A knowledge Graph is a knowledge base that uses graph data structure to store and operate on the data. It provides well-organized human knowledge and also powers applications such as search engines (Google and Bing), question-answering, and recommendation systems.
A knowledge graph (semantic network) represents the information (storing not just data but also its meaning and context). This involves defining entities, abstract concepts, and their interrelations in a machine- and human-understandable format.
This allows for deducing new, implicit knowledge from existing data, surpassing traditional databases. By leveraging the graph’s interconnected semantics to uncover hidden insights, the knowledge base can answer complex queries that go beyond explicitly stored information.

History of Knowledge Graphs
Over the years, these systems have significantly evolved in complexity and capabilities. Here is a quick recap of all the advances made in knowledge bases:
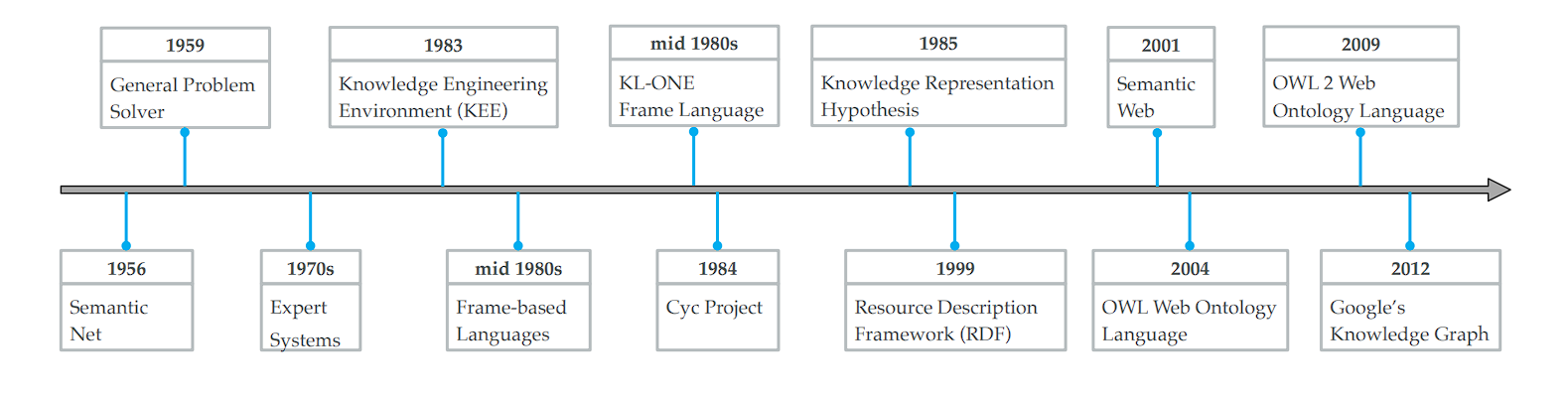
- Early Foundations:
- In 1956, Richens laid the groundwork for graphical knowledge representation by proposing the semantic net, marking the inception of visualizing knowledge connections.
- The era of Knowledge-Based Systems:
- MYCIN (developed in the early 1970s) is an expert system for medical diagnosis that relies on a rule-based knowledge base comprising around 600 rules.
- Evolution of Knowledge Representation:
- The Cyc project (1984): The project aims to assemble the basic concepts and rules about how the world works.
- Semantic Web Standards (2001):
- The introduction of standards like the Resource Description Framework (RDF) and the Web Ontology Language (OWL) marked significant advancements in the Semantic Web, establishing key protocols for knowledge representation and exchange.
- The Emergence of Open Knowledge Bases:
- Release of several open knowledge bases, including WordNet, DBpedia, YAGO, and Freebase, broadens access to structured knowledge.
- Modern Structured Knowledge:
- The term “knowledge graph” came into popularity in 2012 following its adoption by Google’s search engine, highlighting a knowledge fusion framework known as the Knowledge Vault (Google Knowledge Graph) for constructing large-scale knowledge graphs.
- Following Google’s example, Facebook, LinkedIn, Airbnb, Microsoft, Amazon, Uber, and eBay have explored knowledge graph technologies, further popularizing the term.
