This article will cover image recognition, an application of Artificial Intelligence (AI), and computer vision. Image recognition with deep learning powers a wide range of real-world use cases today.
In the following, we will provide a comprehensive overview of the state-of-the-art methods and implementations of image recognition machine learning technology. Therefore, we will cover the following topics:
- What is AI image recognition? An introduction
- The basic concepts and how it works
- Traditional and modern deep learning image recognition
- The most popular image recognition algorithms
- How to use Python for image recognition
- Examples and deep learning applications
- Popular image recognition software
What is AI Image Recognition?
Image Recognition AI is the task of identifying objects of interest within an image and recognizing which category the image belongs to. Image recognition, photo recognition, and picture recognition are terms that are used interchangeably.
When we visually see an object or scene, we automatically identify objects as different instances and associate them with individual definitions. However, visual recognition is a highly complex task for machines to perform, requiring significant processing power.
Image recognition work with artificial intelligence is a long-standing research problem in the computer vision field. While different methods to imitate human vision evolved, the common goal of image recognition is the classification of detected objects into different categories (determining the category to which an image belongs). Therefore, we also refer to it as deep learning object recognition.
In past years, machine learning, in particular deep learning technology, has achieved big successes in many computer vision and image understanding tasks. Hence, deep learning image recognition methods achieve the best results in terms of performance (frames per second/FPS) and flexibility. Later in this article, we will cover the best-performing deep learning algorithms and AI models for image recognition.

Meaning and Definition of AI Image Recognition
In the area of Computer Vision, terms such as Segmentation, Classification, Recognition, and Object Detection are often used interchangeably, and the different tasks overlap. While this is mostly unproblematic, things get confusing if your workflow requires you to perform a particular task specifically.
Image Recognition vs. Computer Vision
The terms image recognition and computer vision are often used interchangeably but are different. Image recognition is an application of computer vision that often requires more than one computer vision task, such as object detection, image identification, and image classification.

Image Recognition vs. Object Localization
Object localization is another subset of computer vision often confused with image recognition. Object localization refers to identifying the location of one or more objects in an image and drawing a bounding box around their perimeter. However, object localization does not include the classification of detected objects.

Image Recognition vs. Image Detection
The terms image recognition and image detection are often used in place of each other. However, there are important technical differences.
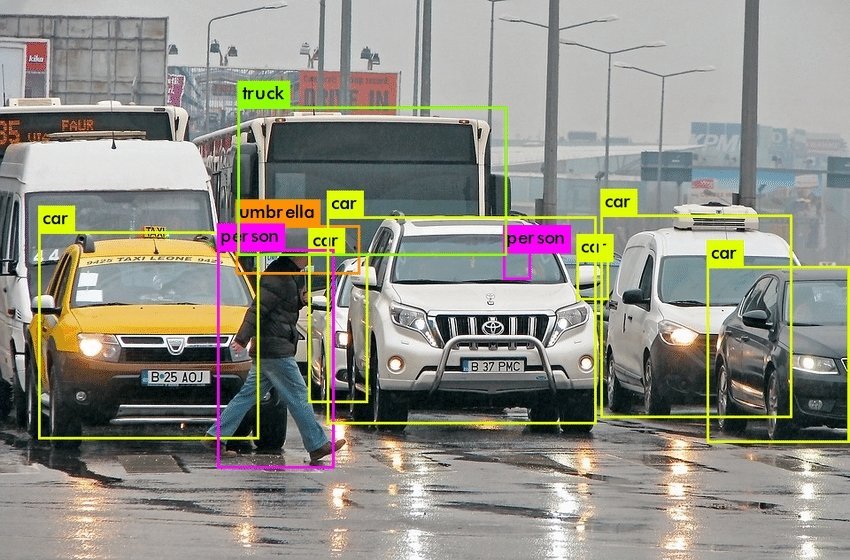
Image Detection is the task of taking an image as input and finding various objects within it. An example is face detection, where algorithms aim to find face patterns in images (see the example below). When we strictly deal with detection, we do not care whether the detected objects are significant in any way.
The goal of image detection is only to distinguish one object from another to determine how many distinct entities are present within the picture. Thus, bounding boxes are drawn around each separate object.
On the other hand, image recognition is the task of identifying the objects of interest within an image and recognizing which category or class they belong to.

How Does AI Image Recognition Work?
Using traditional Computer Vision
The conventional computer vision approach to image recognition is a sequence (computer vision pipeline) of image filtering, image segmentation, feature extraction, and rule-based classification.
However, engineering such pipelines requires deep expertise in image processing and computer vision, a lot of development time, and testing, with manual parameter tweaking. In general, traditional computer vision and pixel-based image recognition systems are very limited when it comes to scalability or the ability to reuse them in varying scenarios/locations.
