
We characterize Autoregressive Image Models (AIMs) by the probability distribution of an image. This is then decomposed into a product of conditional distributions. Each pixel or pixel group is conditioned on previously generated pixels. This sequential modeling captures the dependencies between pixels.
AIMs have become a key talking point in the world of machine learning due to the cutting-edge paper published by Apple Machine Learning. In this paper, researchers delve into the collection of different model sizes, starting from a few hundred million parameters, up to a few billion. This study aimed to visualize the training performances of the models scaled in size.
Autoregressive Models
Autoregressive models are a family of models that use historical data to predict future data points. They learn the underlying patterns of the data points and their causal relationships to predict future data points. Popular examples of autoregressive models include Autoregressive Integrated Moving Average (ARIMA) and Seasonal Autoregressive Integrated Moving Average (SARIMA). These models are mostly useful in time-series forecasting for sales and revenue.
Autoregressive Image Models
Autoregressive Image Modeling (AIM) uses the same approach but on image pixels as data points. The approach divides the image into segments and treats the segments as a sequence of data points. The model learns to predict the next image segment given the previous data point.
Popular models like PixelCNN and PixelRNN (Recurrent Neural Networks) use autoregressive modeling to predict visual data by examining existing pixel information. These models are used in applications such as image enhancement. Some of these applications include upscaling and generative networks to create new images from scratch.
While these models directly operate on pixel values, integrating the concept of latent space or latent representations can enhance their performance and efficiency.
Pre-training Large-Scale AIMs
Pre-training an AI model involves training a large-scale foundation model on an extensive and generic dataset. The training procedure can revolve around images or text, depending on the tasks the model is intended to solve.
Autoregressive image models deal with image datasets and are pre-trained on popular datasets like MS COCO and ImageNet. The researchers at Apple used the DFN dataset introduced by Fang et al. Let’s explore the dataset in detail.
Dataset
The dataset comprises 12.8 billion image-text pairs filtered from the Common Crawl dataset (text-to-image models). This dataset is further filtered to remove NSFW content, blurred faces, and duplicated images. Finally, alignment scores are calculated between the images and the captions, and only the top 15% of data elements are retained. The final subset contains 2 billion cleaned and filtered images, which the authors label as DFN 2 B.
Architecture
The training approach remains the same as that of standard autoregressive models. The input image is divided into K equal parts and arranged in a linear combination to form a sequence. Each image segment acts as a token, and unlike language modeling, the architecture deals with a fixed number of segments.

The image segments pass to a transformer architecture, which uses self-attention to understand the pixel information. All future tokens are masked during the self-attention mechanism to ensure the model does not ‘cheat’ during the training.
We use a simple multi-layer perceptron as the prediction head on top of the transformer implementation. The 12-block MLP network projects the patch features to pixel space for the final predictions. We only utilize this head during pre-training and replace it during downstream tasks according to task requirements.
Experimentation
Multiple variations of the Autoregressive Image Models were created with variations in height and depth. The models are curated with different layers and different hidden units within each layer. We summarize the combinations in the table below:
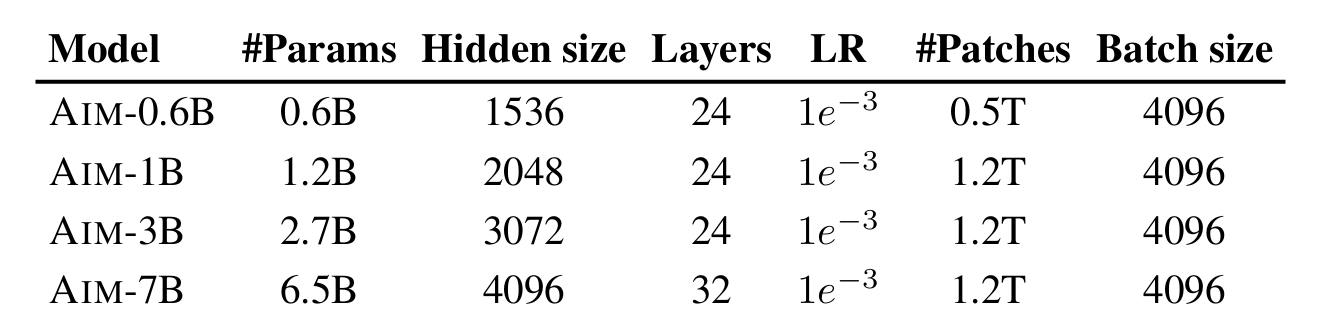
We also conduct the training on different-sized datasets, including the DFN-2B discussed above and a combination of DFN-2B and IN-1k called DFN-2B+.
Training Results
The different generation models were tested and observed for performance across several iterations. The results are as follows:
- Changing Model Size: The experiment shows that increasing model parameters slightly improves the training performance. The loss reduces quickly, and the models perform better as the parameters increase.
