
Artificial Neural Networks (ANNs) have been demonstrated to be state-of-the-art in many cases of supervised learning, but programming an ANN manually can be a challenging task. As a result, frameworks such as TensorFlow and PyTorch have been created to simplify the creation, serving, and scaling of deep learning models.
With the increased interest in deep learning in recent years, there has been an explosion of machine learning tools. In recent years, deep learning frameworks such as PyTorch, TensorFlow, Keras, Chainer, and others have been introduced and developed at a rapid pace. These frameworks provide neural network units, cost functions, and optimizers to assemble and train neural network models.
Using artificial neural networks is an important approach for drawing inferences and making predictions when analyzing large and complex data sets. TensorFlow and PyTorch are two popular machine learning frameworks supporting ANN models.
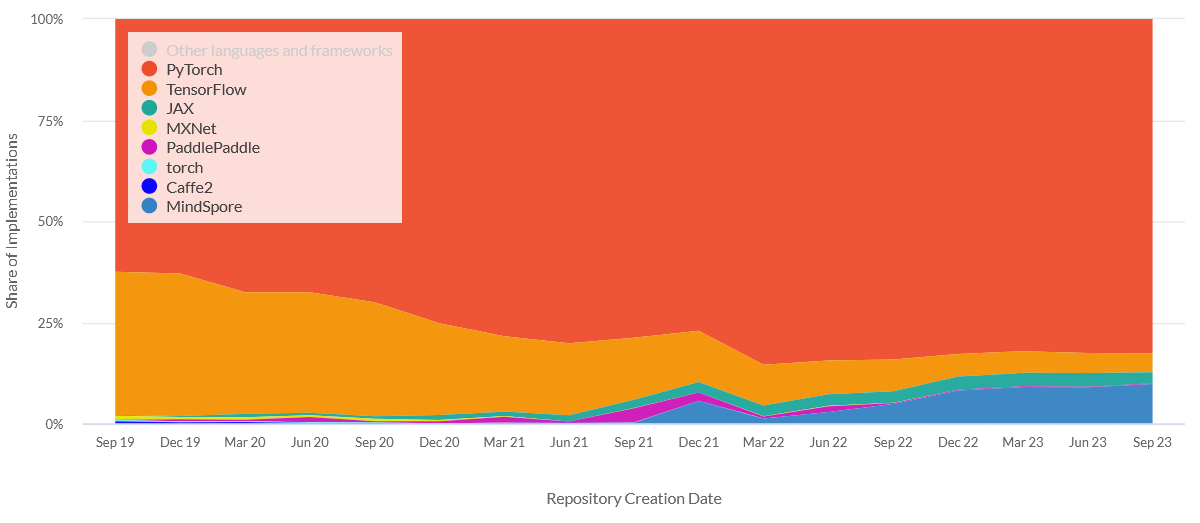
This article describes the effectiveness and differences between these two frameworks based on recent research to compare the training time, memory usage, and ease of use of the two frameworks. In particular, you will learn:
- Characteristics of PyTorch vs. TensorFlow
- Performance, Accuracy, Training, and Ease of Use
- Main Differences PyTorch vs. TensorFlow
Key Characteristics of TensorFlow and PyTorch
TL;DR
| Feature | PyTorch | TensorFlow |
|---|---|---|
| Ease of Use | More Pythonic syntax and easier to debug | A steeper learning curve requires more boilerplate code |
| Dynamic Computation Graph | Easier to modify the computation graph during runtime | A static computation graph requires recompilation for changes |
| GPU Support | Multi-GPU support is easier to set up and use | Multi-GPU support is more complex and requires more setup. There is a TF API |
| Community Support | Newer community compared to TensorFlow, growing very fast | Large and active community with extensive resources |
| Ecosystem | Has fewer libraries and tools compared to TensorFlow | Has an extensive library of pre-built models and tools |
| Debugging | Easier to debug due to Pythonic syntax and dynamic computation graph | Debugging can be more challenging due to the static computation graph |
| Research | Often used for research due to its flexibility and ease of use | Often used for production applications due to its speed and scalability |
| Math Library | PyTorch uses TorchScript for tensor manipulation and NumPy for numerical computations | TensorFlow uses its math library for both tensor manipulation and numerical computations |
| Keras Integration | PyTorch does not have a native Keras integration | TensorFlow has a native Keras integration, which simplifies model building and training |
TensorFlow Overview
TensorFlow is a very popular end-to-end open-source platform for machine learning. It was originally developed by researchers and engineers working on the Google Brain team before it was open-sourced.