Using Machine Learning and Deep Learning
Image recognition with machine learning, on the other hand, uses algorithms to learn hidden knowledge from a dataset of good and bad samples (see supervised vs. unsupervised learning). The most popular machine learning method is deep learning, where multiple hidden layers of a neural network are used in a model.

The introduction of deep learning, in combination with powerful AI hardware and GPUs, enabled great breakthroughs in the field of image recognition. With deep learning, image classification, and deep neural network face recognition algorithms achieve above-human-level performance and real-time object detection.
Still, it is a challenge to balance performance and computing efficiency. Hardware and software with deep learning models have to be perfectly aligned in order to overcome computer vision costs.
Therefore, the ability to always use the most recent algorithm has direct costing implications: The most powerful and efficient algorithm requires several times cheaper hardware or achieves several times better performance on equivalent hardware when compared to legacy algorithms.
Computer Vision Algorithm Progress
Over the years, we have seen significant jumps in computer vision algorithm performance:
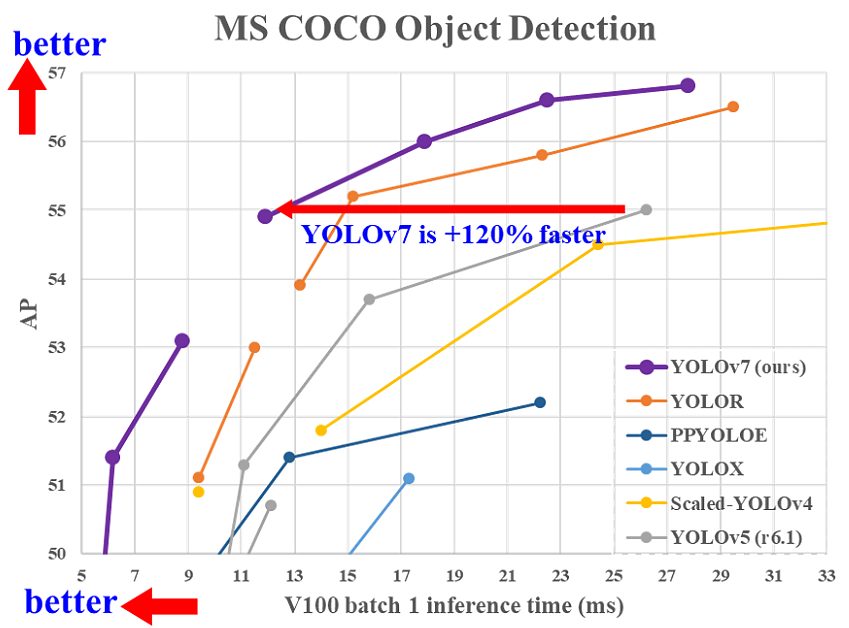
- In 2017, the Mask RCNN algorithm was the fastest real-time object detector on the MS COCO benchmark, with an inference time of 330ms per frame.
- In comparison, the YOLOR algorithm released in 2021 achieves inference times of 12ms on the same benchmark, surpassing the popular YOLOv4 and YOLOv3 deep learning algorithms.
- And in July 2022, the YOLOv7 algorithm even surpassed YOLOR significantly in terms of both speed and accuracy.
- In 2023, a newly released YOLOv8 model achieved state-of-the-art performance for real-time object detection. The powerful Segment Anything model marks the current SOTA for image segmentation.
- At the beginning of 2024, YOLOv9 was released, a new architecture for training object detection AI models.
Compared to the traditional computer vision approach in early image processing 20 years ago, deep learning requires only engineering knowledge of a machine learning tool, not expertise in specific machine vision areas to create handcrafted features. While early methods required enormous amounts of training data, newer deep learning methods only needed tens of learning samples.
