The foundation of computer vision research is deep features, which capture visual semantics. They allow engineers to perform downstream tasks even in the few-shot or zero-shot regime.
Consider taking a quick look at a crowded street and then attempting to recall the situation by drawing it. Nearly no one can draw every detail with pixel-perfect accuracy. However, most individuals can sketch the general locations of the main things, such as automobiles, people, and crosswalks.
The majority of contemporary computer vision algorithms are also excellent at capturing high-level aspects of a picture, but as they process data, they lose fine-grained details.
Get a Demo
Discover why enterprises choose Viso Suite for scalable, secure, and adaptable AI vision infrastructure.
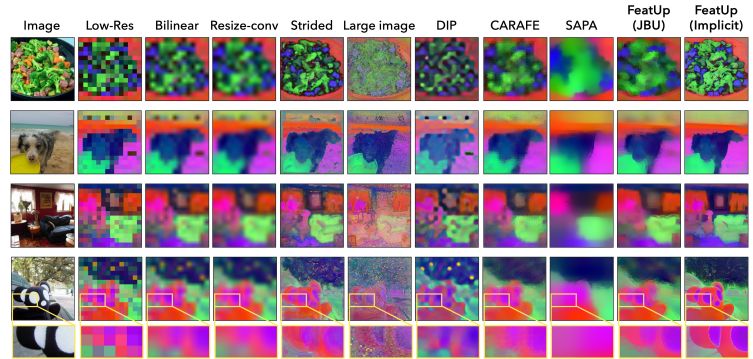
In March 2024, MIT researchers M. Hamilton, S. Fu et al. introduced FeatUp, a task- and model-agnostic framework to restore lost spatial information in deep features. They presented two FeatUp variations: one that fits an implicit model to a single image to reconstruct features at any resolution. The other – uncovers features with high-resolution signal in a single forward pass. They applied NeRF multi-view consistency loss deep analogies in both methods.
Through a process known as “features,” computers that are trained to “see” by observing pictures and videos develop “ideas” about what is present in a scene. Deep networks and visual foundation models generate these features by dividing images into a grid of small squares. Then they process the squares collectively to identify the meaning of a picture.
These algorithms’ resolution is far lower than that of the images they operate on because each tiny square typically consists of 16-32 pixels. Algorithms lose much pixel detail when attempting to summarize and comprehend images.
FeatUp upsamples the features of any backbone, even convnets with aggressive nonlinear pooling – Source
Without sacrificing speed or quality, the FeatUp algorithm may prevent this information loss and increase the resolution of any deep network. This makes it possible for researchers to swiftly increase the resolution of any method, whether it is new or old.
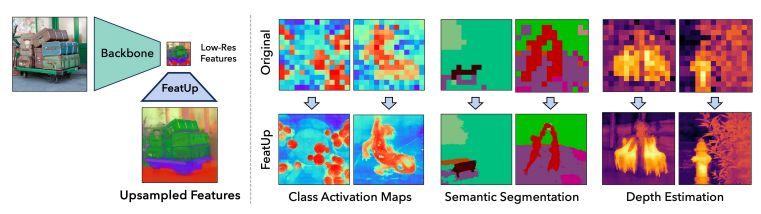
Consider attempting to locate the tumor by analyzing the predictions of a lung cancer detection algorithm. Using FeatUp with techniques such as class activation maps (CAM) can produce a significantly more detailed (16-32x) image of the tumor’s potential location.
How Does FeatUp Work?
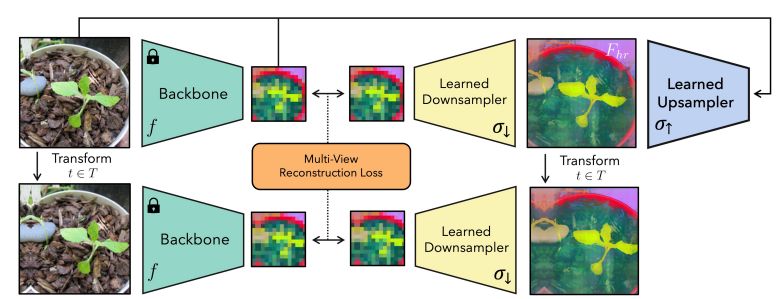
FeatUp is a unique framework that MIT researchers presented to increase the resolution of any vision model’s features without altering their initial “meaning” or orientation. Their main discovery was motivated by 3D reconstruction frameworks such as NeRF. They proved that high-resolution signals can be supervised by the multiview consistency of low-resolution signals.
