directly.
These more traditional methods represented some limitations in representational power, manual feature engineering requirements, scalability issues, and the emergence of deep learning techniques. Often, these traditional methods can have problems capturing complex spatial-temporal patterns, in turn requiring some feature engineering while also struggling with scalability and efficiency.
In contrast, deep learning models, particularly recurrent and convolutional neural networks (CNNs), offer automatic feature learning from raw video data. Thus, enabling end-to-end learning and better data use.
Next, we’ll take a look at several deep learning models you can use to get started with action localization.
Deep Learning Models for Action Localization
C3D
This architecture was inspired by the deep learning breakthroughs in the image domain. While 2D CNNs (ConvNets) dominate image processing, they struggle with video analysis. 2D CNNs applied to individual video frames are effective for action recognition. However, they cannot capture motion dynamics and interaction between frames, limiting their accuracy and practicality.
The C3D paper details how it uses 3D ConvNets to learn spatiotemporal features, in contrast to 2D ConvNets, which discard the temporal aspect of video. However, in 3D CNNs the filter not only slides in the X and Y direction but also in an extra dimension: time. The key advantage here with 3D ConvNet is that it allows one to model the dynamics of an action. C3D trained on the Sports-1M dataset scored a 90.4 % accuracy on action recognition results on the UCF101 dataset.
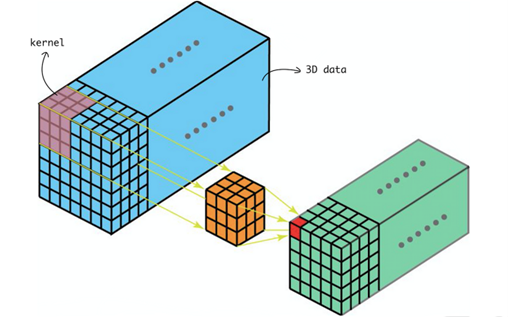
C3D Model Architecture

- Input and Encoding: Video clips of fixed size are fed into the network. Five 3D convolutional layers with 3x3x3 kernels process these clips. These kernels act as feature detectors, scanning the spatiotemporal neighborhood of each video frame to extract local features like motion patterns, object shapes, and color changes. Each layer extracts increasingly complex features by combining lower-level features, building a hierarchical representation of the video content.
- Pooling and Downsampling: Five Max pooling layers downsample the spatial and temporal resolution of the feature maps. This reduces the network complexity and computational cost while retaining essential information.
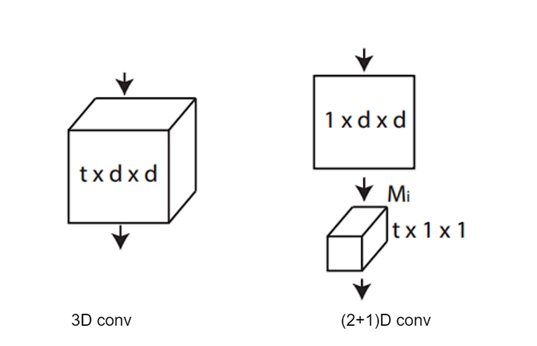
R(2+1)D
3D CNNs outperformed 2D CNNs in terms of action recognition; however, using the R(2+1)D architecture further improves the accuracy and reduces the computational cost.
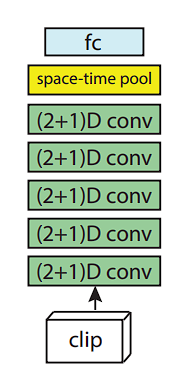
- 2D Convolution: Focuses on extracting spatial features within each frame. Imagine analyzing textures, shapes, and object relationships within a single still image.
- 1D Convolution: Captures the evolution of these features across subsequent frames by analyzing how the spatial elements change and interact over time, revealing the motion dynamics.
- Residual Connections (Optional): Inspired by ResNet, R(2+1)D incorporates residual connections that directly add the input to the output of each convolutional layer. This helps alleviate the vanishing gradient problem, allowing the network to learn deeper and more complex temporal relationships.
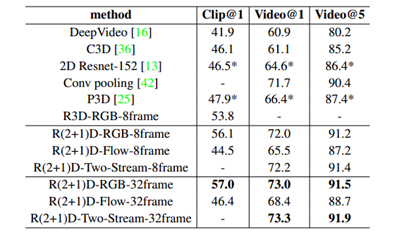
Benefits of R(2+1)D
- Improved Accuracy: By explicitly modeling both spatial and temporal information, R(2+1)D achieves significantly higher accuracy compared to 2D CNNs for action recognition tasks.
- Computational Efficiency: Decomposing the 3D convolution into separate 2D and 1D steps reduces computational cost compared to directly employing a full 3D convolution.
- Flexibility: The R(2+1)D framework can be readily adapted to different types of action recognition tasks and video lengths.
YOWO (You Only Watch Once)

