
Cybersecurity efforts aim to protect computing systems from digital attacks, which are a rising threat in the Digital Age. Adversarial machine learning, a technique that attempts to fool models with deceptive data, is a growing threat in AI and machine learning.
What is Adversarial Machine Learning?
Adversarial machine learning is a machine learning method that aims to trick machine learning models by providing deceptive input. Hence, it includes both the generation and detection of adversarial examples, which are inputs specially created to deceive classifiers.
Such attacks, called adversarial machine learning, have been extensively explored in some areas, such as image classification and spam detection.

The most extensive studies of adversarial machine learning have been conducted in the area of image recognition, where modifications are performed on images that cause a classifier to produce incorrect predictions.
An adversarial attack is a method to generate adversarial examples. Hence, an adversarial example is an input to a machine learning model that is purposely designed to cause a model to make a mistake in its predictions despite resembling a valid input to a human.
Whitebox vs. Blackbox Attacks
A white-box attack is a scenario where the attacker has complete access to the target model, including the model’s architecture and its parameters.
A black box attack is a scenario where an attacker has no access to the model and can only observe the outputs of the targeted model.
The Threat of Machine Learning Adversarial Attacks
With machine learning rapidly becoming core to organizations’ value proposition, the need for organizations to protect it is growing fast. Hence, Adversarial Machine Learning is becoming an important field in the software industry.
Google, Microsoft, and IBM have started to invest in securing machine learning systems. In recent years, companies heavily invested in machine learning – Google, Amazon, Microsoft, and Tesla – faced some adversarial attacks.

Moreover, governments start to implement security standards for machine learning systems, with the European Union even releasing a complete checklist to assess the trustworthiness of machine learning systems (Assessment List for Trustworthy Artificial Intelligence – ALTAI).
Gartner, a leading industry market research firm, advised that “application leaders must anticipate and prepare to mitigate potential risks of data corruption, model theft, and adversarial samples”.
Recent studies show that the security of today’s AI systems is of high importance to businesses. However, the emphasis is still on traditional security. Organizations seem to lack the tactical knowledge to secure machine learning systems in production. The adoption of a production-grade AI system drives the need for Privacy-Preserving Machine Learning (PPML).
How Adversarial AI Attacks on Systems Work
There is a large variety of different adversarial attacks that can be used against machine learning systems. Many of these work on deep learning systems and traditional machine learning models such as Support Vector Machines (SVMs) and linear regression.
Most adversarial attacks usually aim to deteriorate the performance of classifiers on specific tasks, essentially to “fool” the machine learning algorithm.
Adversarial machine learning is the field that studies a class of attacks that aim to deteriorate the performance of classifiers on specific tasks. Adversarial attacks can be mainly classified into the following categories:
- Poisoning Attacks
- Evasion Attacks
- Model Extraction Attacks
Poisoning Attacks
The attacker influences the training data or its labels to cause the model to underperform during deployment. Hence, Poisoning is essentially adversarial contamination of training data.
As ML systems can be re-trained using data collected during operation, an attacker may poison the data by injecting malicious samples during operation, which subsequently disrupt or influence re-training.
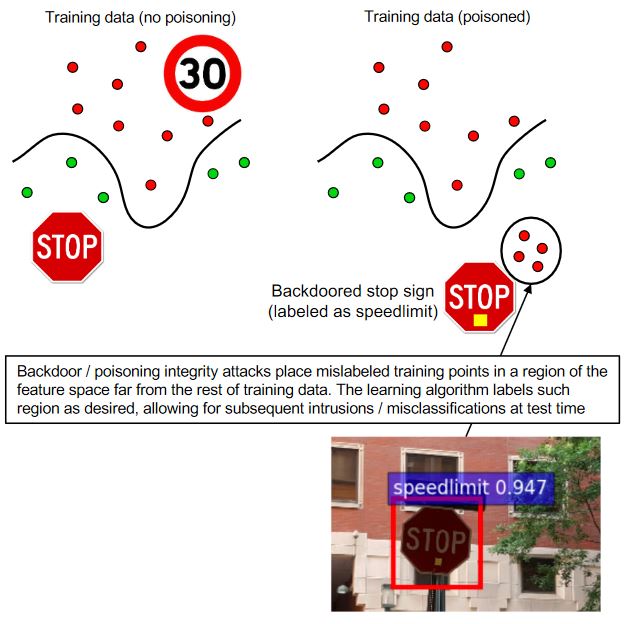
Evasion Attacks
Evasion attacks are the most prevalent and most researched types of attacks. The attacker manipulates the data during deployment to deceive previously trained classifiers. Since they are performed during the deployment phase, they are the most practical types of attacks and the most commonly used attacks in intrusion and malware scenarios.