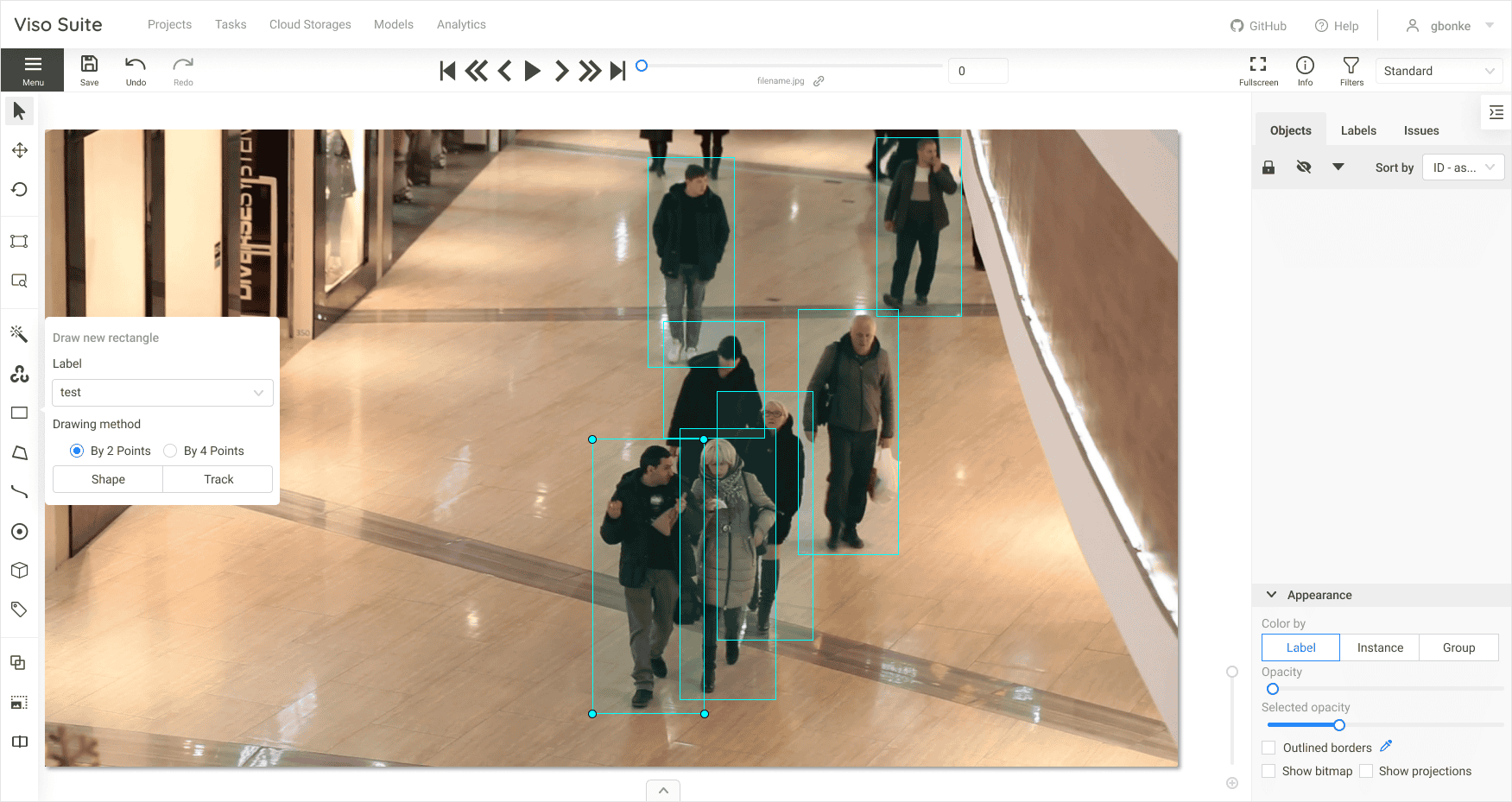
However, deep learning requires manual labeling of data to annotate good and bad samples, a process called image annotation. The process of learning from data that humans label is called supervised learning. The process of creating such labeled data to train AI models requires time-consuming human work, for example, to label images and annotate standard traffic situations for autonomous vehicles.
The Process of AI Image Recognition Systems
There are a few steps that are at the backbone of how image recognition systems work.
- Dataset with training data
The image recognition models require labeled images as training data (video, picture, photo, etc.). Neural networks need those training images from an acquired dataset to create perceptions of how certain classes look.
For example, an image recognition model that detects different poses (pose estimation model) would need multiple instances of different human poses to understand what makes poses unique from each other. - Training of Neural Networks for AI Image Recognition Online
The images from the created dataset are fed into a neural network algorithm. This is the deep or machine learning aspect of creating an image recognition model. The training of an image recognition algorithm makes it possible for a convolutional neural network image recognition to identify specific classes. Multiple well-tested frameworks are widely used for these purposes today. - AI Model Testing
The trained model needs to be tested with images that are not part of the training dataset. This is used to determine the usability, performance, and accuracy of the model. Therefore, about 80-90% of the complete image dataset is used for model training. The remaining data is reserved for model testing. The model performance is measured based on a set of parameters that indicate the percent confidence of accuracy per test image, incorrect identifications, and more. Read our article about how to evaluate the model performance in machine learning.
AI Image Recognition with Machine Learning
Before GPUs (Graphical Processing Units) became powerful enough to support massively parallel computation tasks of neural networks, traditional machine learning algorithms were the gold standard for image recognition.
Image Recognition Machine Learning Models
Let’s look at the three most popular image recognition machine learning models.
