
Model drift is an umbrella term encompassing a spectrum of changes that impact machine learning model performance. Two of the most important concepts underlying this area of study are concept drift vs data drift.
These phenomena manifest when certain factors alter the statistical properties of model inputs or outputs. In most cases, this necessitates updating the model to account for this “model drift” to preserve accuracy.
A deep learning model using TensorFlow or facial recognition might experience data drift due to poor lighting or demographic changes. These changes in the input data may degrade its effectiveness in specific scenarios or as a function over a period of time.
Similarly, a financial forecasting model built on XGBoost might experience concept drift as economic indicators change over time. Researchers or developers thus need to continuously recalibrate the model to make accurate predictions under new economic conditions.
Understanding Drift in AI Systems
Addressing the challenges drift poses is paramount in a wide range of applications. For instance, in autonomous vehicles, accurate real-time decision-making is critical under dynamic and challenging circumstances. In healthcare diagnostics, on the other hand, patient outcomes may depend on the reliability of disease prediction models. Both applications are also subject to continuous change along with the evolution of our technology, understanding, and operating conditions.
Leveraging drift detection frameworks like scikit-multiflow or TensorFlow Model Analysis enables proactive model management. This helps ensure artificial intelligence systems remain robust, accurate, and reliable amidst the dynamic landscapes they operate within.
Concept Drift: Definition and Implications
Concept drift is when the statistical properties of the target variable, or the relationship between input and output, change over time. It works against the assumption of stationary data distributions underlying most predictive models. AI model accuracy may decrease as the learned patterns become less representative of current data.
The causes of concept drift are diverse and depend on the underlying context of the application or use case. For example, evolving customer behaviors in retail, shifts in financial markets, or the emergence of new disease strains.
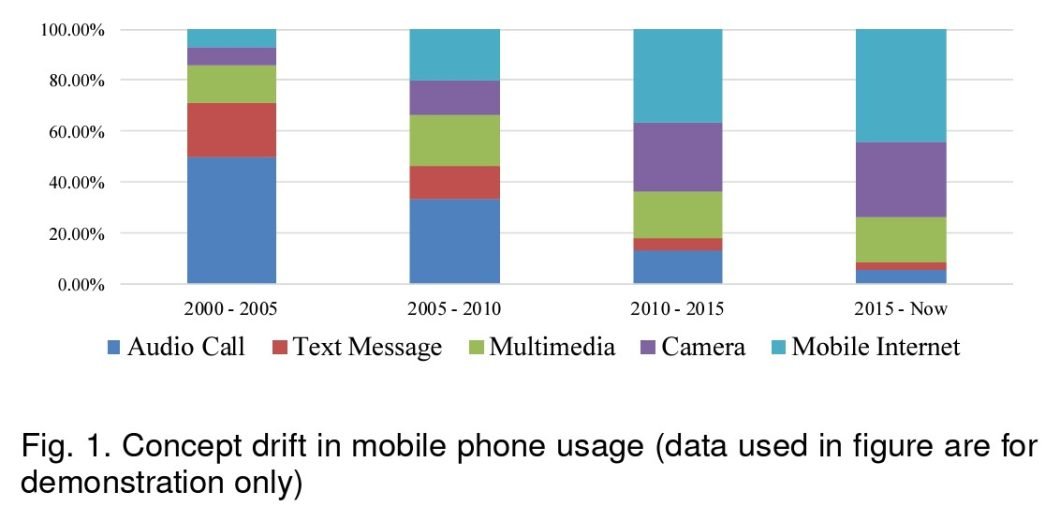
The impact of concept drift on model performance is potentially significant. As highlighted in “A Survey on Concept Drift Adaptation” by Gama et al., models like ADWIN (Adaptive Windowing) may dynamically adjust to data changes. This ensures that the predictive model remains accurate over time. Without such adaptive mechanisms, models can quickly become obsolete, leading to poor decision-making and inefficiencies.
The study “Learning under Concept Drift: A Review” provides concrete evidence of the critical impact of concept drift on the performance of machine learning models. It finds that a model may become significantly less predictive or even obsolete if the issue isn’t addressed adequately.
The paper emphasizes the importance of incorporating adaptive learning algorithms and drift detection techniques. This includes methodologies such as online learning and ensemble methods. These techniques have been shown to effectively adapt models in response to changes in data distributions.