Building Block of Knowledge Graphs
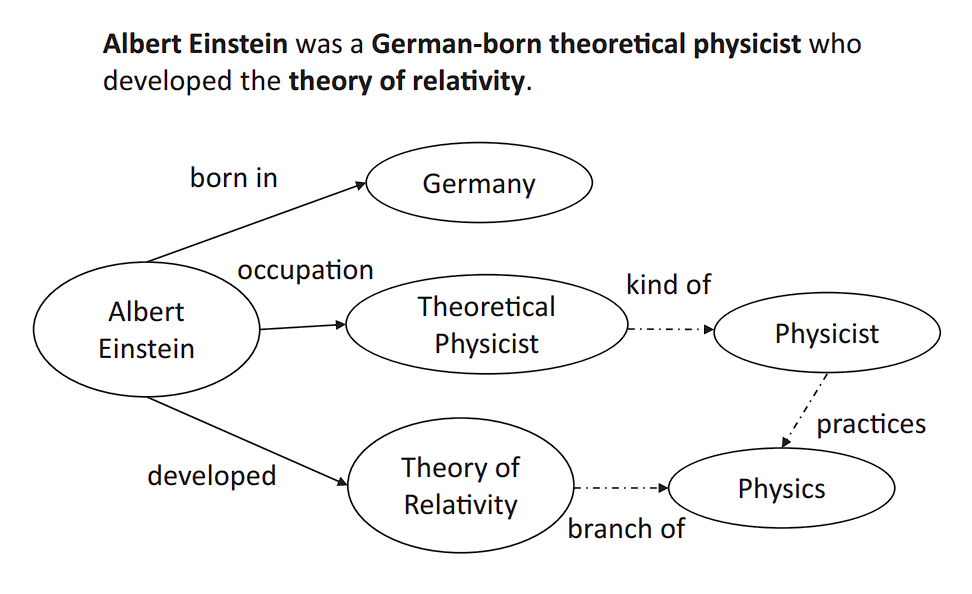
The core components of a knowledge graph are entities (nodes) and relationships (edges), which together form the foundational structure of these graphs:
Entities (Nodes)
Nodes represent the real-world entities, concepts, or instances that the graph is modeling. Entities in a knowledge graph often represent things in the real world or abstract concepts that one can distinctly identify.
- People: Individuals, such as “Marie Curie” or “Neil Armstrong”
- Places: Locations like “Eiffel Tower” or “Canada”
Relationships (Edges)
Edges are the connections between entities within the knowledge graph. They define how entities are related to each other and describe the nature of their connection. Here are a few examples of edges.
- Works at: Connecting a person to an organization, indicating employment
- Located in: Linking a place or entity to its geographical location or containment within another place
- Married to: Indicating a marital relationship between two people.
When two nodes are connected using an edge, this structure is called a triple.
Construction of Knowledge Graphs
KGs are formed by a series of steps. Here are these:
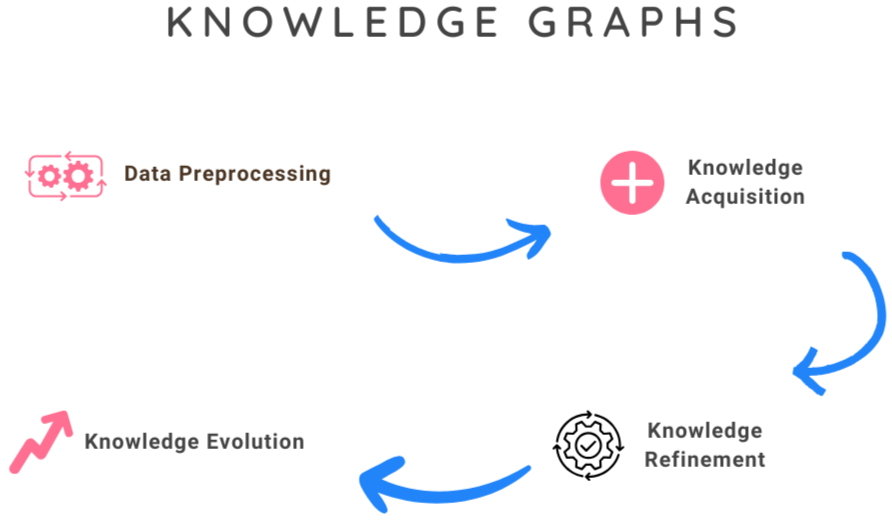
- Data Preprocessing: The first step involves collecting the data (usually scraped from the internet). Then pre-processing the semi-structured data to transform it into noise-free documents ready for further analysis and knowledge extraction.