- Support Vector Machines
SVMs work by making histograms of images containing the target objects and also of images that don’t. The algorithm then takes the test picture and compares the trained histogram values with the ones of various parts of the picture to check for matches. - Bag of Features Models
Bag of Features models like Scale Invariant Feature Transformation (SIFT) and Maximally Stable Extremal Regions (MSER) work by taking the image to be scanned and a sample photo of the object to be found as a reference. The model then tries to pixel-match the features from the sample photo to various parts of the target image to see if matches are found. - Viola-Jones Algorithm
A widely used facial recognition algorithm from pre-CNN (Convolutional Neural Network) times, Viola-Jones works by scanning faces and extracting features that are then passed through a boosting classifier. This, in turn, generates several boosted classifiers to check test images. To find a successful match, a test image must generate a positive result from each of these classifiers.
Deep Learning Image Recognition Models
In image recognition, the use of Convolutional Neural Networks (CNN) is also called Deep Image Recognition. CNNs are unmatched by traditional machine learning methods. Not only are CNNs faster and deliver the best detection results in machine learning image recognition, but they can also detect multiple instances of an object from within an image, even if the image is slightly warped, stretched, or altered in some other form.

In Deep Image Recognition, Convolutional Neural Networks even outperform humans in tasks such as classifying objects into fine-grained categories, such as the particular breed of dog or species of bird.
The most popular deep learning models, such as YOLO, SSD, and RCNN, use convolution layers to parse a digital image or photo. During training, each layer of convolution acts like a filter that learns to recognize some aspect of the image before it is passed on to the next.
One layer processes colors, another layer shapes, and so on. In the end, a composite result of all these layers is collectively taken into account when determining if a match has been found.

Popular AI Image Recognition Algorithms
For image recognition or photo recognition, a few algorithms are a cut above the rest. While all of these are deep learning algorithms, their fundamental approach toward how they recognize different classes of objects varies. Let’s take a look at some of the most popular image recognition models today:
Faster Region-based CNN (Faster RCNN)
Faster RCNN (Region-based Convolutional Neural Network) is the best performer in the R-CNN family of image recognition algorithms, including R-CNN and Fast R-CNN.
It uses a Region Proposal Network (RPN) for feature detection along with a Fast RCNN for image recognition, which makes it a significant upgrade over its predecessor (Note: Fast RCNN vs. Faster RCNN). Faster RCNN can process an image under 200ms, while Fast RCNN takes 2 seconds or more.
Single Shot Detector (SSD)
RCNNs draw bounding boxes around a proposed set of points on the image, some of which may be overlapping. Single Shot Detectors (SSD) discretize this concept by dividing the image up into default bounding boxes in the form of a grid over different aspect ratios.
It then combines the feature maps obtained from processing the image at the different aspect ratios to naturally handle objects of varying sizes. This makes SSDs very flexible, accurate, and easy to train. An implementation of SSD can process an image within 125ms.
You Only Look Once (YOLO)
YOLO stands for You Only Look Once, and true to its name, the algorithm processes a frame only once using a fixed grid size and then determines whether a grid box contains an image or not.
For this purpose, the object detection algorithm uses a confidence metric and multiple bounding boxes within each grid box. However, it does not go into the complexities of multiple aspect ratios or feature maps, and thus, while this produces results faster, they may be somewhat less accurate than SSD.
A lightweight, edge-optimized variant of YOLO called Tiny YOLO can process a video at up to 244 fps or 1 image at 4 ms.
Check out our overview of YOLO models in our YOLO Explained blog.
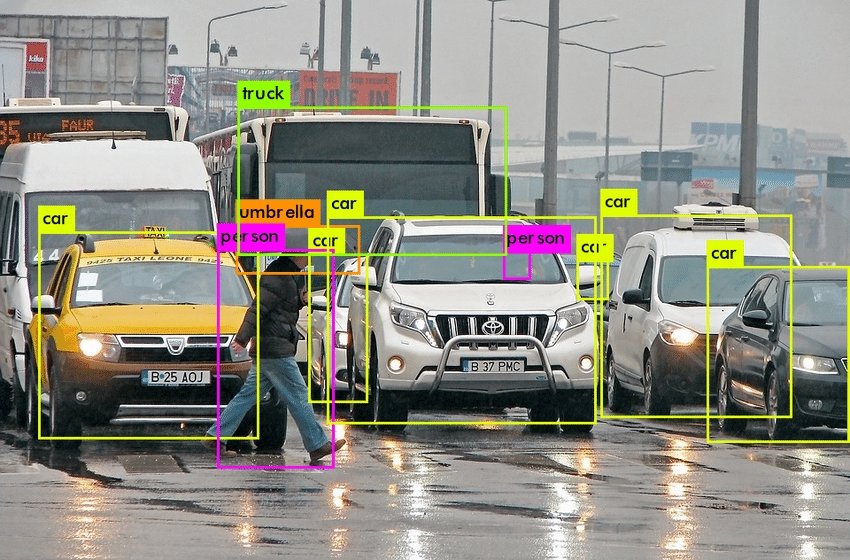
How to Apply AI Image Recognition Models
Image Recognition with Python
For image recognition, Python is the programming language of choice for most data scientists and computer vision engineers. It supports a huge number of libraries specifically designed for AI workflows, including image detection and recognition.