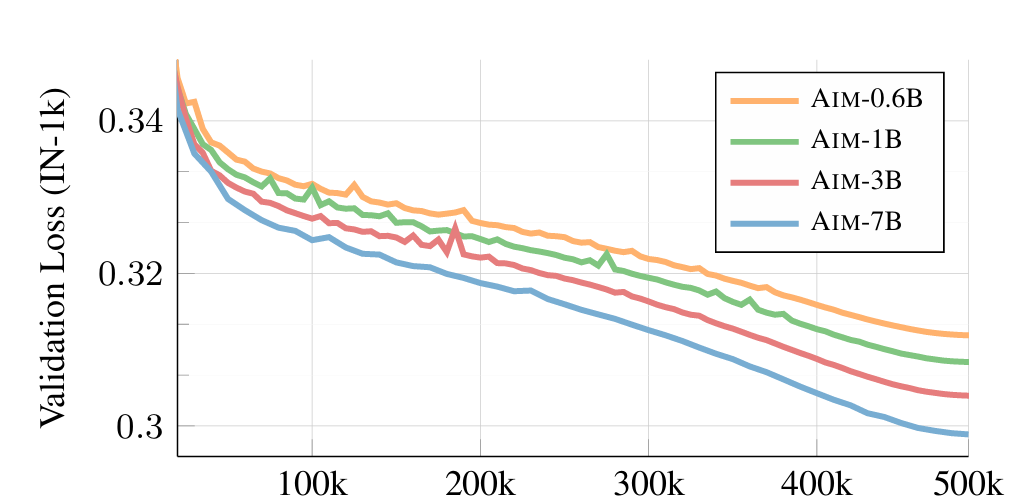
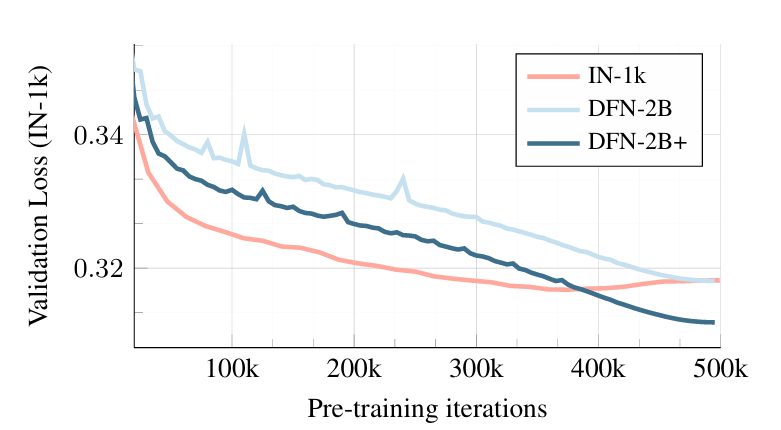
- Training Data Size: The AIM-0.6B model is trained against three dataset sizes to observe validation loss. The smallest data set IN-1k starts with a lower validation loss that continues to decrease but seems to bounce back after 375k iterations. The bounce back suggests that the model has begun to overfit.
The larger DFN-2B dataset starts with a higher validation loss and decreases at the same rate as the previous but does not suggest overfitting. A combined dataset (DFN-2B+) performs the best by surpassing the IN-1k dataset in validation loss and does not overfit.
Conclusions
The experiments’ observations concluded that the proposed models scale well in terms of performance. Training with a larger dataset (large images processed) performed better with increasing iterations. Rsearchers observed with same with increasing model capacity (increasing the number of parameters).
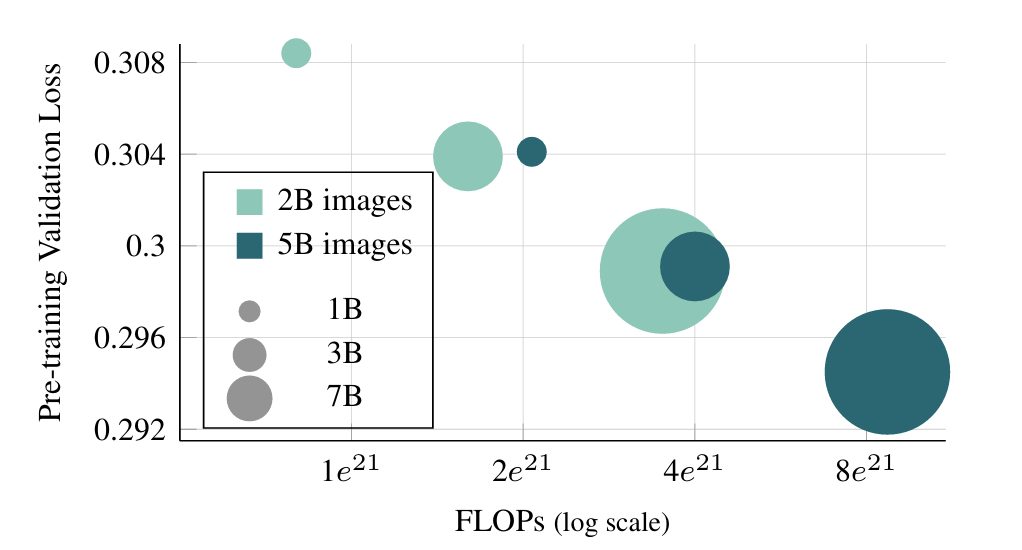
Overall, the models displayed similar traits as seen in Large Language Models, where larger models display better loss after numerous iterations. Interestingly enough, lower-capacity models trained for a longer schedule achieve comparable validation loss compared to higher-capacity models trained for a shorter schedule while using a similar amount of FLOPs.
Performance Comparison on Downstream Tasks
Researchers compared the AIMs against a wide range of other generative and autoregressive models on several downstream tasks. The results are summarised in the table below:
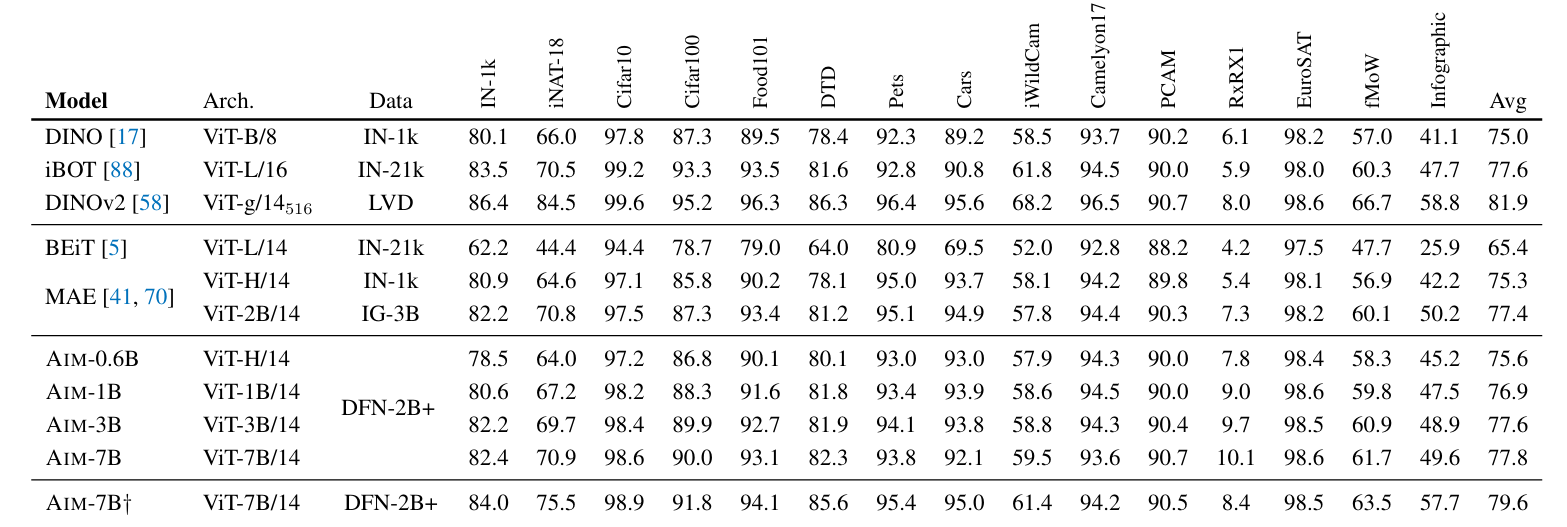
AIM outperforms most generative diffusion models such as BEiT and MAE for the same capacity or even larger. It achieves similar performance compared to the joint embedding models like DINO and iBOT and falls just behind the much more complex DINOv2.
Overall, the AIM family provides the perfect combination of performance, accuracy, and scalability.
Real-World AIM Applications
Image Generation
AIMs can assist in the process of generating images. In a method utilizing Visual Autoregressive Modeling (VAR), researchers from Peking University and Bytedance improved autoregressive image learning by allowing Autoregressive Transformers to learn visual distributions quickly and generalize well.

Image Inpainting
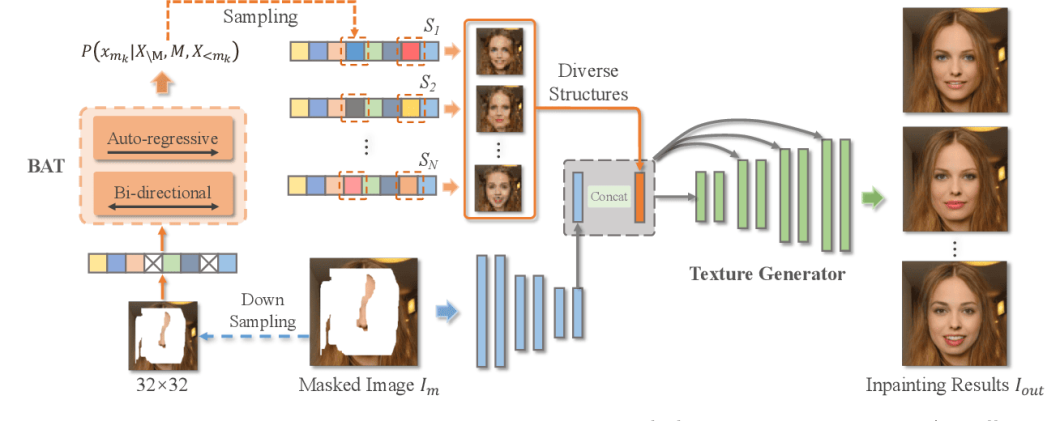
Image inpainting is the process of using AI to fill in pixel gaps within images. The model predicts pixels based on an understanding of the surrounding visual context. Researchers from Nanyang Technological University and AMO Academy (Alibaba Group) developed an approach introducing a novel Bidirectional Autoregressive Transformer (BAT) for image inpainting.
Along with Bidirectional Encoder Representations from Transformers (BERT), BAT carries out improved generation of missing pixels for better image completion.
Super-Resolution
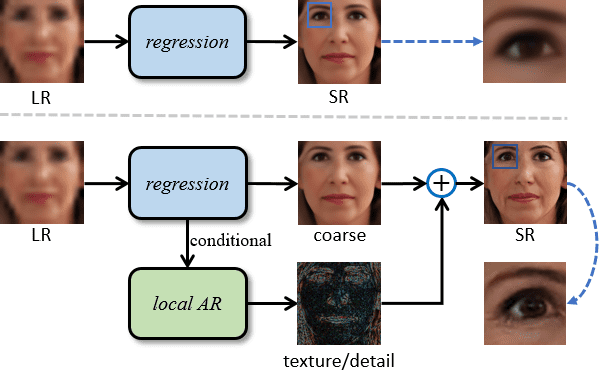
Super-resolution is the process of using AI to optimize the resolution of previously low-quality images. Researchers from the Cooperative Medianet Innovation Center at Shanghai Jiao Tong University and Shanghai AI Laboratory proposed a method that generates realistic super-resolution images with a novel local autoregressive (LAR) module. This approach, LAR-SR, is efficient and also optimizes the output based on consistent loss based on contextual pixel information.
AIM Review and Implementation
The Autoregressive Image Models (AIMs), released by Apple Research, display state-of-the-art scaling capabilities. The models are spread across different parameter counts, and each of them offers a stable pre-training experience throughout.
These AIM models use a transformer architecture combined with an MLP head for pretraining. They learn from a cleaned-up dataset from the Data Filtering Networks (DFN). The experimentation phase tested different combinations of model sizes and test sets against different subsets of the main data. In each scenario, the pre-training performance scaled quite linearly with increasing model and data size.
The AIM models have exceptional scaling capabilities as observed from their validation losses. The models also display competitive performance against similar image generation and joint embedding models and strike the perfect balance between speed and accuracy.
Further Autoregressive Image Model (AIM) Research
To dive deeper and stay up-to-date with the latest research on AIMs, we suggest checking out the following publications:
- Paper: Scalable Pre-training of Large Autoregressive Image Models (2024). Researchers at Apple published this paper highlighting key findings in AIMs. First, how visual feature performance scales with model capacity and data quantity. Second, how the object value function correlates with model performance on downstream tasks.
- Paper: Autoregressive Image Generation without Vector Quantization (2024). This paper from researchers at MIT CSAIL, Google DeepMind, and Tsinghua University proposes modeling per-token probability distribution with a diffusion procedure. This procedure allows for the application of autoregressive models in a continuous-valued space.
- Paper: Semantic-Aware Autoregressive Image Modeling for Visual Representation Learning (2023). Researchers from Megvii Technology introduced semantic-aware autoregressive image modeling to combat the lag experienced of autoregressive modeling in computer vision with self-supervised pre-training. The key finding from this research involves an autoregressive model of images from the semantic patches to the less semantic patches.
- Paper: Few-shot Autoregressive Density Estimation: Towards Learning to Learn Distributions (2018). Researchers from Google propose modifications to PixelCNN to demonstrate state-of-the-art performance. This approach combines neural attention, meta learning techniques, and autoregressive models for useful few-shot density estimation.