
Vision Language Models (VLMs) bridge the gap between visual and linguistic understanding of AI. They consist of a multimodal architecture that learns to associate information from image and text modalities.
In simple terms, a VLM can understand images and text jointly and relate them. By using advances in Transformers and pretraining strategies, VLMs unlock the potential of vision language applications ranging from image search to image captioning, generative tasks, and more!
How Do Vision Language Models Work?
Humans can effortlessly process information from multiple sources simultaneously; for instance, we rely on interpreting words, body language, facial expressions, and tone during a conversation.
Similarly, vision language models (VLMs) can process such multimodal signals effectively and efficiently, enabling machine vision. Thus, understanding and generating image information involves blending visual and textual elements.
Modern VLM architectures rely mostly on transformer-based AI models for image and text processing because they efficiently capture long-range dependencies.
At the core of Transformers lies the multi-head attention mechanism introduced by Google’s “Attention Is All You Need” paper, which will come in handy soon.
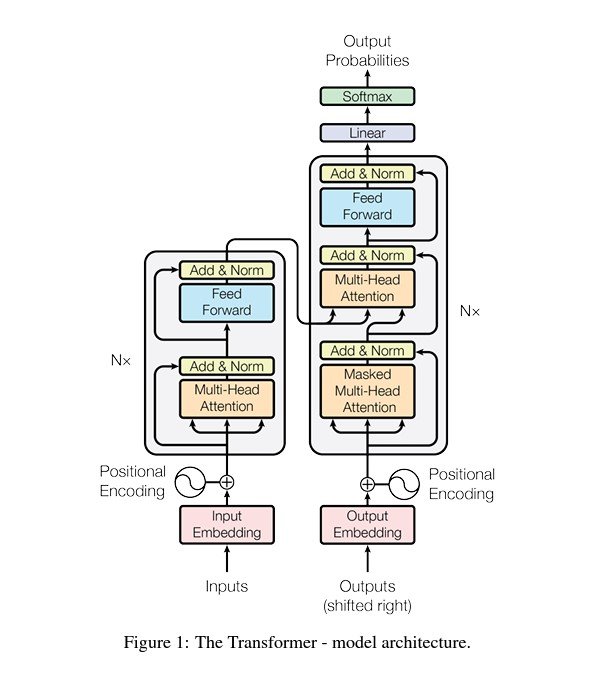
Components of Vision Language Models
To achieve this multimodal understanding, VLMs typically consist of 3 main elements:
- An Image Model: Responsible for extracting meaningful visual information such as features and representations from visual data, i.e., Image encoder.
- A Text Model: Designed to process and understand natural language processing (NLP), i.e., text encoder.
- A Fusion Mechanism: A strategy to combine the representations learned by the image and text models, allowing for cross-modal interactions.
Based on this paper, we can group encoders depending on the fusion mechanism to combine representations into three categories: Fusion encoders (which directly combine image and text embeddings), dual encoders (which process them separately before interaction), and hybrid methods that leverage both strengths.
Also, based on the same paper, two main types of fusion schemes for cross-modal interaction exist: single-stream and dual-stream.
Before digging deeper into specific architectures and pretraining methods, we must consider that the surge of multimodal development over the recent years, powered by advances in vision-language pretraining (VLP) methods, has given rise to various vision-language applications.
They broadly fall into three categories:
- Image-text tasks: image captioning, retrieval, and visual question answering.
- Core computer vision tasks: (open-set) image classification, object detection, and image segmentation
- Video-text tasks: video captioning, video-text retrieval, and video question-answering
However, this article will only review a few vision language models, focusing on image-text and core computer vision tasks.
Open-Source Vision Language Model Architectures
VLMs typically extract text features (e.g., word embeddings) and visual features (e.g., image regions or patches) using a text encoder and visual encoder. A multimodal fusion module then combines these independent streams, producing cross-modal representations.
A decoder translates these representations into text or other outputs for generation-type tasks.