- Step #1: To get your computer set up to perform Python image recognition tasks, you need to download Python and install the packages needed to run image recognition jobs, including Keras.
- Step #2: Keras is a high-level deep learning API for running AI applications. It runs on TensorFlow/Python and helps end-users deploy machine learning and AI applications using easy-to-understand code.
- Step #3: If your machine does not have a graphics card, you can use free GPU instances online on Google Colab. To classify animals, there is a well-labeled dataset known as “Animals-10” that you can find on Kaggle. The dataset is free to download.
- Step #4: Once you have obtained the online dataset from Kaggle by getting an API token, you can then start coding in Python after reuploading the necessary files to Google Drive.
For more details on platform-specific implementations, several well-written articles on the internet take you step-by-step through the process of setting up an environment for AI on your machine or on your Colab that you can use.
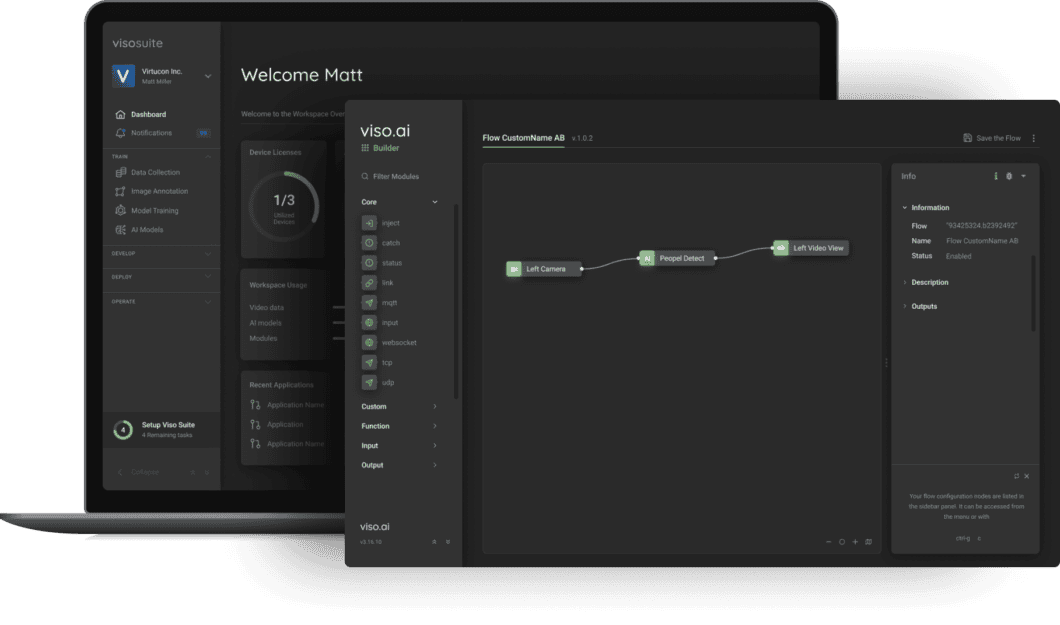
Alternatively, check out the enterprise image recognition platform Viso Suite, to build, deploy and scale real-world applications without writing code. It provides a way to avoid integration hassles, saves the costs of multiple tools, and is highly extensible.
Training a Custom Model
A custom model for image recognition is an ML model that has been specifically designed for a specific image recognition task. This can involve using custom algorithms or modifications to existing algorithms to improve their performance on images (e.g., model retraining).
While pre-trained models provide robust algorithms trained on millions of data points, there are many reasons why you might want to create a custom model for image recognition. For example, you may have a dataset of images that is very different from the standard datasets that current image recognition models are trained on.
In this case, a custom model can be used to better learn the features of your data and improve performance. Alternatively, you may be working on a new application where current image recognition models do not achieve the required accuracy or performance.
Creating a custom model based on a specific dataset can be a complex task and requires high-quality data collection and image annotation. It requires a good understanding of both machine learning and computer vision. Explore our article about how to assess the performance of machine learning models.

Image Recognition API (Cloud) vs. Edge AI
APIs provide an easy way to perform picture recognition by calling a cloud-based API service such as Amazon Rekognition (AWS Cloud). Similarly, it’s easy to use an API to recognize objects in images with the Google Vision API (Google Cloud) for tasks such as object or face detection, text recognition, or handwriting recognition.
