
Image reconstruction is an AI-powered process central to computer vision. It involves transforming incomplete, degraded, or low-resolution images into complete, enhanced, or high-resolution versions. Image reconstruction serves an important role in fields like medical imaging, satellite imagery, and digital forensics. It excels in areas where the clarity and detail of an image can significantly influence outcomes.
In this article, we’ll provide a deep dive into using computer vision for image reconstruction.
About Image Reconstruction
Historically, image reconstruction evolved from basic interpolation techniques. This involves estimating missing pixels by averaging the values of surrounding pixels. In turn, this evolved into more sophisticated methods using machine learning and deep learning.
Following that, the development of Convolutional Neural Networks (CNNs) was a watershed moment in the field. CNNs are adept at capturing spatial hierarchies in images. This makes them ideal for high-resolution image reconstruction from their lower-resolution counterparts.
The introduction of the Super-Resolution Convolutional Neural Network (SRCNN) later demonstrated that deep learning models could outperform traditional image resolution methods.

Finally, Generative Adversarial Networks (GANs) pushed image reconstruction further by generating new image pixels with unprecedented realism. Specialized models like ESRGAN (Enhanced Super-Resolution Generative Adversarial Networks) set new standards for high-resolution outputs.
Fundamental Principles of Image Reconstruction
On the surface, the act of transforming an input image into a more refined version of itself sounds simple enough. However, image reconstruction is a complex process that involves several key steps. Some enhance specific image attributes, such as quality, detail, or dimensionality.
The general workflow goes as follows:
- Input Acquisition: The first step is to acquire an input image that is degraded, incomplete, or low resolution.
- Pre-processing: This involves doing some initial cleanup by correcting image noise or distortions. This step exists to provide the reconstruction algorithm with cleaner data to work on.
- Transformation: This step utilizes mathematical models to extract features or patterns essential for reconstruction. It also involves converting the image into a form where it’s easier to apply enhancements or corrections.
- Reconstruction: The core phase where the actual enhancement or completion of the image occurs. Usually, the model bases the exact action on the desired outcome. For example, enhancing resolution, filling in missing parts, enlarging, etc.
- Post-processing: The reconstructed image is fine-tuned to improve visual quality, adjust contrast, or sharpen details.
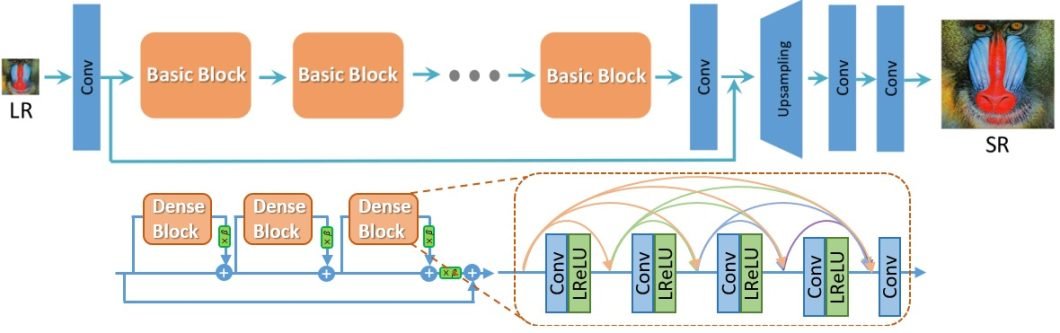
Methods
As you can see, image reconstruction is not a one-dimensional concept. There are different types of reconstruction, depending on the exact outcome required. For example:
- Interpolation: Fills in missing or new pixels by averaging or using more complex relationships from surrounding pixel values.
- Super-resolution: Enhances the resolution of an image by increasing its pixel density. This effectively creates a higher-resolution image from one or more low-resolution images.
- Reconstruction from Projections: This method reconstructs an image from multiple projection images taken around an object. This is especially common within medical imaging (e.g., CT scans).
- Deep Learning-Based Reconstruction: Utilizes neural networks to learn complex patterns for reconstructing or enhancing images. These are more sophisticated systems, often surpassing traditional image reconstruction methods in quality.
Similarly, it requires a variety of different mathematical models and algorithms to support the diverse applications of image reconstruction. While we briefly gave an introduction to CNNs and GANs, other significant models include:
- Autoencoders: Commonly used for denoising and reconstruction. Autoencoders learn to encode the input into a compressed representation before decoding it back to match the original input. In effect, it “learns” the essential features for reconstruction.
- Sparse Coding: This involves representing an image as a sparse combination of elements from a dictionary. This method is effective in reconstructing images by identifying and utilizing the most significant features.
