
When it comes to computer vision with machine learning, overfitting is one of the biggest challenges that developers face. This means that the ML model has been trained on a limited data set, and as a result, it performs extremely well on that specific data set but may not generalize well to other datasets.
Basic Concept of Overfitting
Let’s first look into what overfitting in computer vision is and why we need to avoid it. In computer vision, overfitting is a phenomenon that occurs when a machine learning algorithm begins to memorize the training data rather than learning the underlying patterns.
In consequence, this usually leads to poor performance on new data, as the algorithm is not able to generalize from the training data to other datasets. Overfitting is a common problem in machine learning, and can be caused by a variety of factors.

Underfitting vs. Overfitting in Machine Learning
In machine learning, overfitting and underfitting are two of the main problems that can occur during the learning process. In general, overfitting happens when a model is too complex for the data it is supposed to be modeling, while underfitting occurs when a model is not complex enough. Let’s take a closer look at each of these problems.
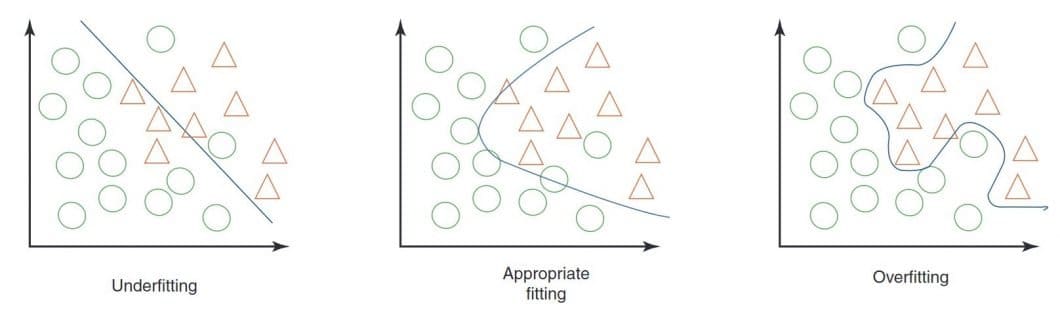
- What is Overfitting? Overfitting occurs when a model is too complex for the data it is supposed to be modeling. This can happen for a variety of reasons, but one of the most common is that the model is simply trying to learn too much from the data. When this occurs, the model ends up memorizing the training data instead of learning generalizable patterns. As a result, the model performs well on the training dataset but does not generalize well to new data.
- What is Underfitting? Underfitting, on the other hand, occurs when a model is not complex enough. While there can be different causes, it is often the case that the model is not given enough data to learn from. As a result, the model is not able to learn the generalizable patterns in the data and ends up performing poorly on both the training dataset and new data points. An underfitted model is “too simple”, with too few features and insufficient data to build an effective model. While an overfit model has low bias and high variance, an underfit model is the opposite. It shows a high bias and low variance. Adding more features to a model that is too simple can help to limit bias.
How to Tell if a Model is Overfitting or Underfitting?
So, how can you tell if your model is overfitting or underfitting? One way is to look at how well it performs on new data. If your model is overfitting, it will perform well on the training data but not so well on the test set with new data. If your model is underfitting, it will perform poorly on both the training dataset and the test set.
Another way to tell is to look at the complexity of your model. If your model is too complex, it is more likely to be overfitting. If your model is not complex enough, it is more likely to be underfitting.

What is a Good Fit in Machine Learning?
A good fit in machine learning is defined as a model that accurately predicts the output of new data. A good machine learning model that has a high accuracy is said to have a low error rate. The goal of machine learning is to build models that generalize well, which means they have a low error rate on a test set with unseen data.