An Image Recognition API, such as TensorFlow’s Object Detection API, is a powerful tool for developers to quickly build and deploy image recognition software if the use case allows data offloading (sending visuals to a cloud server). The use of an API for image recognition is used to retrieve information about the image itself (image classification or image identification) or contained objects (object detection).
Pure cloud-based computer vision APIs are useful for prototyping and lower-scale solutions. These solutions allow data offloading (privacy, security, legality), are not mission-critical (connectivity, bandwidth, robustness), and not real-time (latency, data volume, high costs). To overcome those limits of pure-cloud solutions, recent image recognition trends focus on extending the cloud by leveraging Edge Computing with on-device machine learning.
To learn how image recognition APIs work, which one to choose, and the limitations of APIs for recognition tasks, I recommend you check out our review of the best paid and free Computer Vision APIs.
While computer vision APIs can be used to process individual images, Edge AI systems are used to perform video recognition tasks in real time. This is possible by moving machine learning close to the data source (Edge Intelligence). Real-time AI image processing as visual data is processed without data offloading (uploading data to the cloud) allows for higher inference performance and robustness required for production-grade systems.
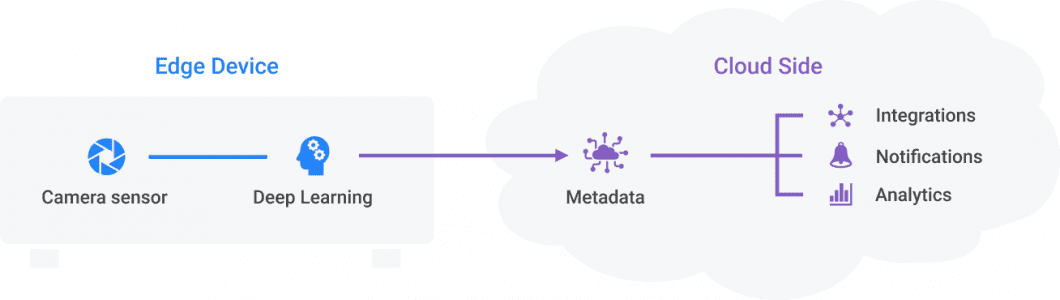
AI Image Recognition Platform
Our computer vision infrastructure, Viso Suite, circumvents the need for starting from scratch and using pre-configured infrastructure. It provides popular open-source image recognition software out of the box, with over 60 of the best pre-trained models. It also provides data collection, image labeling, and deployment to edge devices.
This AI vision platform supports the building and operation of real-time applications, the use of neural networks for image recognition tasks, and the integration of everything with your existing systems. Get a demo here.
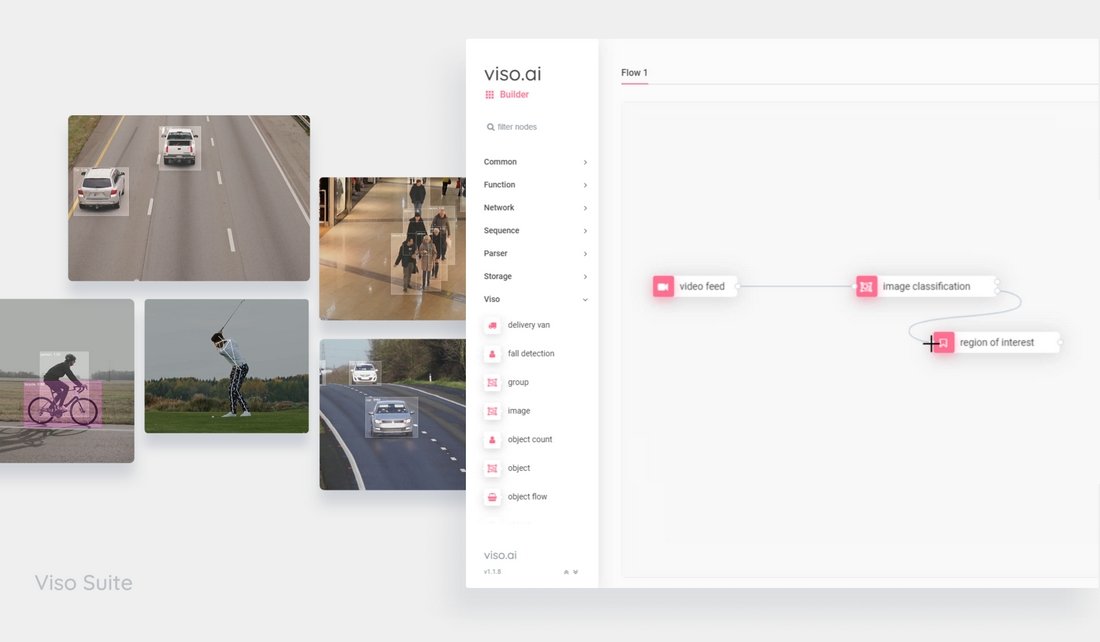
What is AI Image Recognition Used for?