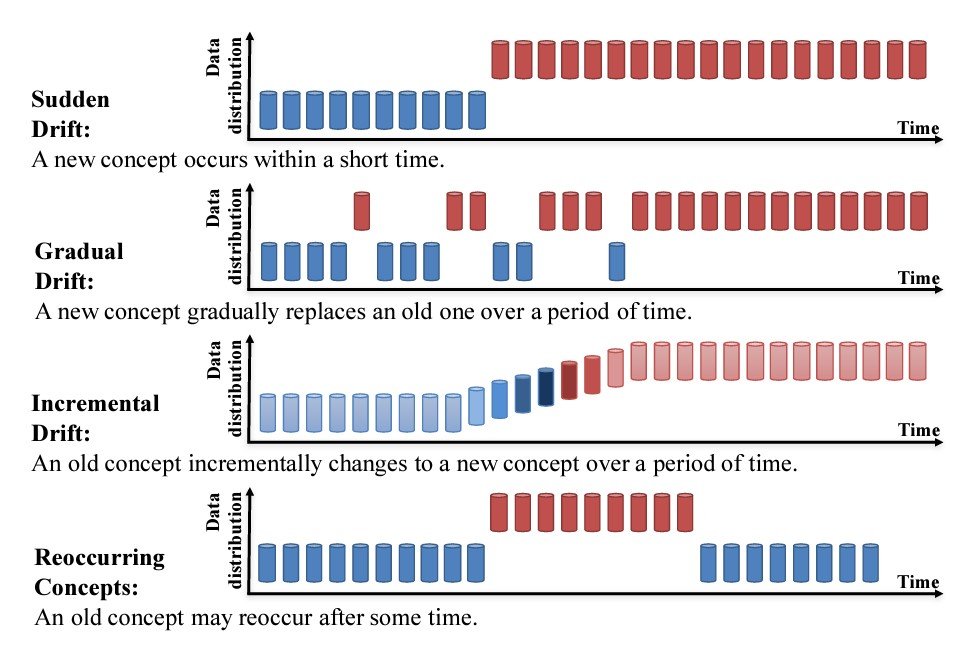
Data Drift: Definition and Implications
Data drift refers to how changes in the distribution of input data over time impact machine learning model performance. It may arise from new data sources, data collection methods, or changes in the environment or population. These changes eventually impact the predictive capabilities of models, rendering them less accurate or even irrelevant.
In computer vision, for example, data drift can significantly affect image recognition models. Changes in lighting conditions or variations in the appearance of objects can lead to decreased model accuracy. This is because the model was trained on a specific set of data that no longer represents the environment. In this case, data scientists may need to analyze and update the data used to train the model.

The “Matchmaker: Data Drift Mitigation in Machine Learning for Large-Scale Systems” study illustrates the impact of data drift in large-scale systems. It shows how models deployed in data centers experienced accuracy drops of up to 40% due to data drift.
Detecting and Measuring Drift
Detecting model drift and measuring it is vital for maintaining accuracy and robustness. Managing drift also requires an understanding of its nature and scale.
For concept drift, statistical tests like the Drift Detection Method (DDM), Early Drift Detection Method (EDDM), and ADaptive WINdowing (ADWIN) are used. These methods monitor the error rate of a model in a production environment. A significant increase in errors can signal a drift.
ADWIN, for instance, is an adaptive sliding window algorithm that automatically adjusts its size to the rate of change detected. This helps prevent false positives and accelerates the detection so that it happens sooner.