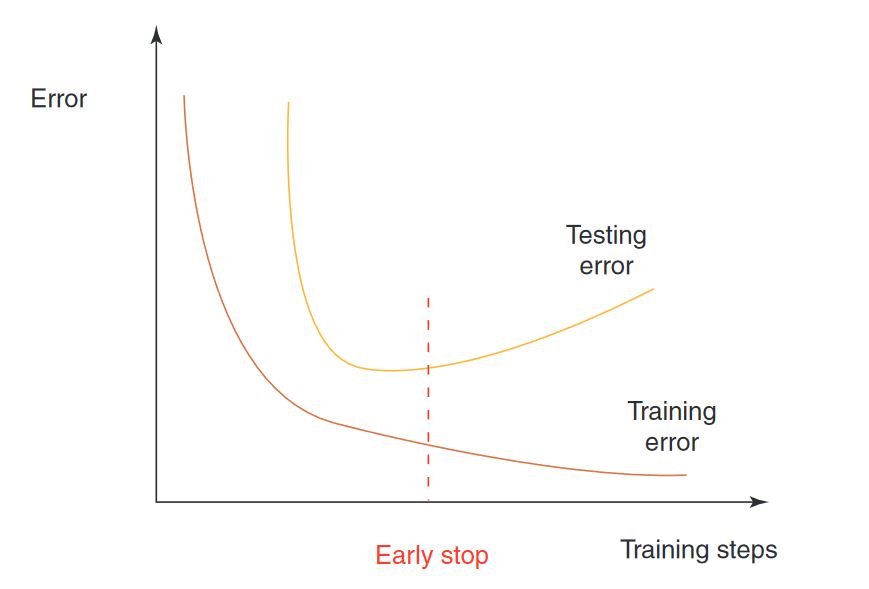
Key Statistical Concepts of Overfitting
In the following, we summarize the most important statistical concepts in overfitting.
Noise
Noise is an unexplained and random variation inherent to the data (biological noise) or introduced by variables of no interest (procedural noise, including measurement errors, and site variation).
Overfitting
Overfitting is over-learning of random patterns associated with noise or memorization in the training data. This leads to a significantly decreased ability to generalize to new validation data.
Bias
Bias quantifies the error term introduced by approximating highly complicated real-life problems with a much simpler statistical model. Machine learning models with high bias tend to underfit.
Variance
Variance refers to learning random structure irresponsible of the underlying true signal. Models with high variance tend to overfit.
Data Leakage
Data Leakage is the concept of “looking at data twice” (Contamination). Overfitting happens when observations used for testing also recur in the training process. The model then “remembers” instead of learning the underlying association.
Model Selection
Model Selection is the iterative process using resampling, such as k-fold cross-validation, to fit different models in the training set.
Resampling
Resampling methods fit a model multiple times on different subsets of the training data. Popular techniques are k-fold cross-validation and bootstrap.
k-Fold Cross-Validation
k-Fold Cross-Validation is used to divide the data into k equally sized folds/sets. Iteratively, k-1 data is used for training and evaluated on the remaining unseen fold. Each fold is used for testing once.
Model Assessment
Model Assessment is the evaluation of a model’s out-of-sample performance. This should be conducted on a test set of data that was set aside and not used in training or model selection. The use of multiple measures of performance (AUC, F1 Score, etc.) is recommended.
LOOCV (leave-one-out cross-validation)
LOOCV (leave-one-out cross-validation) is a variation of cross-validation. Each observation is left out once, and the model is trained on the remaining data and then evaluated on the held-out observation.
Bootstrap
Bootstrap allows estimating the uncertainty associated with any given model. In typically 1’000 to 10’000 iterations, bootstrapped samples are repetitively drawn with replacements from the original data, the predictive model is iteratively fit and evaluated.
Hyperparameter Tuning
Hyperparameter Tuning deals with hyperparameters that determine how a statistical model learns and have to be specified before training. They are model-specific and might include regularization parameters penalizing the model’s complexity (ridge, lasso), number of trees and their depth (random forest), and many more.
Hyperparameters can be tuned, that is, iteratively improved to find the model that performs best given the complexity of the available data.
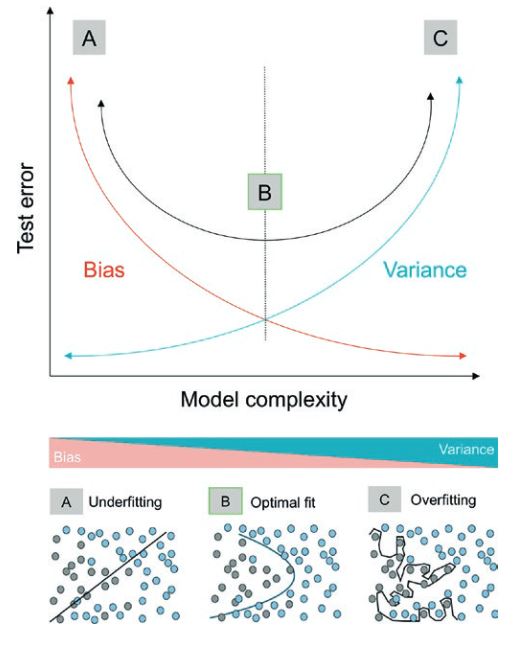
Causes of Overfitting of a Machine Learning Model
There are several causes of overfitting. The first is using too few training examples. If the model is only trained on a few examples, it is more likely to overfit.
The second cause is using too many features. If the model is trained on too many features, it can learn irrelevant details that do not generalize well to other input data.