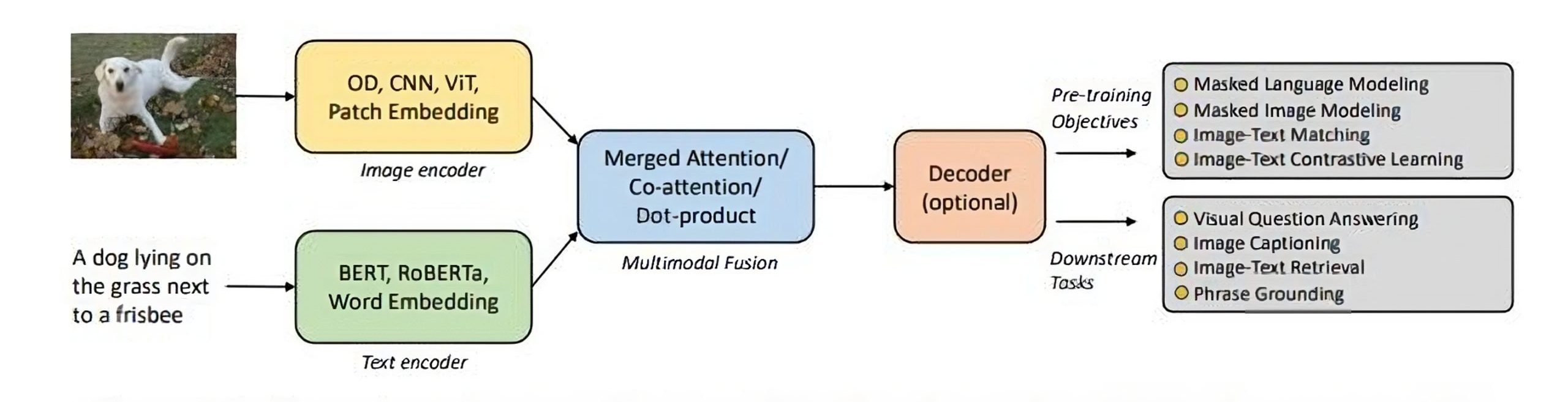
Now, let’s get into several specific architectures for transformer-based VLMs.
CLIP (Contrastive Language–Image Pretraining)
CLIP is an open-source AI model found by OpenAI that relies on the transformer’s attention mechanisms.
The CLIP model features a dual encoder architecture. Fusion of the multimodal representations is achieved by calculating the dot product between global image and text feature vectors.
CLIP leverages a modified ResNet-50 for efficient image feature extraction. Notably, replacing global average pooling with a transformer-style attention pooling mechanism enhances its ability to focus on relevant image regions.
It also employs a 12-layer, 8-attention heads Transformer with masked self-attention for text encoding, allowing potential integration with pre-trained language models.
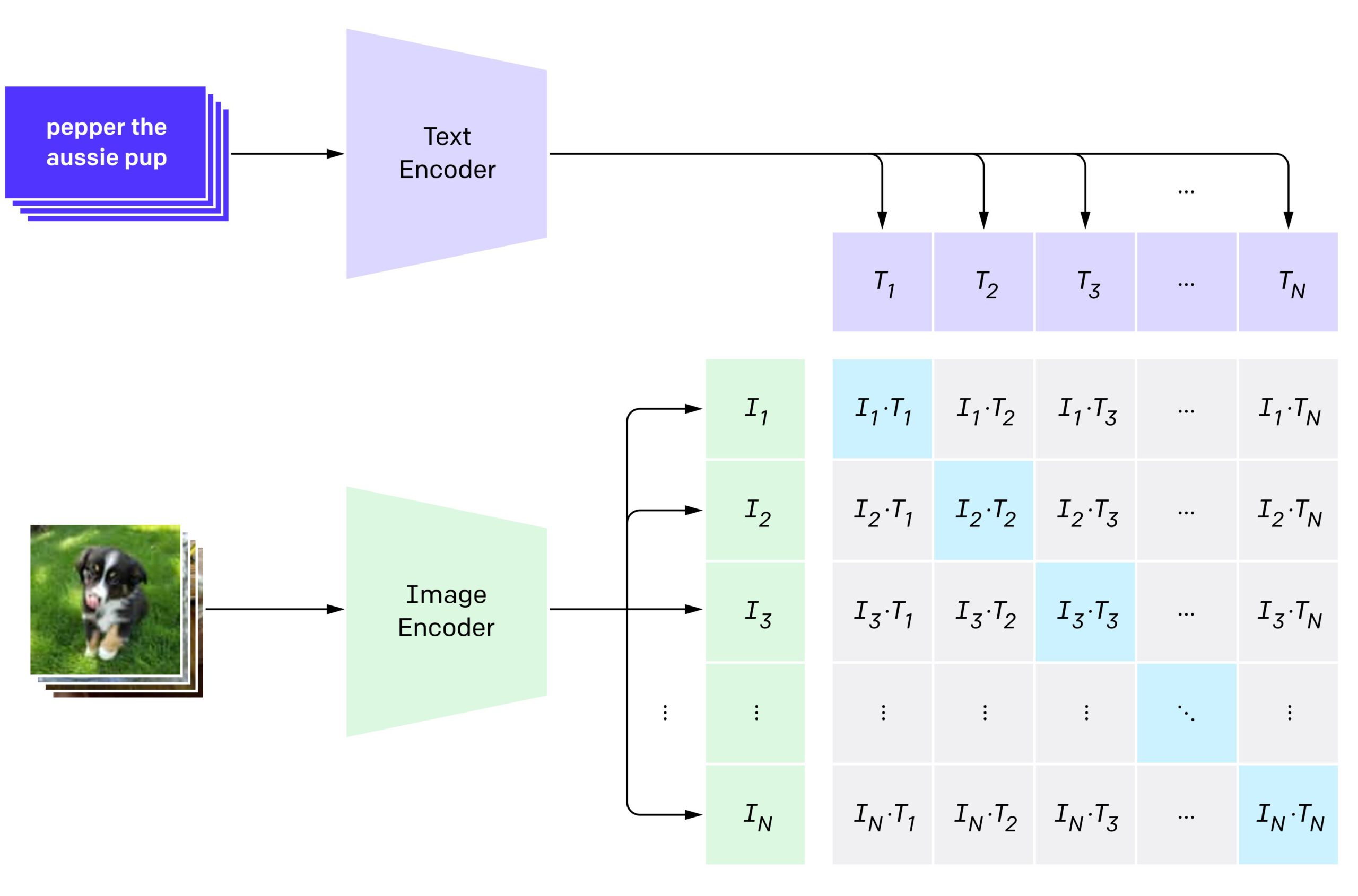
CLIP is pre-trained on a diverse dataset of image-text pairs. This pretraining empowers CLIP with zero-shot learning capabilities, enabling it to perform tasks without explicit training on new class labels. Here are a few examples:
- Novel Image Classification
- Image-Text Retrieval
- Visual Question Answering
ViLBERT (Vision-and-Language BERT)
ViLBERT is another example of a vision language model that depends on the attention mechanism. It extends the famous BERT architecture to consist of two parallel BERT-style models operating over image regions and text segments that interact through co-attentional transformer layers.
For multimodal fusion, this model employs a co-attention Transformer architecture. This architecture dedicates separate Transformers to process image region and text features, with an additional Transformer fusing these representations.

ViLBERT’s joint modeling approach makes it well-suited for tasks requiring tight alignment between image regions and text segments, such as visual question answering (VQA) and referring expression comprehension.
The main difference between the two above models is the fusion mechanism. CLIP’s dual-encoder architecture uses dot-product for multimodal fusion, while ViLBERT uses the co-attention module.
These are prime examples of the best open-source vision language models, showcasing the power of different architectures and pretraining strategies for multimodal understanding.
Having discussed the architectures, let’s explore a few pre-training strategies widely used in the development of VLMs.
Pretraining Strategies for Vision Language Models
Besides the architectural choices we discussed earlier, vision-language pretraining (VLP) plays a vital role in VLM performance.
These techniques, often adapted from text-based pretraining, empower visual language models to achieve impressive multimodal understanding and unlock the potential for a wide range of tasks such as image-text alignment, zero-shot classification, and visual question answering.
Now, let’s list a few essential techniques widely used for VLMs.
Contrastive Learning
Contrastive learning is an unsupervised deep learning technique. The goal is to learn representations by maximizing the similarity between aligned image-text pairs while minimizing the similarity between mismatched ones.
Contrastive learning often serves as a beneficial pretraining goal for vision models, showcasing its versatility in enhancing performance across various computer vision and natural language processing tasks.
The dataset for this type of pretraining objective would have image-text pairs; some pairs would be genuine matches, while others would be mismatched.
In the context of vision language pretraining, contrastive learning, known as image-text contrastive learning (ITC), was popularized mainly by CLIP and ALIGN to pre-train dual encoders. Dual encoders are used to compute image-to-text and text-to-image similarities through a mathematical operation.
Masked-Image Modeling (MIM) / Masked Language Modeling (MLM)
Masked image modeling (MIM) is similar to Masked Language Modeling (MLM) and has proven helpful in vision-language architecture.
In MIM, 15% of words in an image-text pair get masked, and the goal is to predict them based on the context and the image.
Researchers have explored various masked image modeling (MIM) tasks for pretraining, which share similarities with the MLM objective.
In these tasks, researchers train the model to reconstruct the masked patches or regions given the remaining visible patches or regions and all the words.
Recent state-of-the-art text-image models do not use MIM during pretraining but employ masked vision-language modeling instead. Models like BEiT, iBOT, and others have demonstrated the power of this approach.
| VL-PTM | Text Encoder | Vision Encoder | Fusion Scheme | Pre-Training Task |
|---|---|---|---|---|
| Fusion Encoder | ||||
| VisualBERT [2019]
Uniter [2020] OSCAR [2020c] InterBert [2020] ViLBERT [2019] LXMERT [2019] VL-BERT [2019] Pixel-BERT [2020] Unified VLT [2020] UNIMO [2020b] SOHO [2021] VL-T5 [2021] XGPT [2021] Visual Parsing [2021] ALBEF [2021a] SimVLM [2021b] WenLan [2021] ViLT [2021] |
BERT
BERT BERT BERT BERT BERT BERT BERT UniLM BERT, RoBERTa BERT T5, BART transformer BERT BERT ViT RoBERTa ViT |
Faster R-CNN
Faster R-CNN Faster R-CNN Faster R-CNN Faster R-CNN Faster R-CNN Faster R-CNN + ResNet ResNet Faster R-CNN Faster R-CNN ResNet + Visual Dictionary Faster R-CNN Faster R-CNN Faster R-CNN + Swin Transformer ViT ViT Faster R-CNN + EfficientNet Linear Projection |
Single Stream
Single Stream Single Stream Single Stream Dual Stream Dual Stream Single Stream Single Stream Single Stream Single Stream Single Stream Single Stream Single Stream Dual Stream Dual Stream Single Stream Dual Stream Single Stream |
MLM+ITM
MLM+ITM+WRA+MRFR+MRC MLM+ITM MLM+MRC+ITM MLM+MRC+ITM MLM+ITM+MRC+MRFR+VQA MLM+MRC MLM+ITM MLM+seq2seq LM MLM+seq2seq LM+MRC+MRFR+CMCL MLM+MVM+ITM MLM+VQA+ITM+VG+GC IC+MLM+DAE+MRFR MLM+ITM+MRF MLM+ITM+CMCL PrefixLM CMCL MLM+ITM |
| Dual Encoder | ||||
| CLIP [2021]
ALIGN [2021] DeCLIP [2021b] |
GPT2
BERT GPT2, BERT |
ViT, ResNet
EfficientNet ViT, ResNet, RegNet Y-64GF |
CMCL
CMCL CMCL+MLM+CL |
|
| Fusion Encoder + Dual Encoder | ||||
| VLMo [2021a]
FLAVA [2021] |
BERT
ViT |
ViT
ViT |
Single Stream
Single Stream |
MLM+ITM+CMCL
MMM+ITM+CMCL |
This table part shows vision language models with the pretraining task and fusion scheme used. Notably, most models’ pretraining tasks involve MLM.
Image-Text Matching (ITM)
In Image-Text Matching (ITM), the model receives a batch containing both correctly matched and mismatched image-caption pairs. Its task is to distinguish between genuine and misaligned pairings.
ITM is similar to the Next Sentence Prediction (NSP) task in natural language processing, which requires the model to determine whether an image and a text match.
We then feed the model with an equal probability of a matched or mismatched image-caption pair. A classifier is added to determine if a given image-caption pair is matched, which predicts a binary label (matched/mismatched).
The key to this task is representing an image-text pair in a single vector so that the score function can output a probability.
ITM usually works best alongside Masked-Language Modeling (MLM). Models like ViLBERT and UNITER often incorporate ITM as an auxiliary pre-training task.
Those are just a few foundational examples of VLP; for a more comprehensive study of methods, read here.
That said, refining existing techniques and developing novel pretraining methods can further enhance the capabilities of vision language models.
The choice of datasets and benchmarks used during pre-training directly influences model performance. Let’s explore the key datasets and evaluation metrics used in the VLM domain.
Datasets and Benchmarks in Vision Language Models
Datasets are the foundation for model development throughout a vision language model lifecycle, from the initial pretraining to the crucial phases of finetuning and evaluation.
Evaluation and benchmarking are just as essential for tracking progress in VLM development. They reveal how effectively different models leverage the strengths and weaknesses of various datasets.
Pretraining datasets are usually large-scale datasets consisting of image-text pairs. During training, each text is tokenized as a sequence of tokens, and each image is transformed into a sequence of features.
Some popular datasets are:
- COCO (328,124 image-text pairs)
- LAION (400M)
- Conceptual Caption (3.1M)
Those datasets are inherently noisy. Thus, VLMs take pre-processing steps to denoise them; ALIGN notably uses its own high-quality dataset.

However, this section will focus on task-specific datasets and benchmarks. The type of tasks we will briefly explore include:
- Image-text Retrieval
- Visual Question Answering and Visual Reasoning
- Image Captioning
- Zero-Shot Classification
Datasets and benchmarks for Image-Text Retrieval
Image-text retrieval has two sub-tasks: image-to-text retrieval, which retrieves a textual description that can be grounded in the image query, and text-to-image retrieval, which retrieves a textual description that can be grounded in the image query.
Popular datasets include COCO and Flickr30K due to their large size, diverse image content, and the inclusion of multiple descriptive captions per image.
For evaluation, Recall@K (K=1, 5,10) is used., Recall@K measures the percentage of cases where the correct image (or text) appears within the top K retrieved results.
Let’s look at the benchmarks of vision language models on the COCO and Flickr30K for Image-to-Text Retrieval using the Recall@1 evaluation metric, as it shows the difference in accuracy the most:
| MS COCO | Flickr30K | ||
|---|---|---|---|
| Model | Recall@1 Score | Model | Recall@1 Score |
| BLIP-2 ViT-G (fine-tuned) |
85.4 | InternVL-G-FT (finetuned, w/o ranking) |
97.9 |
| ONE-PEACE (w/o ranking) |
84.1 | BLIP-2 ViT-G (zero-shot, 1K test set) |
97.6 |
| BLIP-2 ViT-L (fine-tuned) |
83.5 | ONE-PEACE (finetuned, w/o ranking) |
97.6 |
| IAIS | 67.78 | InternVL-C-FT (finetuned, w/o ranking) |
97.2 |
| FLAVA (zero-shot) |
42.74 | BLIP-2 ViT-L (zero-shot, 1K test set) |
96.9 |
Table: Benchmarks of vision language models on the COCO and Flickr30K – Source1. Source2.
Datasets and benchmarks for Visual Question Answering and Visual Reasoning
Visual Question Answering (VQA) requires the model to answer a question correctly based on a given question-image pair.
The question can be either open-ended, with a free-form answer, or multiple-choice, with a set of answer choices provided. However, for simplification purposes, most studies treat both types of questions in VQA as a classification problem.
Similarly, visual reasoning aims to evaluate the specific reasoning capabilities of a vision language model. In most studies, researchers formulate visual reasoning tasks as VQA.
The original VQA dataset is the most used, and its variations are designed as different diagnostic datasets to perform a stress test for VQA models. For example, VQAv2, the second version of the VQA dataset, is the current benchmark for VQA tasks.
Models using datasets derived from the VQA dataset are evaluated using the VQA score. Accuracy is the standard evaluation metric for other VLM benchmarks.
Let’s take a look at the top 5 benchmarks for vision-language models on the visual question-answering task using the VQAv2 dataset:
Note: Those benchmarks are test-std scores, which accurately measure model performance.
| Model | Overall Score |
|---|---|
| BEiT-3 | 84.03 |
| mPLUG-Huge | 83.62 |
| ONE-PEACE | 82.52 |
| X2-VLM (large) |
81.8 |
| VLMo | 81.30 |
Table: Top 5 benchmarks for VLMs on VQA task – Source.
Datasets and benchmarks for Image Captioning
Image captioning is the intersection between computer vision and natural language processing. It is the task of describing a visual image in a free-form textual caption.
Two proposed captions for image captioning are single-sentence and multi-sentence descriptive paragraph captions.
Popular datasets, including COCO, TextCaps, and VizWiz-Captions, are usually designed for single-sentence captions.
There have been fewer efforts in building datasets with more descriptive, multi-sentence captions.
Captioning performance is usually evaluated using standard text generation metrics based on n-gram overlap or semantic content matching metrics. The most used evaluation metrics include BLEU-4, CIDER, METEOR, and SPICE.
Here is a look at the benchmarks of the top 5 models on the COCO Captions dataset using the BLEU-4 evaluation metric:
| Model | Overall Score |
|---|---|
| mPLUG | 46.5 |
| OFA | 44.9 |
| GIT | 44.1 |
| BLIP-2 ViT-G OPT 2.7B (zero-shot) |
43.7 |
| LEMON | 42.6 |
Datasets and benchmarks for Zero-Shot Recognition
The tasks we have mentioned so far are considered image-text tasks that need an image-text pair, as shown in the figure below:
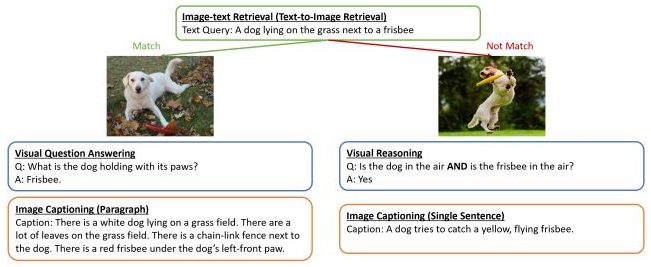
Zero-shot recognition is slightly different than Image-Text tasks; CLIP-like vision-language foundation models have enabled open vocabulary visual recognition by mapping images with their corresponding language descriptions.
Early methods demonstrate their effectiveness on image classification tasks. For example, CLIP can achieve zero-shot accuracy on 27 image classification datasets. Given its potential, language-driven visual recognition tasks extend to object detection and semantic segmentation functions.
Multiple evaluation metrics exist based on the granularity consistency, although in this article, we will look at this paper and see their evaluation for contrastive learning models on ImageNet:
| Model | Leaves | Ancestorraw | Ancestorchild (Δ) | Ancestorleaf (Δ) |
|---|---|---|---|---|
| CLIP-B
CLIP-L |
50.10
65.06 |
24.91
33.64 |
45.35 (+20.44)
57.72 (+24.08) |
58.73 (+33.83)
72.25 (+38.61) |
| OpenCLIPB-400M
OpenCLIPB-2B OpenCLIPL-2B OpenCLIPH-2B |
47.10
54.97 65.79 68.28 |
20.12
24.95 31.59 32.70 |
40.66 (+20.54)
47.64 (+22.69) 56.65 (+25.07) 58.70 (+26.00) |
54.50 (+34.38)
62.66 (+37.70) 72.53 (+40.94) 74.93 (+42.23) |
| UniCLYFCC
UniCLIN21K UniCLYFCC+IN21K UniCLAll |
35.75
26.28 37.84 54.49 |
20.13
38.15 35.18 37.54 |
35.90 (+15.77)
39.30 (+1.15) 44.48 (+9.65) 54.58 (+17.04) |
47.55 (+27.42)
41.23 (+3.08) 51.55 (+16.37) 65.85 (+28.32) |
| K-LITE | 48.40 | 31.50 | 49.63 (+18.14) | 61.58 (+30.08) |
| BLIP
BLIPft-coco |
41.87
42.83 |
20.31
22.07 |
39.44 (+19.13)
41.45 (+19.38) |
52.08 (+31.77)
54.00 (+31.93) |
| FLAVA | 40.91 | 21.36 | 39.32 (+17.96) | 51.89 (+30.53) |
Visual Language models benchmark table for zero-shot tasks.
Use Cases and Implementations of Vision Language Models
We’ve explored the diverse tasks VLMs enable and their unique architectural strengths. Let’s now delve into real-world applications of these powerful models:
- Image Search and Retrieval: VLMs power fine-grained image searches using natural language queries, changing how we find relevant imagery online and even in non-relational database retrieval.
- Visual Assistance for the Impaired: Models can generate detailed image descriptions or answer questions about visual content, aiding visually impaired individuals.
- Enhanced Product Discovery: VLMs enable users to search for products using images or detailed descriptions, streamlining the shopping experience and boosting e-commerce websites.
- Automatic Content Moderation: Detecting inappropriate or harmful content within images and videos often leverages VLM capabilities.
- Robotics: Integrating VLMs can allow robots to understand visual instructions or describe their surroundings, enabling more complex object interactions and collaboration.
Let’s move from theory to practice and explore how code brings these applications to life. We’ll start with an example demonstrating Image captioning using BLIP:
BLIP Image-Captioning Base Implementation
BLIP is available with the Transformers library and can run on CPU or GPU. Let’s take a look at the code and an inference example:
For the Imports, we are going to need the following:
from PIL import Image from transformers import BlipProcessor, BlipForConditionalGeneration
Then, we should load the models and prepare the images as follows:
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base").to("cuda")
img_url = 'Path/to/your/Image'
raw_image = Image.open(img_url).convert('RGB')
Lastly, we can generate a caption for our input image:
inputs = processor(raw_image, return_tensors="pt").to("cuda")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
Here is what the results would look like:
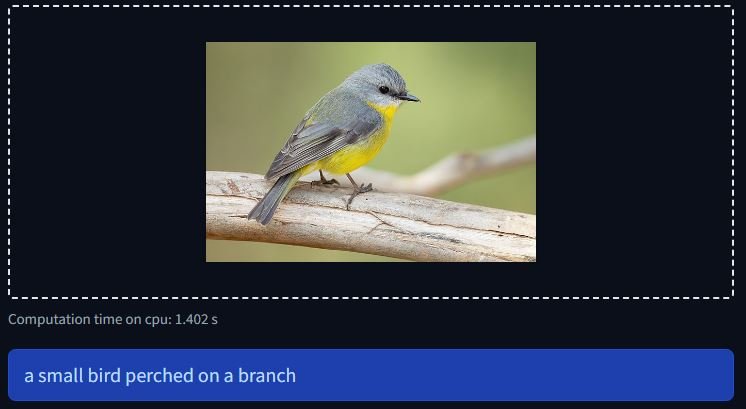
ViLT VQA Base Implementation
Vision-and-Language Transformer (ViLT) model fine-tuned on VQAv2 based on ViT. Available with the Transformers library with Pytorch, here is an example code and inference:
Importing the needed libraries:
from transformers import ViltProcessor, ViltForQuestionAnswering from PIL import Image
Loading models, preparing input image, and a question:
url = "/path/to/your/image"
image = Image.open(url)
text = "How many cats are there?"
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
model = ViltForQuestionAnswering.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
Encoding and inference:
encoding = processor(image, text, return_tensors="pt")
# forward pass
outputs = model(**encoding)
logits = outputs.logits
idx = logits.argmax(-1).item()
print("Predicted answer:", model.config.id2label[idx])
Here is an example inference:
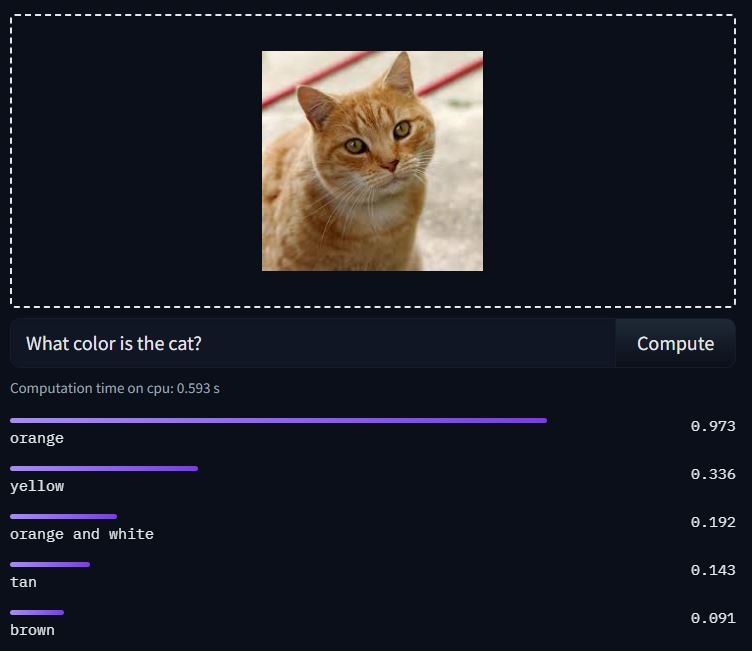
Note: To use any model from the Transformers library, make sure to install it with (pip)
Conclusion and Future of Vision Language Models
The intersection of visual input and language understanding is a fertile ground for innovation.
As training data expands and models evolve, we can anticipate the improvement of vision-language tasks from image-based search to assistive technologies, shaping the future of how we interact with the world.
They have the potential to transform industries, empower individuals, and unlock new ways of interacting with the world around us; multimodal AI is also the way to make general-purpose robots!