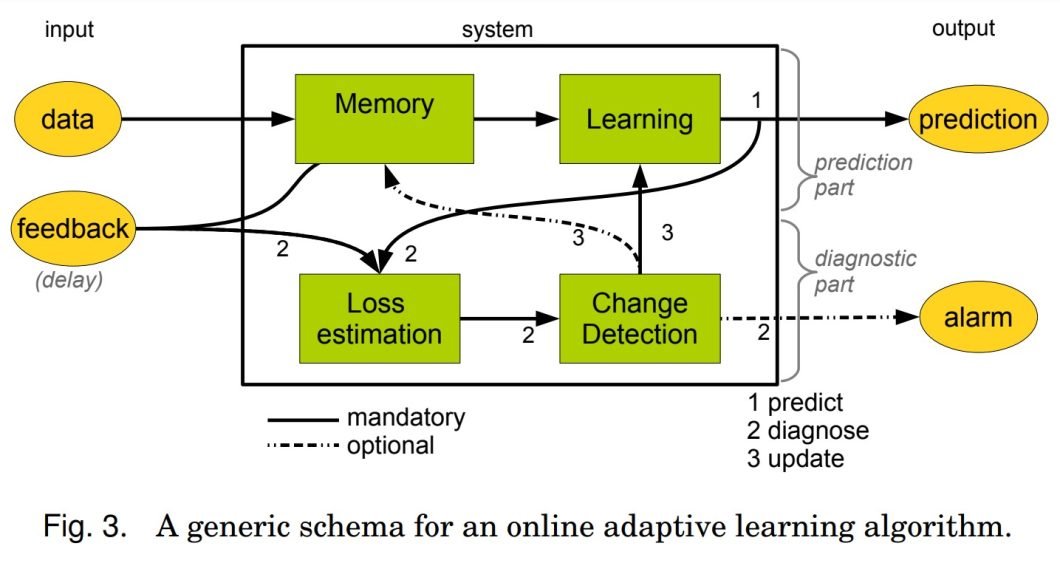
Data drift detection often involves distribution comparison tests such as the Kolmogorov-Smirnov test or the Chi-square test. These tests evaluate changes in the distribution of input features. Similarly, a significant shift in the importance of features over time may indicate a data shift.
Another potential solution is the “Matchmaker” concept. This proposal mitigates data drift by dynamically matching models to the most similar training data batch. Similar implementations may significantly improve model accuracy and reduce operational costs in real-world deployments.
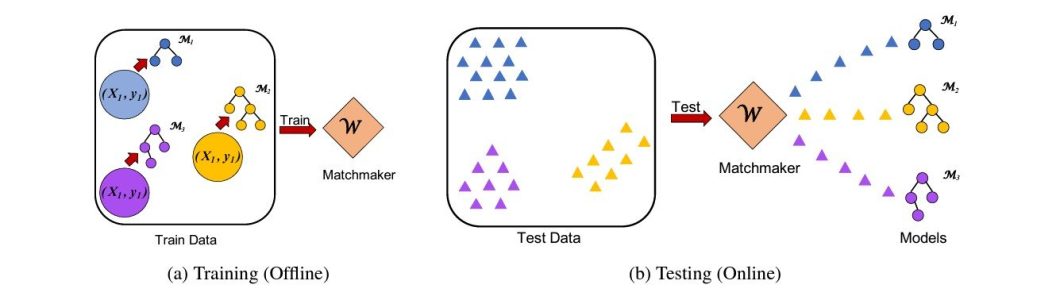
The framework also analyzes statistical similarity in performance between batches of training data and incoming data points to dynamically select the best-fitting model.
The study “Automatically Detecting Data Drift in Machine Learning Classifiers” also introduces classifier confidence scoring. By focusing on changes in classifier confidence across data sets, this approach identifies significant deviations from expected performance. This way, it can detect the early presence of data drift so that the model can be recalibrated.
Today, several libraries and platforms are equipped with drift detection capabilities. TensorFlow Model Analysis offers tools for evaluating TensorFlow models. This includes tracking performance metrics and detecting potential instances of concept and data drift.
On the other hand, Scikit-multiflow is a multi-output/multi-label and stream data mining library for Python. It provides tools and algorithms for data stream processing, which can help in drift detection.
Effective drift detection and management require a multi-faceted approach, including statistical testing, performance monitoring, and the use of specialized libraries for data stream analysis.
Reactive vs Proactive Approaches to Managing AI Drift
When it comes to drift in AI systems, there are both reactive and proactive strategies to mitigate the impact.
Reactive strategies wait until model performance has degraded before taking action. This approach typically has the benefit of being initially less resource-intensive but may lead to suboptimal performance. The model operates with reduced accuracy for some time, so it may not be suitable for high-stakes applications.
However, another benefit is that it leaves room for highly targeted adjustments based on the identified shift. Overall, this approach is ideal for stable environments where drift is infrequent or where occasional inaccuracies have minimal impact.
Proactive approaches involve regular monitoring and updates, aiming to prevent drift from affecting performance. As such, they require using more resources on a more consistent basis. The advantage is that it detects drift earlier, before a noticeable drop in performance.