Finally, overfitting can also be caused by using a complex model. Complex machine learning algorithms are more likely to overfit because they can learn details that are not relevant to the dataset.
There are common mistakes that drive overfitting risks:
Lack of Data Pre-processing
Data pre-processing is a crucial step in any machine learning project. Without proper pre-processing, likely, the machine learning algorithm will not work as expected. There are many ways to pre-process data, but some of the most common methods include imputation, normalization, and standardization.
Incorrect Use of Algorithms
Incorrect use of algorithms is another common mistake that machine learning practitioners make. There are many different types of machine learning algorithms, and each one is designed to solve a specific type of problem. If the wrong algorithm is used for a particular problem, it is unlikely that the desired results will be achieved.
Poor Feature Engineering
Poor feature engineering is also a common issue in machine learning. Feature engineering is the process of creating new features from existing data. This can be done in several ways, but some common methods include feature extraction and feature selection. If any of these steps are not done correctly, it is likely that the machine learning algorithm will overfit the data.
Segmentation Bias in the Training Data
Segmentation bias in the training dataset is another problem that can lead to poor machine learning results. This occurs when the training data is not representative of the entire population. This can happen for many reasons, but some common causes include sampling bias and selection bias. If the training data is not representative of the population, likely, the machine learning algorithm will likely not generalize well to new data.
To avoid these common mistakes, it is important to have a strong understanding of the machine learning process.
How to Detect an Overfit Model in Computer Vision
There are a few ways to detect overfitting in computer vision:
Cross-Validation to Evaluate Generalization
One way is to look at the generalization error of the model. If the model is overfit, then the generalization error will be high. It means that the model has been trained too well on training data and is unable to generalize. As a result, the overfit model makes inaccurate predictions when given validation data, making the computer vision model useless even though it is able to make accurate predictions for the training data.
Using cross-validation is a gold standard in applied machine learning for estimating model accuracy on unseen data. Hence, it is important to estimate and improve the accuracy of computer vision algorithms. The cross-validation technique involves splitting the sample dataset into two parts: training and testing (train-test split). The training data is used to learn the parameters of the algorithm, while the testing data (validation dataset) is used to evaluate the machine learning model’s performance.
Analyze Model Parameters
Another way to detect overfit models is by inspecting the coefficient of determination, or R-squared. If the R-squared value is too high, then the statistical model is overfit. This is because overfitting occurs when the machine learning algorithms are too complex and begin to describe the random error in the data rather than the relationships between variables.
How to detect overfitting in a nutshell:
- Look for patterns in the data that are too consistent or specific to the training set.
- Evaluate how well the model generalizes to new data (cross-validation).
- Inspect the coefficient of determination (R-squared).
Ways to Prevent Overfitting in Computer Vision
There are several ways to prevent overfitting in computer vision. The first is to use more training examples. This will help the model learn generalizable patterns during the training process.
The second is to use fewer features. As a result, the model will focus on the more important details in the dataset. Finally, you can use a simpler model. A simpler model is less likely to overfit because it cannot learn irrelevant details.
Extend the Training Dataset
The most common way to avoid overfitting is to use more training data and increase the data quality (data collection). The reason why using more data points can help to prevent overfitting in computer vision is that it gives the algorithm more information to work with in the training process, which can help to improve the accuracy of the predictions. Additionally, using more data can also help to reduce the variance in the predictions, which can lead to more stable and accurate results.
Use Fewer Features
In computer vision, using fewer features can help to avoid overfitting because it means that the model is less likely to be affected by random noise in the data. With an increasing number of features, the model is more likely to fit the noise in the data rather than the true patterns. This can lead to inaccurate predictions and limit the model’s ability to generalize to new data.
This data simplification method reduces overfitting by decreasing the complexity of overfit models. The goal is to make it simple enough that it does not overfit. This can be implemented by pruning a decision tree, or by reducing the number of parameters in a neural network.
Using a Simpler Algorithm
There is no one-size-fits-all model to avoid overfitting in computer vision. The problem will vary depending on the specific dataset and problem at hand. However, some common approaches for avoiding overfitting in computer vision include using either simpler or more sophisticated models.
In neural networks, model-based overfitting can occur when a model is configured with too many layers or too many neurons in the hidden layers (high complexity of deep neural networks). A too complex tends to learn irrelevant features.
A linear model is a good way to avoid overfitting because it makes fewer assumptions about the data than a non-linear model. A linear model is also easier to interpret and is much less complex than other methods. Linear models are often used in machine learning, where they are known as linear regression models.