The idea behind YOWO arises from the human visual cognitive system. This theory explains that to understand the action being performed, humans relate the current frame to the knowledge from the previous frames saved in memory.
YOWO architecture is a single-stage network with two branches. One branch extracts the spatial features of the keyframe (i.e., current frame) via a 2D-CNN.
The second branch models the spatiotemporal features of the clip consisting of previous frames via a 3D CNN. Once the 2D-CNN and 3D-CNN have extracted the features, they are aggregated using a channel fusion, using an attention mechanism.
The YOWO architecture can be divided into four major parts:
- 3D-CNN branch
- 2D-CNN branch
- CFAM
- Bounding box regression
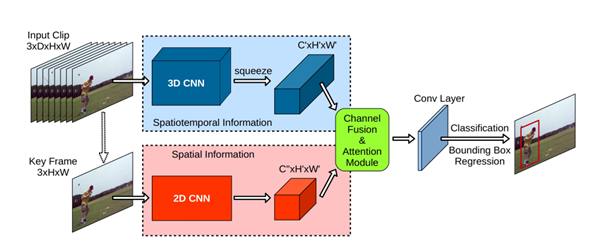
Benefits of YOWO
YOWO boasts a unique architecture and improved action localization.
- Real-Time Performance: The lightweight design and efficient processing enable real-time action localization on GPUs, opening doors for applications like computer vision for augmented and virtual reality.
- Improved Accuracy: YOWO achieves state-of-the-art performance on various benchmarks, demonstrating its effectiveness in pinpointing actions accurately.
- Simplicity and Flexibility: The unified architecture streamlines the process and eliminates the need for separate networks and fusion techniques, making it easier to understand and adapt.

Application of Action Localization
Action localization plays a crucial role in various applications, and its importance is only growing as technology advances.
Videos
- Search and Retrieval: Search through hours of video footage to find a specific clip. E.g., a car accident or a baby taking its first step.
- Video Summarization: Automatically generate summaries of lengthy videos by identifying what actions were being performed.
- Video Analysis and Annotation: Used to automatically annotate videos with labels describing the actions that occur. Crucial for creating large datasets, a human must sit and annotate each frame individually (aka segmenting out the object and describing the action of the object). This makes data creation difficult and expensive.
Robotics

- Object Manipulation: Robots using action localization can identify and interact with objects based on the actions they are performing.
- Navigation and Obstacle Avoidance: By understanding the actions of people and objects around them, robots can move through their environment more safely and efficiently. For example, a robot might avoid a moving car or stop if it sees someone crossing its path.
Surveillance and Anomaly Detection
- Security Monitoring: Action localization can be used to automatically detect suspicious activity in video surveillance footage. For example, the system can identify someone climbing a fence or breaking into a building. The system will send an alert to the owner and possibly also send it to authorities automatically, in case the owner is on vacation or at work.
- Traffic Monitoring: By tracking the movements of vehicles and pedestrians, action localization can help to improve traffic flow and reduce accidents. By tracking the movements of vehicles and pedestrians, action localization systems can provide real-time data on traffic density, lane changes, and potential hazards. This information can be fed into traffic management systems to optimize traffic lights, send out congestion alerts, and even avoid bottlenecks by rerouting vehicles.
- Accident Prevention: By analyzing vehicle behavior, action localization systems can detect sudden braking, swerving, or unsafe lane changes. This information can create alerts sent to drivers or traffic police. For example, if someone is breaking the law by driving irresponsibly, other drivers can be alerted.

Challenges of Action Localization
Action localization, despite its exciting potential, faces several challenges that prevent it from achieving perfect accuracy and smooth performance.
Variability
- Appearance: Actions can manifest in diverse ways depending on context, environment, and individual actors. A person “running” might jog leisurely in a park or sprint frantically in a chase scene. It becomes difficult as the variability increases
- Dynamics: The duration and timing of actions can vary significantly. A “handshake” might be a quick greeting or a prolonged, formal exchange. Capturing these temporal variations and distinguishing them from similar, brief interactions like high-fives or fist bumps.
Occlusion
- Partial Visibility: Actors and objects involved in actions can be partially hidden by other objects or scene elements.
- Background Clutter: Complex backgrounds with overlapping and moving objects can confuse the model and lead to misinterpretations.

Ambiguity
- Similar Actions: Certain actions are visually similar and can be easily confused. Walking and running, sitting and crouching, or hugging and grabbing someone’s arm can pose challenges for model differentiation.
Technical Limitations
- Computational Cost: Accurately identifying and localizing actions can be computationally expensive, especially for real-time applications like video surveillance.
- Data Limitations: Training robust action localization models requires large datasets of annotated videos containing diverse actions and scenarios. The availability of the dataset plays a huge role in the model’s performance.
Areas of Progress
The field of action localization is rapidly changing with exciting advancements in what’s possible to pinpoint the precise moments and locations of actions within videos. Here are some key areas of progress and promising future directions:
- Deep Learning: Powerful deep learning architectures like 3D CNNs, recurrent neural networks, transformers, and spatio-temporal graph convolutional networks capture increasingly complex spatio-temporal features, leading to significant improvements in localization accuracy.
- Weakly Supervised Learning: Leveraging unlabeled data for training reduces the need for expensive frame-level annotations, leading to larger datasets.
- Ensemble Methods: Combining the strengths of multiple models with different approaches can enhance overall performance and robustness, leading to more accurate and reliable localization results.
Future Directions
In future research, we expect to see a significant focus on effectively localizing actions that involve multiple actors, interactions, or complex dynamics. This area of study will improve the ability to pinpoint actions amidst highly detailed scenarios. In the meantime, real-time applications of action localization remain under development, particularly in fields such as autonomous vehicles, surveillance systems, and human-computer interaction. Achieving real-time capabilities here will require ongoing advancements in model efficiency and access to computational resources to process data promptly.
Additionally, there is growing interest in cross-modality fusion, which involves integrating visual information with other modalities like audio or text. This integration could have the propensity to better inform our understanding of actions and improve localization accuracy by considering multiple sources of data simultaneously. With cross-modality fusion, researchers look to utilize the complementary nature of different modalities to provide a more comprehensive view of actions in various contexts.