- Radon Transform and Inverse Radon Transform: Fundamental in reconstruction from projections. For example, CT imaging helps reconstruct a 3D-generated image from multiple 2D projections.
- Neural Ordinary Differential Equations (ODEs): These models treat the process as a continuous dynamic system. It offers a novel approach to model the generation and reconstruction of images.
High-Resolution Image Reconstruction
Achieving high-resolution imagery is vital across a broad spectrum of applications. So much so that some use it as an umbrella goal for all image reconstruction activities. And it tends to base the case on applications like medical diagnostics, environmental monitoring, and urban planning. In these instances, a life-saving diagnosis or millions of dollars in funding may ride on a minute detail.
Similarly, in digital forensics, high-resolution images can uncover details that lead to breakthroughs in investigations. In entertainment, enhancing visual content may significantly improve the experience.
Classical imaging techniques, like bicubic interpolation, simply guess the values of missing pixels based on surrounding ones. This approach isn’t particularly effective at more complex scenes or in generalization across a wide spectrum of imagery. Modern deep-learning models leverage neural networks to predict and fill in missing details with much higher accuracy.
Training with larger and more diverse datasets also leads to dramatically improved generalization. In turn, this results in more natural-looking and less artifact-prone outputs.
Case Study: ESRGAN for High-Resolution Image Reconstruction
The ESRGAN model arguably represents the most significant leap in the quality of image super-resolution. Based on the seminal SRGAN, ESRGAN features major upgrades. This includes residual-in-residual dense blocks, RRDB without batch normalization, and a more robust adversarial loss. Collectively these reconstruction techniques enhance the perception-driven performance, yielding sharper and more detailed images.
The paper ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks explores this in great detail. In particular, the model achieved significantly more realistic textures, allowing it to win the PIRM2018-SR challenge. See the images shown below as an example of what ESRGAN can achieve compared to other methods.
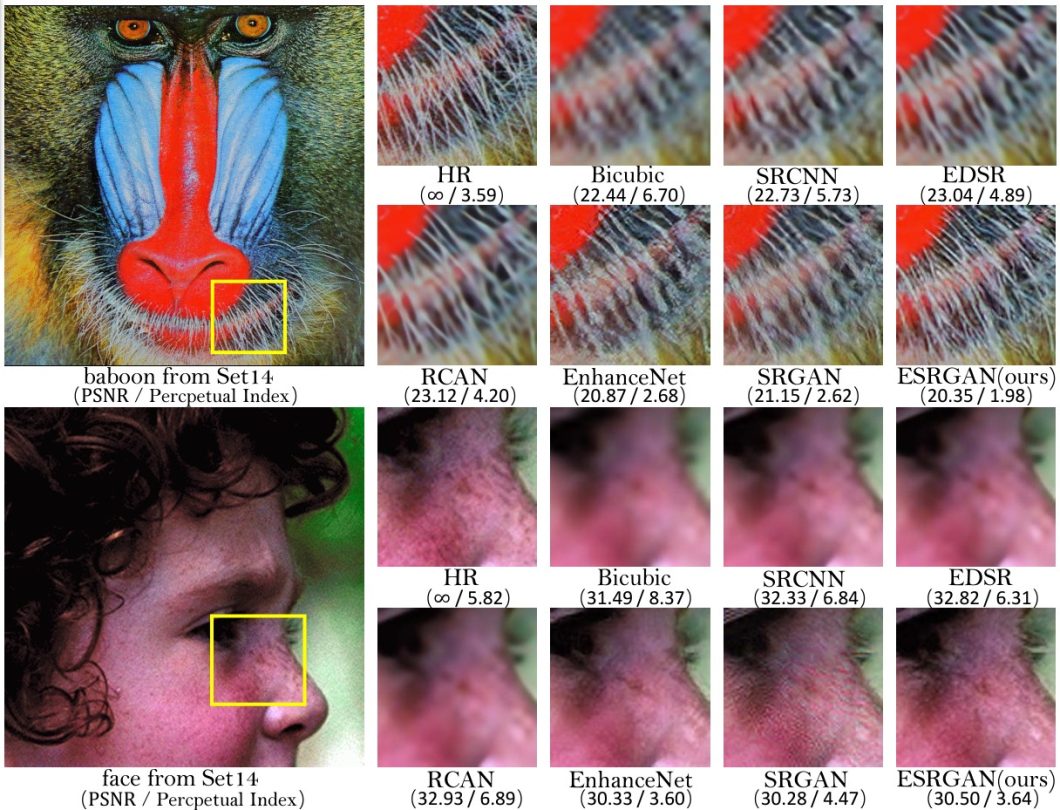
One notable potential application of ESRGAN is the enhancement of historical footage. The model has proven its capability to upscale century-old footage into 4K resolution. It brings history to life in stunning and unprecedented detail. Tuning ESRGAN models to work on video footage is a very active area of development and continued research.
Real-World Applications of Image Reconstruction
Let’s look at some of how practical applications of image reconstruction tech are reshaping various industries:
Medical Imaging
Practitioners leverage image reconstruction to enhance the clarity and detail of medical images, such as CT scans and MRIs. This is especially vital when imaging complex structures like the human brain to diagnose neurological conditions. For example, iterative reconstruction in CT scans can reduce and improve image quality, helping to accurately map brain activity. An example is GE Healthcare’s Revolution CT systems that utilize advanced image reconstruction algorithms.
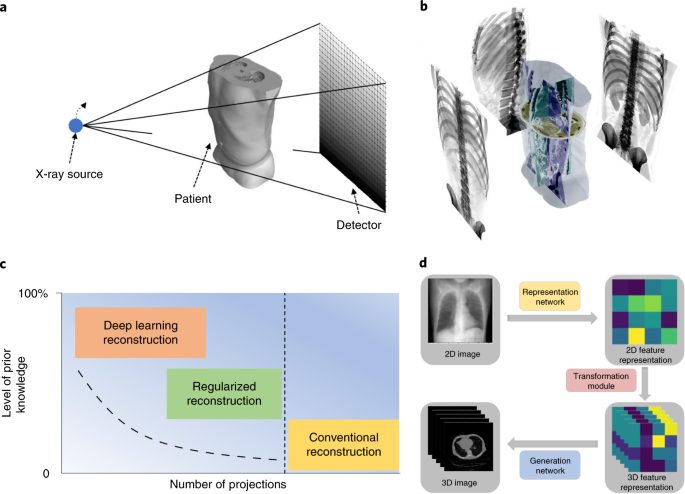
Satellite Imaging
The European Space Agency’s (ESA) Sentinel satellites employ image reconstruction techniques to enhance spatial resolution. In particular, due to theoretical, practical, and cost constraints, satellite imaging systems typically generate images with limited spatial resolution. Consequently, ESA’s ACT team is investigating using super-resolution image reconstruction techniques on imagery captured by the currently active satellite PROBA-V. This will aid in its environmental monitoring, urban planning, and climate change studies.
Digital Forensics and Restoration
Commercial tools can already leverage image reconstruction to recover and enhance historical or degraded images. Adobe Photoshop’s “Content-Aware Fill” feature, for example, uses advanced algorithms to reconstruct missing or damaged parts of images.