In all industries, AI image recognition technology is becoming increasingly imperative. Its applications provide economic value in industries such as healthcare, retail, security, agriculture, and many more. For an extensive list of computer vision applications, explore the Most Popular Computer Vision Applications today.
Image Recognition Application for Face Analysis
Face analysis is a prominent image recognition application. Modern ML methods allow using the video feed of any digital camera or webcam. In such applications, image recognition software employs AI algorithms for simultaneous face detection, face pose estimation, face alignment, gender recognition, smile detection, age estimation, and face recognition using a deep convolutional neural network.
Facial analysis with computer vision involves analyzing visual media to recognize identity, intentions, emotional and health states, age, or ethnicity. Some photo recognition tools for social media even aim to quantify levels of perceived attractiveness with a score.
Other face recognition-related tasks involve face image identification, face recognition, and face verification, which involves vision processing methods to find and match a detected face with images of faces in a database. Deep learning recognition methods can identify people in photos or videos even as they age or in challenging illumination situations.
One of the most popular and open-source software libraries to build AI face recognition applications is named DeepFace, which can analyze images and videos. To learn more about facial analysis with AI and video recognition, check out our Deep Face Recognition article.

Image Recognition for Medical Image Analysis
Visual recognition technology is commonplace in healthcare to make computers understand images routinely acquired throughout treatment. Medical image analysis is becoming a highly profitable subset of artificial intelligence.
For example, there are multiple works regarding the identification of melanoma, a deadly skin cancer. Deep learning image recognition software allows tumor monitoring across time, for example, to detect abnormalities in breast cancer scans.
Read more about applications of image recognition in Healthcare.
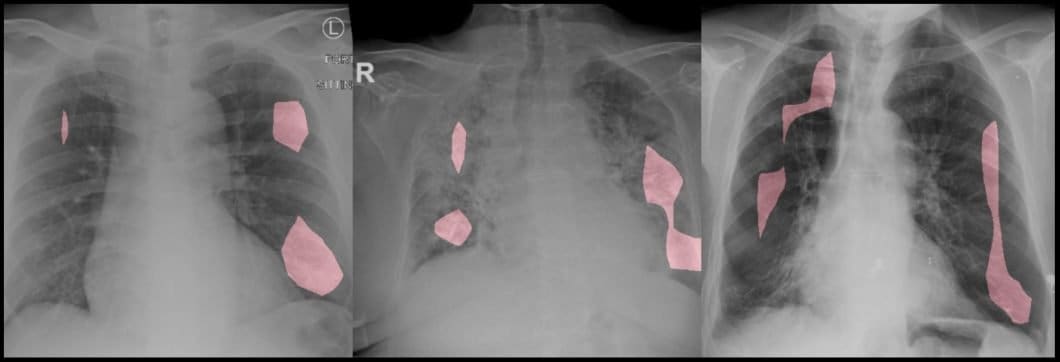
Image Recognition for Animal Monitoring
Agricultural image recognition systems use novel techniques to identify animal species and their actions. AI image recognition software is used for animal monitoring in farming. Livestock can be monitored remotely for disease detection, anomaly detection, compliance with animal welfare guidelines, industrial automation, and more.
Explore our guide about the best applications of Computer Vision in Agriculture and Smart Farming.
Pattern and Object Detection
AI photo recognition and video recognition technologies are useful for identifying people, patterns, logos, objects, places, colors, and shapes. The customizability of image recognition allows it to be used in conjunction with multiple software programs. For example, an image recognition program specializing in person detection within a video frame is useful for people counting, a popular computer vision application in retail stores.
You can learn more about cutting-edge pattern recognition and machine learning in images in our recent blog.

Automated Plant Image Identification
Image-based plant identification has seen rapid development and is already used in research and nature management use cases. A recent research paper analyzed the identification accuracy of image identification to determine plant family, growth forms, lifeforms, and regional frequency. The tool performs image search recognition using the photo of a plant with image-matching software to query the results against an online database.
Results indicate high AI recognition accuracy. 79.6% of the 542 species in about 1500 photos were correctly identified, while the plant family was correctly identified for 95% of the species.
Food Image Recognition
Deep learning image recognition of different types of food is useful for computer-aided dietary assessment. Therefore, image recognition software applications are developing to improve the accuracy of current measurements of dietary intake. They do this by analyzing the food images captured by mobile devices and shared on social media. Hence, an image recognizer app performs online pattern recognition in images uploaded by students.