The TensorFlow software library replaced Google’s DistBelief framework and runs on almost all available execution platforms (CPU, GPU, TPU, Mobile, etc.). The framework provides a math library that includes basic arithmetic operators and trigonometric functions.
TensorFlow is currently used by various international companies, such as Google, Uber, Microsoft, and a wide range of universities.
Keras is the high-level API of the TensorFlow platform. It provides an approachable, efficient interface for solving machine learning (ML) problems, with a focus on modern deep learning models. The TensorFlow Lite implementation is specially designed for edge-based machine learning. TF Lite is optimized to run various lightweight algorithms on various resource-constrained edge devices, such as smartphones, microcontrollers, and other chips.
TensorFlow Serving offers a high-performance and flexible system for deploying machine learning models in production settings. One of the easiest ways to get started with TensorFlow Serving is with Docker. For enterprise applications using TensorFlow, check out the computer vision platform Viso Suite, which automates the end-to-end infrastructure around serving a TensorFlow model at scale.

TensorFlow Advantages
- Support and library management. TensorFlow is backed by Google and has frequent releases with new features. It is popularly used in production environments.
- Open-sourced. TensorFlow is an open-source platform that is very popular and available to a broad range of users.
- Data visualization. TensorFlow provides a tool called TensorBoard to visualize data graphically. It also allows easy debugging of nodes, reduces the effort of looking at the whole code, and effectively resolves the neural network.
- Keras compatibility. TensorFlow is compatible with Keras, which allows its users to code some high-level functionality sections and provides system-specific functionality to TensorFlow (pipelining, estimators, etc.).
- Very scalable. TensorFlow’s characteristic of being deployed on every machine allows its users to develop any kind of system.
- Compatibility. TensorFlow is compatible with many languages, such as C++, JavaScript, Python, C#, Ruby, and Swift. This allows a user to work in an environment they are comfortable in.
- Architectural support. TensorFlow finds its use as a hardware acceleration library due to the parallelism of work models. It uses different distribution strategies in GPU and CPU systems. TensorFlow architecture also has its own TPU, which performs computations faster than a GPU or CPU. Therefore, models built using TPU can be easily deployed on the cloud at a cheaper rate and executed at a faster rate. However, TensorFlow’s architecture TPU only allows the execution of a model, not training it.
TensorFlow Disadvantages
- Benchmark tests. Computation speed is where TensorFlow lags when compared to its competitors. It has less usability in comparison to other frameworks.
- Dependency. Although TensorFlow reduces the length of code and makes it easier for a user to access it, it adds a level of complexity to its use. Every code needs to be executed using a platform for its support, which increases the dependency for the execution.
- Symbolic loops. TensorFlow lags in providing symbolic loops for indefinite sequences. It has its usage for definite sequences, which makes it a usable system. Hence, it is referred to as a low-level API.
- GPU Support. Originally, TensorFlow had only NVIDIA support for GPU and Python support for GPU programming, which is a drawback as there is a hike in other languages in deep learning.
TensorFlow Distribution Strategies is a TensorFlow API to distribute training across multiple GPUs, multiple machines, or TPUs. Using this API, you can distribute your existing models and training code with minimal code changes.
PyTorch Overview
PyTorch was first introduced in 2016. Before PyTorch, deep learning frameworks often focused on either speed or usability, but not both. PyTorch has become a popular tool in the deep learning research community by combining a focus on usability with careful performance considerations. It provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy, and is consistent with other popular scientific computing libraries while remaining efficient and supporting hardware accelerators such as GPUs.
The open-source deep learning framework is a Python library that performs immediate execution of dynamic tensor computations with automatic differentiation and GPU acceleration, and does so while maintaining performance comparable to the fastest current libraries for deep learning. Today, most of its core is written in C++, one of the primary reasons PyTorch can achieve much lower overhead compared to other frameworks. As of today, PyTorch appears to be best suited for drastically shortening the design, training, and testing cycle for new neural networks for specific purposes. Hence, it became very popular in the research communities.
PyTorch 2.0
PyTorch 2.0 marks a major advancement in the PyTorch framework, offering enhanced performance while maintaining backward compatibility and its Python-centric approach, which has been key to its widespread adoption in the AI/ML community.
For mobile deployment, PyTorch provides experimental end-to-end workflow support from Python to iOS and Android platforms, including API extensions for mobile ML integration and preprocessing tasks. PyTorch is suitable for natural language processing (NLP) tasks to power intelligent language applications using deep learning. Additionally, PyTorch offers native support for the ONNX (Open Neural Network Exchange) format, allowing for seamless model export and compatibility with ONNX-compatible platforms and tools.
Multiple popular deep learning software and research-oriented projects are built on top of PyTorch, including Tesla Autopilot or Uber’s Pyro.

PyTorch Advantages
- PyTorch is based on Python. PyTorch is Python-centric or “pythonic”, designed for deep integration in Python code instead of being an interface to a deep learning library written in some other language. Python is one of the most popular languages used by data scientists and is also one of the most popular languages used for building machine learning models and ML research.
- Easier to learn. Because its syntax is similar to conventional programming languages like Python, PyTorch is comparatively easier to learn than other deep learning frameworks.
- Debugging. PyTorch can be debugged using one of the many widely available Python debugging tools (for example, Python’s pdb and ipdb tools).
- Dynamic computational graphs. PyTorch supports dynamic computational graphs, which means the network behavior can be changed programmatically at runtime. This makes optimizing the model much easier and gives PyTorch a major advantage over other machine learning frameworks, which treat neural networks as static objects.
- Data parallelism. The data parallelism feature allows PyTorch to distribute computational work among multiple CPU or GPU cores. Although this parallelism can be done in other machine-learning tools, it’s much easier in PyTorch.
- Community. PyTorch has a very active community and forums (discuss.pytorch.org). Its documentation (pytorch.org) is very organized and helpful for beginners; it is kept up to date with the PyTorch releases and offers a set of tutorials. PyTorch is very simple to use, which also means that the learning curve for developers is relatively short.
- Distributed Training. PyTorch offers native support for asynchronous execution of collective operations and peer-to-peer communication, accessible from both Python and C++.
PyTorch Disadvantages
- Lacks model serving in production. While this will change in the future, other frameworks have been more widely used for real production work (even if PyTorch becomes increasingly popular in the research communities). Hence, the documentation and developer communities are smaller compared to other frameworks.
- Limited monitoring and visualization interfaces. While TensorFlow also comes with a highly capable visualization tool for building the model graph (TensorBoard), PyTorch doesn’t have anything like this yet. Hence, developers can use one of the many existing Python data visualization tools or connect externally to TensorBoard.
- Not as extensive as TensorFlow. PyTorch is not an end-to-end machine learning development tool; the development of actual applications requires conversion of the PyTorch code into another framework, such as Caffe2, to deploy applications to servers, workstations, and mobile devices.
Comparing PyTorch vs. TensorFlow
Performance
The following performance benchmark aims to show an overall comparison of the single-machine eager mode performance of PyTorch by comparing it to the popular graph-based deep learning Framework TensorFlow.
The table shows the training speed for the two models using 32-bit floats. Throughput is measured in images per second for the AlexNet, VGG-19, ResNet-50, and MobileNet models, in tokens per second for the GNMTv2 model, and samples per second for the NCF model. The benchmark shows that the performance of PyTorch is better compared to TensorFlow, which can be attributed to the fact that these tools offload most of the computation to the same version of the cuDNN and cuBLAS libraries.
Accuracy
The PyTorch vs Tensorflow Accuracy graphs (see below) show how similar the accuracies of the two frameworks are. For both models, the training accuracy constantly increases as the models start to memorize the information they are being trained on.
The validation accuracy indicates how well the model is learning through the training process. For both models, the validation accuracy of the models in both frameworks averaged about 78% after 20 epochs. Hence, both frameworks can implement the neural network accurately and are capable of producing the same results given the same model and data set to train on.
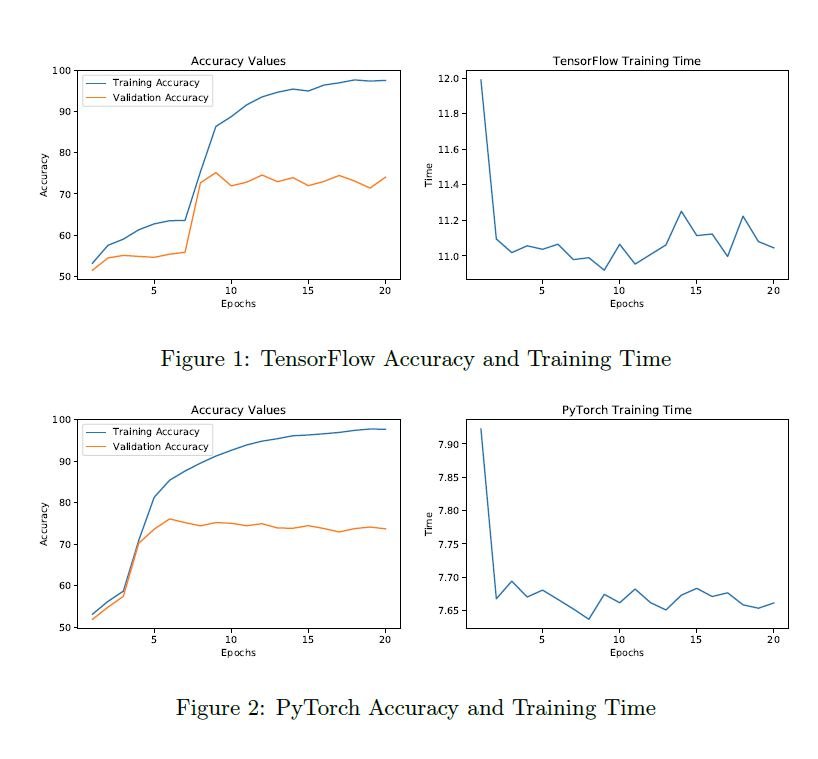
Training Time and Memory Usage
The above figure shows the training times of TensorFlow and PyTorch. It indicates a significantly higher training time for TensorFlow (an average of 11.19 seconds for TensorFlow vs. PyTorch with an average of 7.67 seconds).
While the duration of the model training times varies substantially from day to day on Google Colab, the relative durations between PyTorch vs TensorFlow remain consistent.
The memory usage during the training of TensorFlow (1.7 GB of RAM) was significantly lower than PyTorch’s memory usage (3.5 GB RAM). However, both models had a little variance in memory usage during training and higher memory usage during the initial loading of the data: 4.8 GB for TensorFlow vs. 5 GB for PyTorch.
Ease of Use
PyTorch’s more object-oriented style made implementing the model less time-consuming. Also, the specification of data handling was more straightforward for PyTorch compared to TensorFlow.
On the other hand, TensorFlow indicates a slightly steeper learning curve due to the low-level implementations of the neural network structure. Hence, its low-level approach allows for a more customized approach to forming the neural network, allowing for more specialized features.
Moreover, the very high-level Keras library runs on top of TensorFlow. So, as a teaching tool, the very high-level Keras library can be used to teach basic concepts. Then, TensorFlow can be used to further concept understanding by laying out more of the structure.
A Brief Recap
The answer to the question “What is better, PyTorch vs Tensorflow?” essentially depends on the use case and application.
In general, TensorFlow and PyTorch implementations show equal accuracy. However, the training time of TensorFlow is substantially higher, but the memory usage was lower.
PyTorch allows quicker prototyping than TensorFlow. However, TensorFlow may be a better option if custom features are needed in the neural network.
TensorFlow treats the neural network as a static object. So, if you want to change the behavior of your model, you have to start from scratch. With PyTorch, the neural network can be tweaked on the fly at run-time, making it easier to optimize the model.
Another major difference lies in how developers go about debugging. Effective debugging with TensorFlow requires a special debugger tool to examine how the network nodes do calculations at each step. PyTorch can be debugged using one of the many widely available Python debugging tools.
Both PyTorch and TensorFlow provide ways to speed up model development and reduce the amount of boilerplate code. However, the core difference between PyTorch and TensorFlow is that PyTorch is more “Pythonic” and based on an object-oriented approach. At the same time, TensorFlow provides more options to choose from, resulting in generally higher flexibility. For many developers familiar with Python, this is an important reason why PyTorch is better than TensorFlow.
What’s Next?
If you enjoyed reading this article and want to learn more about AI, ML, and DL, we recommend reading:
- The Most Popular Deep Learning Software
- Introduction to Image Recognition
- Object Detection algorithms
- OpenCV – the famous computer vision library
- Most Popular Deep Learning Frameworks
- Face Recognition Technologies
- Active Learning in Computer Vision