Entertainment and Media
In the entertainment industry, image reconstruction enhances visual content in movies, video games, and augmented and virtual reality. A notable application is the use of ESRGAN (Enhanced Super-Resolution Generative Adversarial Networks) for upscaling low-resolution video game textures. For example, modders use ESRGAN models to enhance textures for classic games like “Max Payne,” “Doom,” and “Morrowind.”

Challenges
Despite progress, existing methodologies still face difficulties in reducing artifacts and ensuring the fidelity of textures.
The intricate algorithms that reconstruct high-quality images demand significant computational power. This may impede the processing of data acquired from various sources. Luckily, most applications for image resolution are not particularly time-sensitive.
Tackling these issues necessitates ongoing research into:
- Algorithms that efficiently process and reconstruct from complex projection data,
- Strategies to avoid overfitting, and
- Techniques requiring less annotated training data.
The effectiveness of AI-driven reconstruction also hinges on the availability of vast, varied training datasets. In most areas, decades of historical or archived data already exist. However, organizing this data and making it available to researchers for training is still a major task. Plus, in medical imaging, there are serious patient privacy concerns, especially about regulations like HIPAA.

Also, regarding this, models may become too tailored to the training data, compromising their ability to generalize. As input images may come from a broad spectrum of data projections or contexts, this is a vital consideration.
Disregarding data collection, the capacity to reconstruct personal images accurately also raises privacy concerns. For example, someone may use it to reconstruct the face of someone who was purposefully blurred out or obscured. Others may use it to create synthetic images or deepfakes, which can undermine trust and spread disinformation.

The Cutting Edge of Image Reconstruction and Future Direction
The field of image reconstruction continues to evolve, marked largely by innovations in AI and computing. Currently, the most advanced models leading the way are those based on GANs, including ESRGAN and CNNs. However, the integration of AI with specialized hardware and quantum computing will improve computational efficiency for real-time applications.
Simultaneously, the evolution of unsupervised learning models will lead to improved generalization without a reliance on labeled datasets.
Software like TensorFlow, PyTorch, and OpenCV offers comprehensive libraries for developing complex image reconstruction algorithms. ImageNet, COCO, and DIV2K serve as essential datasets for model training and testing. Communities like CVPR, ICCV, and ECCV are a driving force in developing ethics, resources, and standards to support progress.
The Viso Suite platform includes features that streamline the deployment of computer vision applications, including image reconstruction. Viso Suite uses the power of cutting-edge AI models, providing access to advanced image reconstruction capabilities. This integration of technology and platform offers accessible, scalable options for deploying these solutions.