The FeatUp training architecture. FeatUp learns to upsample features through a consistency loss on low-resolution “views” of a model’s features – Source
More precisely, by combining low-resolution views from a model’s outputs over several “jittered” (such as flipped, padded, or cropped) images, scientists were able to learn high-resolution information. They learned an upsampling network with a multiview consistency loss to aggregate this data.
Their workflow starts by creating low-resolution feature views, which are then refined into a single high-resolution output. To achieve this, researchers apply the model to each altered image to extract a set of low-resolution feature maps. They did this by perturbing the input image with minor pads, scales, and horizontal flips.
These views were then used by researchers to create a consistent high-resolution feature map. According to their hypothesis, they might learn a latent high-resolution feature map that would replicate their low-resolution jittered features when downsampled (see image above).
FeatUp’s downsampler converts high-resolution features into low-resolution features, which is a direct analog of ray-marching, which renders 3D data into 2D in this NeRF stage. They did not have to estimate the parameters that produced each view, unlike NeRF.
Rather, before downsampling, researchers performed the same transformation to their learned high-resolution features while monitoring the settings used to “jitter” each image. Reconstructing the observed features across all viewpoints is a must for a high-resolution feature map.
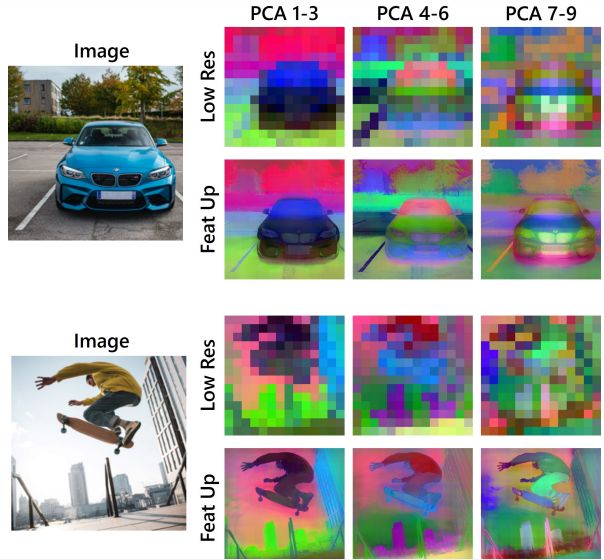
Visualizing higher PCA components with FeatUp – Source
Choosing Upsampler
The team investigated two upsampling architectures:
An implicit representation overfits to a single image
A single guided upsampling feedforward network that generalizes across images.
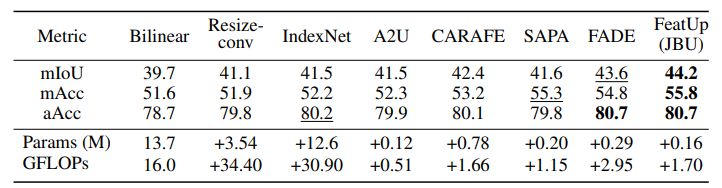
The feedforward upsampler is a parameterized generalization of a Joint Bilateral Upsampling (JBU) filter. It was faster and uses less memory than previous versions. CUDA kernel empowers this implementation. For about the same computational cost as a few convolutions, this upsampler can generate high-quality features that are aligned to object edges.
In a clear analogy to NeRF, their implicit upsampler overfits a deep implicit network to a signal. Moreover, it enables low storage costs and flexible resolution characteristics. Neither architecture’s approaches alter the meaning of the features. Thus, upsampled features can be used as drop-in replacements in downstream applications.
FeatUp upsamples image features from any model backbone, adding spatial resolution to existing semantics – Source
Researchers demonstrated how these upsampled features can greatly enhance a range of downstream tasks, such as depth prediction and semantic segmentation. They also demonstrated how upsampled features may be used to make model explanation techniques like CAM higher resolution.
Experiments and Performance
They first reduced the spatially varying features to their top k=128 main components. They aimed to lower the memory footprint and expedite the training of FeatUp’s implicit network. Since the top 128 components account for roughly 96% of the variance in a single image’s characteristics, this procedure is essentially lossless.
This allows for larger batches, lowers the memory footprint, increases training time by a factor of 60× for ResNet-50, and has no discernible impact on the quality of learned features. They showed how FeatUp is useful in downstream applications as a drop-in substitute for pre-existing features.