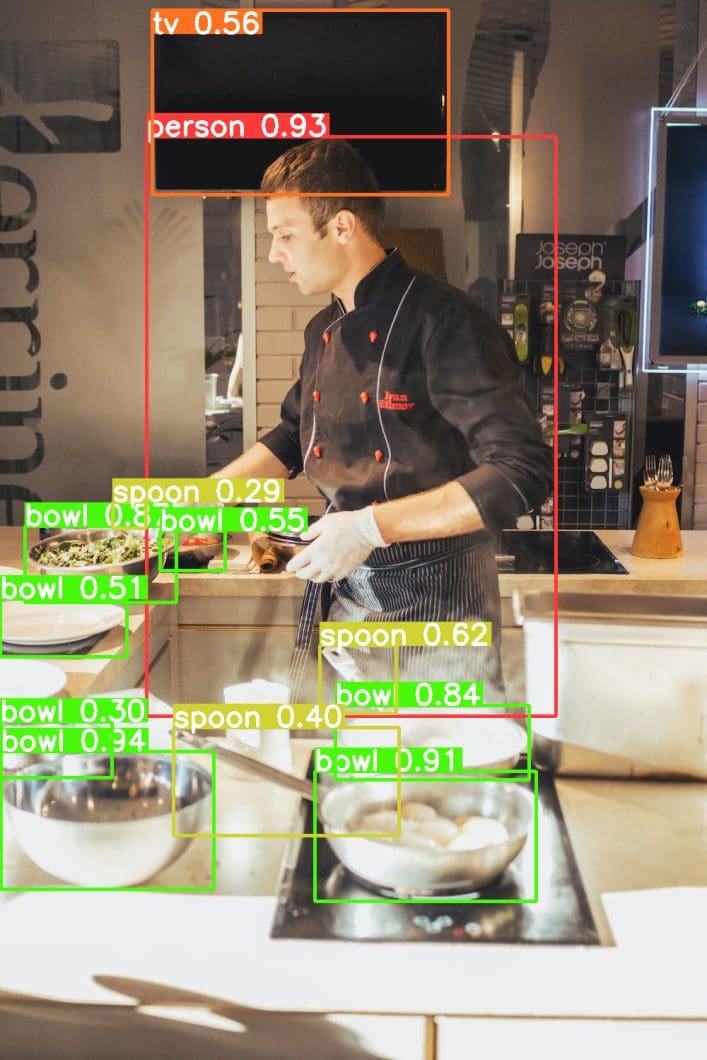
Image Search Recognition
Image search recognition, or visual search, uses visual features learned from a deep neural network to develop efficient and scalable methods for image retrieval. The goal in visual search use cases is to perform content-based retrieval of images for image recognition online applications.
Researchers have developed a large-scale visual dictionary from a training set of neural network features to solve this challenging problem.
Typical AI Image Recognition Applications
- Application #1: Industrial image recognition for defect detection and predictive analysis in manufacturing
- Application #2: Automated intrusion detection in distributed safety and surveillance systems
- Application #3: Image recognition systems for corrosion analysis and leakage detection in oil and gas
- Application #4: Photo recognition software for fraud detection in insurance
- Application #5: Real-time people counting and crowd analysis in smart cities
- Application #6: Image recognition application for weapon detection (knives, guns)
- Application #7: Self-driving cars and drones for automated navigation.

Read About Related Topics to AI Image Recognition
Currently, convolutional neural networks (CNNs) such as ResNet and VGG are state-of-the-art neural networks for image recognition. In current computer vision research, Vision Transformers (ViT) have shown promising results in Image Recognition tasks. ViT models achieve the accuracy of CNNs at 4x higher computational efficiency.
For further information about computer vision, explore related computer vision topics on our blog:
- Read about video analytics with live video streams
- Explore popular Computer Vision applications
- Object Detection – A Beginner Guide
- What is Natural Language Processing? A Guide to NLP
- From Amazon Rekognition to Facial Recognition APIs: The Top 10 Computer Vision APIs
Using AI Models to Build an AI Image Recognition System
We power Viso Suite, an image recognition machine learning software platform that helps industry leaders implement all their AI vision applications dramatically faster. We provide an enterprise-grade solution and infrastructure to deliver and maintain robust real-time image recognition systems.
Viso provides the most complete and flexible AI vision platform, with a “build once – deploy anywhere” approach. Use the video streams of any camera (surveillance cameras, CCTV, webcams, etc.) with the latest, most powerful AI models out-of-the-box.
- Viso Suite provides an all-in-one solution to build, deploy, and monitor computer vision systems.
- Use visual programming, simplified interfaces, and automated infrastructure to deliver computer vision 10x faster.
- Manage edge devices and deploy custom models or pre-trained image recognition models with one click.
- Avoid integration hassles and writing code from scratch; use pre-built applications.
Get in touch with our team and request a demo to see the key features.