The attackers often attempt to evade detection by obfuscating the content of malware or spam emails. Therefore, samples are modified to evade detection as they are classified as legitimate without directly impacting the training data. Examples of evasion are spoofing attacks against biometric verification systems.
Model Extraction
Model stealing or model extraction involves an attacker probing a black box machine learning system in order to either reconstruct the model or extract the data it was trained on. This is especially significant when either the training data or the model itself is sensitive and confidential.
Model extraction attacks can be used, for instance, to steal a stock market prediction model, which the adversary could use for their financial benefit.
Adversarial Machine Learning: Methods and Examples
Adversarial examples are inputs to machine learning models that an attacker has purposely designed to cause the model to make a mistake. An adversarial example is a corrupted version of a valid input, where the corruption is done by adding a perturbation of a small magnitude to it.
This barely noticed nuisance is designed to deceive the classifier by maximizing the probability of an incorrect class. The adversarial example is designed to appear “normal” to humans but causes misclassification by the targeted machine learning model.
Following, we list some of the known current techniques for adversarial attack methods.
Limited-memory BFGS (L-BFGS)
The Limited-memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) method is a non-linear gradient-based numerical optimization algorithm to minimize the number of perturbations added to images.
- Advantages: Effective at generating adversarial examples.
- Disadvantages: Very computationally intensive, as it is an optimized method with box constraints. The method is time-consuming and impractical.
FastGradient Sign Method (FGSM)
A simple and fast gradient-based method is used to generate adversarial examples to minimize the maximum amount of perturbation added to any pixel of the image to cause misclassification.
- Advantages: Comparably efficient computing times.
- Disadvantages: Perturbations are added to every feature.
Jacobian-based Saliency Map Attack (JSMA)
Unlike FGSM, the method uses feature selection to minimize the number of features modified while causing misclassification. Flat perturbations are added to features iteratively according to the saliency value in decreasing order.
- Advantages: Very few features are perturbed.
- Disadvantages: More computationally intensive than FGSM.
Deepfool Attack
This untargeted adversarial sample generation technique aims at minimizing the Euclidean distance between perturbed samples and original samples. Decision boundaries between classes are estimated, and perturbations are added iteratively.
- Advantages: Effective at producing adversarial examples, with fewer perturbations and higher misclassification rates.
- Disadvantages: More computationally intensive than FGSM and JSMA. Also, adversarial examples are likely not optimal.
Carlini & Wagner Attack (C&W)
The technique is based on the L-BFGS attack (optimization problem), but without box constraints and different objective functions. This makes the method more efficient at generating adversarial examples; it was shown to be able to defeat state-of-the-art defenses, such as defensive distillation and adversarial training.
- Advantages: Very effective at producing adversarial examples. Also, it can defeat some adversarial defenses.
- Disadvantages: More computationally intensive than FGSM, JSMA, and Deepfool.
Generative Adversarial Networks (GAN)
Generative Adversarial Networks (GANs) have been used to generate adversarial attacks, where two neural networks compete with each other. Thereby one is acting as a generator, and the other behaves as the discriminator. The two networks play a zero-sum game, where the generator tries to produce samples that the discriminator will misclassify. Meanwhile, the discriminator tries to distinguish real samples from ones created by the generator.
- Advantages: Generation of samples different from the ones used in training.
- Disadvantages: Training a Generative Adversarial Network is very computationally intensive and can be highly unstable.
Zeroth-order Optimization Attack (ZOO)
The ZOO technique allows the estimation of the gradient of the classifiers without access to the classifier, making it ideal for black-box attacks. The method estimates gradient and hessian by querying the target model with modified individual features and uses Adam or Newton’s method to optimize perturbations.
- Advantages: Similar performance to the C&W attack. No training of substitute models or information on the classifier is required.
- Disadvantages: Requires a large number of queries to the target classifier.
What’s Next for Adversarial Machine Learning?
Machine learning presents a new attack surface and increases security risks through the possibility of data manipulation and exploitation. Organizations adopting machine learning technologies must anticipate potential risks with a strong defense strategy against data sets being corrupted, model theft, and adversarial samples.
If you want to read more about this and related topics, we recommend the following articles:
- Read about Privacy-Preserving Machine Learning (PPML) and methods
- Obfuscation techniques such as face blurring with vision recognition models
- A guide about Deep Neural Networks: The 3 popular types (MLP, CNN, and RNN)
- Supervised vs Unsupervised Learning for Computer Vision