Linear models are used in computer vision, where regression analysis can be used to find relationships between variables. And computer vision often relies on identifying relationships between pixels or other image features in order to perform tasks such as object detection or facial recognition.
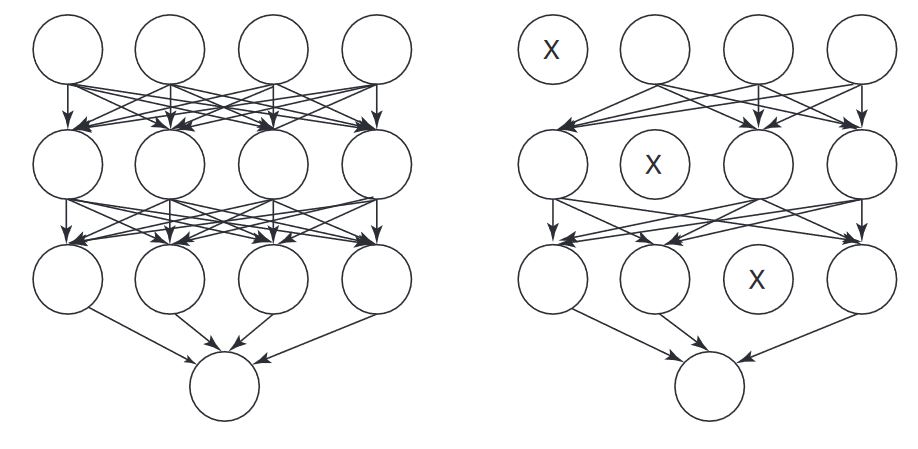
Dropout for Neural Networks
Dropout is a regularization technique to apply to a deep neural network (DNN). This is a technique where you randomly ignore some of the neurons in your network during the training phase. This forces the network to learn from different parts of the data and prevents it from overfitting.
Some examples of neural networks with dropout are the deep belief network (DBN), the convolutional neural network (CNN), and the recurrent neural network (RNN). In all of these networks, you can use dropout to prevent overfitting.
Regularize the Machine Learning Algorithm
In simple terms, regularization is tuning or selecting the preferred level of model complexity so the model achieves a better prediction performance (generalization). This is done by adding a penalty term to the cost function that is proportional to the number of parameters in the model. The penalty term is typically called the “regularization term” or “complexity penalty”.
The most common regularization methods are the Lasso and Ridge methods. The Lasso method penalizes the sum of the absolute values of the coefficients, while the Ridge method penalizes the sum of the squared values of the coefficients. Both methods help to reduce the model complexity of an overfitted model and force it to learn only the most relevant features.
Training Data Augmentation
You can also use data augmentation, which is where you artificially create more data. To augment a data set, you can generate image variations with different angles, distortions, or different lighting. For example, if you have a dataset of images of cats and dogs, you can use test data augmentation to generate new images of cats and dogs by applying random transformations to the existing images. This will help the model to learn from more data and improve the accuracy of the predictions.

Ensembling
Machine learning technique ensembling means using more than one model to make a prediction. This can be done by training several models independently and then voting on the predictions, or by averaging the predictions of multiple models. Ensembling can help to reduce overfitting by making the predictions more robust.
There are a few other methods to prevent overfitting, but these are the most common.
Examples of Overfitted Computer Vision Models
One example of overfitting in vision is exemplified when a machine learning algorithm is trained on a dataset that is too small or unrepresentative of the real-world problem.
This can cause the overfit model to perform well on the training data, and the model predicts results with over 98% accuracy. However, when applied to new data, the same model only achieves a detection accuracy of 50% because the model is too closely fit to a narrow data subset.
Overfitting is a particularly important problem in real-world applications of image recognition systems, where deep learning models are used to solve complex object detection tasks. Often, ML models do not perform well when applied to a video feed sent from a camera that provides “unseen” data. Overfitting can cause the machine learning model to become very inaccurate and provide output data with false-positive or false-negative detections.
Final Thoughts on Overfitting in Computer Vision
Overfitting is a common issue in data science, which occurs when a statistical model fits exactly against its training data. As a result, an algorithm can not perform accurately against an unseen set of data, and the model becomes ineffective.
In computer vision applications, data scientists can prevent overfitting by increasing the number of data samples, reducing model complexity, and using sophisticated models with dropout, cross-validation, regularization, or data augmentation.
If you are looking for a powerful end-to-end platform that provides infrastructure and tools to prevent overfitting effectively, check out Viso Suite. You find the Whitepaper here.
Thanks for reading! Check out other articles about related topics in data science and AI vision: