The ability to make computers see with AI technology enables a multitude of highly disruptive use cases. However, adopting computer vision applications is hard. The high technical complexity and slow, interdisciplinary development cause many projects to fail.
As a result, many AI vision systems struggle when moving from prototype to production, mainly because of budget overruns, limited agility, and scalability issues.
Enterprise AI vision technology
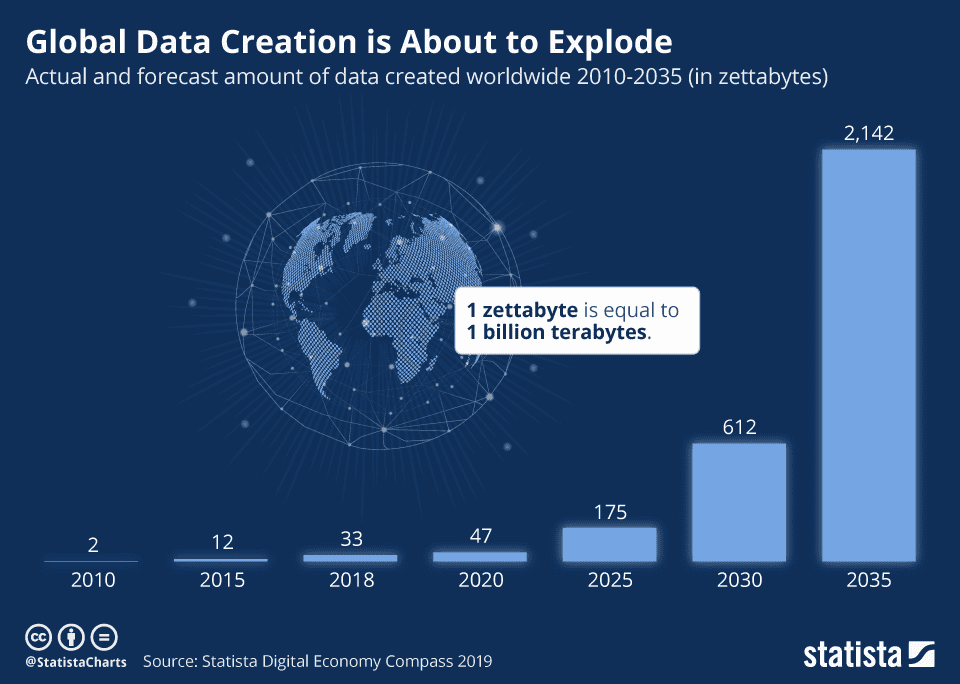
Global data is about to explode, not because of human-generated data, but because IoT and sensors generate an enormous amount of unstructured data. According to Cisco, by 2022, 80% of all global data will be video data. The immense amount of data generated through IoT is so enormous that it requires machine learning to process it. The combination of Artificial Intelligence and the Internet of Things is also called AIoT.
In image recognition, machine learning methods, especially deep learning, achieved great success. Traditionally, the only place to find enough computational power for AI tasks was in the Cloud, leveraging GPUs in datacenters. Because of the huge amount of data, it’s highly inefficient to route the traffic to the Cloud to process it there. For applications, the required data offloading comes with many limitations, such as latency, connectivity, bottlenecks, cost spikes, load-balancing, privacy, and more.
Technological advances make it possible to build much more efficient, distributed systems. Instead of sending all data to the Cloud, the concept of Edge Computing makes it possible to process data in close proximity to the data source (camera) and send only processed insights to the Cloud. The combination of edge computing with machine learning on-device is called Edge AI. The ability to process visual data on-device, using Edge devices such as embedded computers or servers connected to the internet, makes it possible to deploy computer vision broadly and at scale.
By running machine learning at the Edge, it becomes possible to build scalable, robust, offline-resistant, secure, cost-efficient, and real-time computer vision solutions. Enterprise AI vision applications which require high availability, are mission-critical, or require private processing – which is most – run better and more efficiently on the Edge.
The 3 key challenges in computer vision
Applying computer vision requires deploying machine learning algorithms as part of an application. The application manages video data input, applies deep learning models with a processing pipeline, and generates output to automate specific business tasks. For example, an object detection model is used as part of an application for helmet detection in industrial manufacturing.
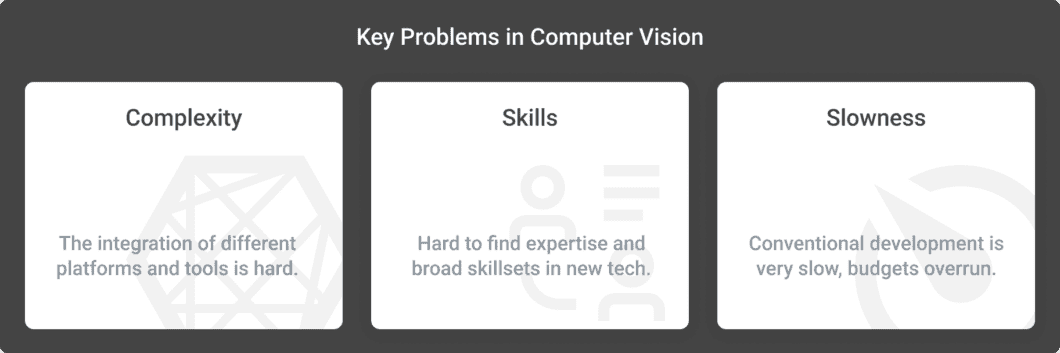
In the past years, image annotation and AI model training became broadly accessible and affordable. Accordingly, the problem shifts from training to deploying and operating deep learning. While model training and prototyping are fairly achievable, moving from prototyping to operationalization is a massive challenge. This is where most of the projects fail due to the following reasons:
- Complexity: Computer vision applications require the integration of numerous AI platforms, cross-architecture tools and frameworks, different data models, and hardware management. The combination of multiple hardware, software, and AI platforms needs coding for stitching together the different tools. This often goes well in the beginning, but it often results in brittle, hard-to-maintain spaghetti code with multiple, overlapping services. Teams will inevitably hit a wall in terms of extensibility and scalability.
- Skills: Robust AI vision systems require the skills of different engineers, including ML, Cloud, Edge AI, IoT, Web, DevOps, MLOps developers that are hard to find. Because of interdependencies, every team member needs to understand the full and continuously increasing complexity of the systems.
- Slow development: With conventional methods, computer vision development is very slow, and since it requires multiple iterations, budget overruns quickly. Moving from a prototype to a scalable, enterprise-grade solution involves tedious integration work. Changing business requirements or regulations further increase pressure on the development. Meanwhile, technology advances rapidly, and some applications are already outdated on release.