It also helps mitigate the risks associated with poor model predictions in areas like healthcare or autonomous vehicles. This makes it ideal for rapidly changing environments or where predictions are critical to safety or financial outcomes.
However, there is also the risk of overfitting or unnecessarily frequent updates. So, this approach in itself may require careful tuning and readjusting over time.
How to Retrain and Update Models to Manage Drift
To adequately address drift, developers may need to update or retrain models consistently. The decision on when this should happen must balance considerations regarding the scale of the drift and the criticality of its predictions.
Models should be retrained when performance metrics indicate significant drift, with retraining frequency based on the application’s criticality.
Another approach is to use incremental learning. Hereby, the model is simply updated with new data rather than being retrained from scratch. Platforms like scikit-learn already use this practical and efficient approach.
Ensemble Methods and Model Versioning
The ensemble method involves combining multiple models to improve the overall performance in predictive modeling. Aggregating predictions can be done via a variety of techniques, such as voting or averaging, reducing prediction bias. This allows for a blend of predictions from models trained on diverse data snapshots.
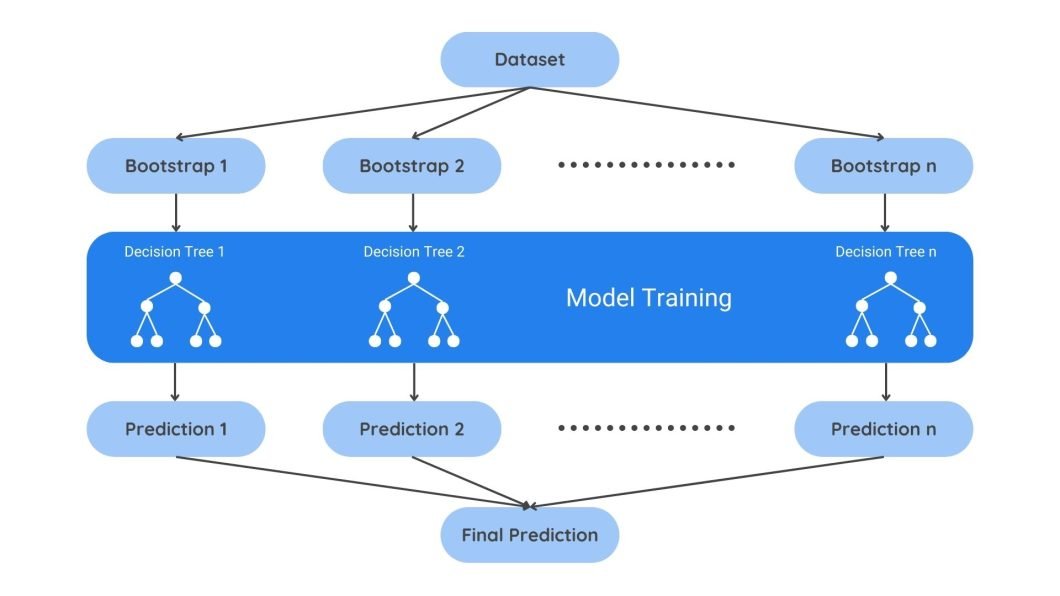
Model versioning is another crucial facet of drift management. Versioning ensures that new updates can be tracked and managed. For example, if recalibration didn’t pan out as expected, you can roll back the model to the last acceptable version.
Continuous Learning and Adaptive Models
Online learning continuously updates the model as new data becomes available. An example is the incremental batch training used by TensorFlow or tools used for stock price prediction.
On the other hand, transfer learning may help by adapting the model trained to do one task to do a related task. We’ve seen this implemented in models like BERT for Natural Language Processing (NLP) applications.
We also see adaptive learning algorithms being deployed for use cases like spam detection systems. The ability to adjust to new data patterns is key in an area like cybersecurity, where attackers are continuously employing new strategies.

Best Practices for AI System Maintenance
Maintaining AI systems and managing the effects of drift requires a proactive approach to ensure the model’s integrity:
- Frequently monitor the model’s key performance indicators and the stability of independent variables to detect early signs of model drift.
- Use established metrics, such as the Population Stability Index (PSI), to ensure an accurate understanding and response. This will also help prevent overcorrecting.
- Implement rigorous data management and quality control within the data pipeline to maintain integrity and prevent data drift.
- Develop a framework for decision-making that balances the cost of model updates against the potential performance decline due to model decay.