Semantic segmentation results with the Segformer, Xie et al. (2021) architecture trained on the ADE20k train set and evaluated on the value set – Source
To illustrate this, researchers used the popular experimental method of assessing representation quality through linear probe transfer learning. Additionally, they used low-resolution characteristics to train linear probes for segmentation and depth prediction.
FeatUp applications in Computer Vision
FeatUp can enhance a variety of prediction tasks like segmentation (assigning labels to pixels in an image with object labels) and depth estimation, in addition to assisting practitioners in understanding their models.
It accomplishes this by offering higher-resolution, more accurate characteristics, which are essential for developing vision applications ranging from medical imaging to driverless cars.
Object Detection
The main problem with contemporary algorithms is that they condense vast images into tiny grids of “smart” features, which results in the loss of finer details but also clever insights. FeatUp’s perceptive characteristics that surface from the depths of deep learning architectures can largely assist in object detection tasks.
According to Mark Hamilton, a co-lead author on a paper describing the project and an affiliate of the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL), FeatUp enables the best of both worlds: extremely intelligent representations with the resolution of the original image.
Low-resolution ViT features (14 × 14) from the COCO-Stuff validation set are upsampled by 16× – Source
From increasing object detection and depth prediction to high-resolution analysis, these high-resolution features dramatically improve performance across a variety of computer vision applications.
Discovering Fine-grained Details
FeatUp method makes little alterations (such as shifting the image a few pixels to the left or right). It observes how an algorithm reacts to these small image movements. A single, clear, high-resolution set of deep features can be created by combining hundreds of slightly distinct deep feature maps.
Researchers hypothesized that there are some high-resolution features that, when blurred and wiggled, will match all of the lower-resolution features from the original wiggling photos. Through the use of this “game,” which provides feedback on their performance, they want to learn how to transform low-resolution features into high-resolution ones.
By making sure that the anticipated 3D item matches every 2D photo used to produce it, algorithms may generate a 3D model from several 2D images. Moreover, the methodology is comparable to that process. The high-resolution feature map predicted by FeatUp is consistent with low-resolution features retain their original semantics.
Comparison of image super-resolution methods using Deep Image Prior, Zero-Shot Super-Resolution (ZSSR), and Local Implicit Image Function (LIIF) – Source
In their search for a quick and effective solution, the team discovered that the normal PyTorch tools were inadequate for their requirements and developed a new kind of deep network layer. Compared to a naïve implementation in PyTorch, their proprietary layer was more than 100 times more efficient.
Small Objects Retrieval
The researcher’s approach enables accurate object localization in a different application known as small object retrieval. For instance, algorithms enhanced with FeatUp can detect small items like traffic cones, reflectors, lights. Also – potholes when their low-resolution siblings are unable to, even in busy road scenes. This illustrates how it can transform coarse characteristics and perform dense prediction tasks.
According to Stephanie Fu (2023) and another co-lead author on the new FeatUp, this is particularly important for time-sensitive activities, like a driverless car locating a traffic sign on a congested freeway.
Converting general guesses into precise localizations, can not only increase the accuracy of such jobs. It can also improve the dependability, interpretability, and credibility of these systems.
High-resolution FeatUp features that improve the retrieval of small objects and cluttered scenes – Source
The team also demonstrated how this new layer might enhance a wide range of techniques, such as depth prediction and semantic segmentation. This layer significantly increased the performance of any algorithm by enhancing the network’s capacity to process and comprehend high-resolution details.
Future Outlook
In terms of future goals, the group highlights FeatUp’s potential for broad use in the academic community and elsewhere. It is similar to data augmentation techniques. Dr. Fu claimed: “The goal is to make FeatUp a fundamental tool in deep learning. It perceives the world in greater detail without the computational inefficiency of traditional high-resolution processing.”
FAQs
FeatUp is a revolutionary algorithm (by MIT researchers, March 2024) that enables the conversion of low-resolution images and videos into useful ones, without the need for large retraining or complex modifications.
Deep networks and visual foundation models generate these features by dividing images into a grid of small squares. Then they process the squares collectively to identify the meaning of a picture. The typical size of each tiny square is between 16 and 32 pixels.
The team investigated two upsampling architectures: an implicit representation overfit to a single image and a single guided upsampling feedforward network that generalizes across images.
The main applications of the FeatUp algorithm include: object detection, discovering fine-grained details, and small objects retrieval.