
Privacy of Visual Data in Computer Vision
Recently, visual data has been generated at an unprecedented scale. For example, people upload billions of photos daily on social media, and a high number of security cameras capture video data.
Worldwide, there are over 770 million CCTV surveillance cameras in use. Additionally, an increasing amount of image data is being generated due to the popularity of camera-equipped personal devices.
Leverage Data Value With Deep Learning
Recent advances in deep learning methods based on artificial neural networks (ANN) have led to significant breakthroughs in long-standing AI fields such as Computer Vision, Image Recognition, and Video Analytics.
The success of deep learning techniques is directly proportional to the amount of data available for training. Hence, companies such as Google, Meta/Facebook, and Apple take advantage of the massive amounts of training data collected from their users and the immense computational power of GPU farms to deploy deep learning on a large scale.
AI vision and learning from visual data have led to the introduction of computer vision applications that promote the common good and economic benefits, such as smart transportation systems, medical research, or marketing.
Visual Data Privacy Concerns
While the utility of deep learning is undeniable, the same training data that has made it so successful also presents serious privacy issues that drive the need for visual privacy. The collection of photos and videos from millions of individuals comes with significant privacy risks.
- Permanent collection. Companies gathering data usually keep it forever. Users cannot control where or what information is gleaned from their data.
- Sensitive information. Images often contain accidentally captured sensitive data items such as faces, license plates, computer screens, location indications, and more. Such sensitive visual data could be misused or leaked through various vulnerabilities.
- Legal concerns. Visual data kept by companies could be subject to legal matters, subpoenas, and warrants, as well as warrantless spying by national security and intelligence organizations.
Privacy-Preserving Machine Learning (PPML)
While public datasets are accessible to everyone, machine learning (ML) frequently uses private datasets that can only be accessed by the dataset owner. Hence, privacy-preserving machine learning is concerned with adversaries trying to infer such private data, even from trained ML models.
- Model inversion attacks aim to reconstruct training data from model parameters, for example, to recover sensitive attributes such as gender or genotype of an individual given the model’s output.
- Membership inference attacks are used to infer whether an individual was part of the model’s training set.
- Training data extraction attacks aim to recover individual training examples by querying the model.
A general approach that is commonly used to defend against such attacks is Differential Privacy (DP), which offers strong mathematical guarantees of the privacy of the individuals whose data is contained in a database.
Methods To Prevent Privacy Breaches During Training and Inference
- Secure Enclaves. An important field of interest is the protection of data that is currently in use. Hence, enclaves have been used to execute machine learning workloads in a memory region that is protected from unauthorized access.
- Homomorphic encryption. Machine Learning models can be run on encrypted private data using homomorphic encryption, a cryptographic method that allows mathematical operations on data to be carried out on ciphertext instead of on the actual data itself.
- Secure Federated Learning. The concept of federated learning was originally proposed by Google. The main idea is to build machine learning models based on data sets that are distributed across multiple devices. With federated learning, multiple data owners can train a model collectively without sharing their private data.
- Secure multi-party computation. Privacy-preserving multi-party deep learning distributes a large volume of training data among many parties. For example, Secure Decentralized Training Frameworks (SDTF) can be used to create a decentralized network setting that does not need a trusted third-party server while simultaneously ensuring the privacy of local data with a low cost of communication bandwidth.
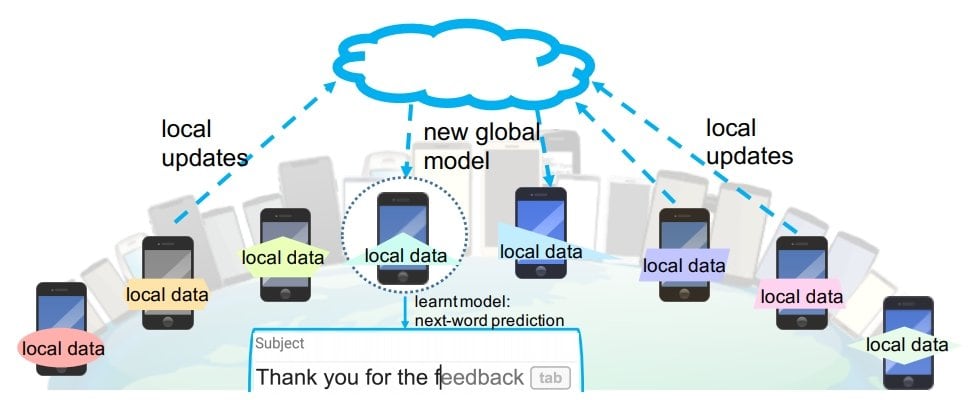
Privacy-Preserving Methods
Edge AI processing enables real-time and on-device image processing with machine learning, without sending or storing sensitive visual data. Such vision systems are fully autonomous. Private image processing using distributed edge devices can be combined with additional methods:
Image Obfuscation
Several methods have been developed to sanitize, anonymize, and protect sensitive information. Such techniques include blurring, pixelization (or mosaicing), and blacking. However, the deterministic obfuscation of traditional image privacy preservation techniques can lead to re-identification with well-trained neural networks. Recent studies show that standard obfuscation methods are ineffective due to the adaptability of convnet-based models.
In experiments, obfuscated faces could be re-identified up to 96%, and even black fill-in faces, body, and scene features could be utilized to re-identify 70% of the people. There, new image obfuscation methods were developed based on metric privacy, a rigorous privacy notion generalized from differential privacy. This allows the sharing of pixelized images with rigorous privacy guarantees by extending the standard differential privacy notion to image data, which protects individuals, objects, or their features.
Moving Objects Removal
An alternative to blurring is a method to automatically remove and inpaint faces and license plates (e.g., pedestrians, vehicles) in Google Street View imagery. A moving object segmentation algorithm was used to detect, remove, and inpaint moving objects with information from other views to obtain a realistic output image in which the moving object is not visible anymore.
Some recent datasets contain sanitized visual data. For example, nuScenes is an autonomous driving dataset where faces and license plates are detected and then blurred. Also, the public video dataset for action recognition, AViD, anonymized all the face identities to protect their privacy.
Recovering Sensitive Information in Images
Limits of Face Obfuscation
Face obfuscation does not provide any formal guarantee of visual privacy. Because both humans and machines can infer identities from face-blurred images based on context information such as height or clothing. In certain cases, both humans and machines can infer an individual’s identity from face-blurred images, presumably relying on cues such as height and clothing. The obfuscation techniques like mosaicing, pixelation, blurring, and P3 (encryption of the significant coefficients in the JPEG representation of the image) can be defeated with artificial neural networks.
Preventing Anti-Obfuscation
Methods try to protect sensitive image regions against anti-obfuscation attacks, for example, by perturbing the image adversarially to reduce the performance of a recognizer. However, they usually only work for certain recognizers, may not work for humans, and provide no privacy guarantee either.

Privacy-preserving Image-to-Text
In computer vision, the task of text recognition in images is called Optical Character Recognition (OCR) or Scene Text Recognition (STR). There is an increasing need for privacy-preserving AI analysis of text documents in image-to-text applications, mainly because such use cases often involve scanning or digitizing sensitive documents containing sensitive personal information or business secrets.
- Cryptographic Hashing: One possible way to achieve privacy-preserving OCR is to use a cryptographic hashing function to obscure the text before passing it to the OCR engine. This would prevent anyone from being able to extract the original text from the OCR output. However, this approach would not be effective against an attacker who can modify the input image.
- Differential Privacy: Another technique called Differential Privacy has been developed to implement privacy-preserving OCR that is robust against image modification attacks. A Differential Privacy system adds random noise to the data before passing it to the OCR engine, in such a way that the original data cannot be reconstructed from the noisy output. However, this comes at the cost of increased error rates in the OCR output.
- Homomorphic Encryption: There is ongoing research into developing private OCR techniques that are both accurate and robust against image modification attacks. One such method is called Homomorphic Encryption, which encrypts the input data before forwarding it to the OCR algorithm. This allows the OCR engine to perform its computations on the encrypted data, without ever decrypting it. As a result, the privacy of the input data can be maintained while the OCR engine achieves accurate results.
However, those methods are very new and have not been broadly tested. A major limitation is a significant increase in the computational workloads leading to much slower performance and the need for more expensive AI processing hardware.

Private Computer Vision in the Real World
Deep learning methods and their need for massive amounts of visual data pose serious privacy concerns, as this data can be misused. We reviewed the privacy concerns brought by deep learning and the mitigation techniques to tackle these issues. Soon, with the induction of deep learning applications in production, we expect privacy-preserving deep learning for computer vision to become a major concern with commercial impact.
If you are looking for a way to build custom, private computer vision applications for your organization, check out Viso Suite. Our computer vision infrastructure provides an end-to-end solution infrastructure to build, deploy, and scale private AI vision applications. You can securely compute and process visual data in real-time and local on-device computer vision with Edge AI, without any video upload or storage at any point in time.
We recommend you explore the following related topics:
- Learn about the differences between PyTorch vs. TensorFlow
- What is the COCO Dataset? What you need to know
- Read a Guide to Deep Reinforcement Learning