- Knowledge Acquisition: Knowledge acquisition aims to construct knowledge graphs from unstructured text and other structured or semi-structured sources, complete an existing knowledge graph, and discover and recognize entities and relations. It consists of the following subtasks:
- Knowledge graph completion: This aims at automatically predicting missing links for large-scale knowledge graphs.
- Entity Discovery: It has further subtypes:
- Entity Recognition
- Entity Typing
- Entity Disambiguation or Entity Linking (EL)
- Relation extraction
- Knowledge Refinement: The next phase, after building the initial graph, focuses on refining this raw knowledge structure, known as knowledge refinement. This step addresses issues in raw knowledge graphs constructed from unstructured or semi-structured data. These issues include sparsity (missing information) and incompleteness (inaccurate or corrupted information). The key tasks involved in knowledge graph refinement are:
- Knowledge Graph Completion: Filling in missing triples and deriving new triples based on existing ones.
- Knowledge Graph Fusion: Integrating information from multiple knowledge graphs.
- Knowledge Evolution: The final step addresses the dynamic nature of knowledge. It involves updating the knowledge graph to reflect new findings, resolving contradictions with newly acquired information, and expanding the graph.
Data Preprocessing
Data preprocessing is a crucial step in creating knowledge graphs from text data. Proper data preprocessing enhances the accuracy and efficiency of machine learning models used in subsequent steps. This involves:
- Noise Removal: This includes stripping out irrelevant content, such as HTML tags, advertisements, or boilerplate text, to focus on the meaningful content.
- Normalization: Standardizing text by converting it to a uniform case, removing accents, and resolving abbreviations can reduce the complexity of ML and AI models.
- Tokenization and Part-of-Speech Tagging: Breaking down text into words or phrases and identifying their roles helps in understanding the structure of sentences, which is critical for entity and relation extraction.
Data Types
Based on the organization of data, it can be broadly classified into structured, semi-structured, and unstructured data. Deep Learning algorithms are primarily used to process and understand unstructured and semi-structured data.
- Structured data is highly organized and formatted in a way that simple, straightforward search algorithms or other search operations can easily search. It follows a rigid schema, organizing the data into tables with rows and columns. Each column specifies a datatype, and each row corresponds to a record. Relational databases (RDBMS) such as MySQL and PostgreSQL manage this type of data. Preprocessing often involves cleaning, normalization, and feature engineering.
- Semi-Structured Data: Semi-structured data does not reside in relational databases. It doesn’t fit neatly into tables, rows, and columns. However, it contains tags or other markers—examples: XML files, JSON documents, email messages, and NoSQL databases like MongoDB that store data in a format called BSON (binary JSON). Tools such as Beautiful Soup are used to extract relevant information.
- Unstructured data refers to information that lacks a predefined data model or is not organized in a predefined manner. It represents the most common form of data and includes examples such as images, videos, audio, and PDF files. Unstructured data preprocessing is more complex and can involve text cleaning and feature extraction. NLP libraries (such as SpaCy) and various machine learning algorithms are used to process this type of data.
Knowledge Acquisition in KG
Knowledge acquisition is the first step in the construction of knowledge graphs, involving the extraction of entities, resolving their coreferences, and identifying the relationships between them.
Entity Discovery
Entity discovery lays the foundation for constructing knowledge graphs by identifying and categorizing entities within data, which involves:
- Named Entity Recognition (NER): NER is the process of identifying and classifying key elements in text into predefined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc.
- Entity Typing (ET): Categorizes entities into more fine-grained types (e.g., scientists, artists). Information loss occurs if ET tasks are not performed, e.g., Donald Trump is a politician and a businessman.
- Entity Linking (EL): Connects entity mentions to corresponding objects in a knowledge graph.
NER in Unstructured Data
Named Entity Recognition (NER) plays a crucial role in information extraction, aiming to identify and classify named entities (people, locations, organizations, etc.) within text data.
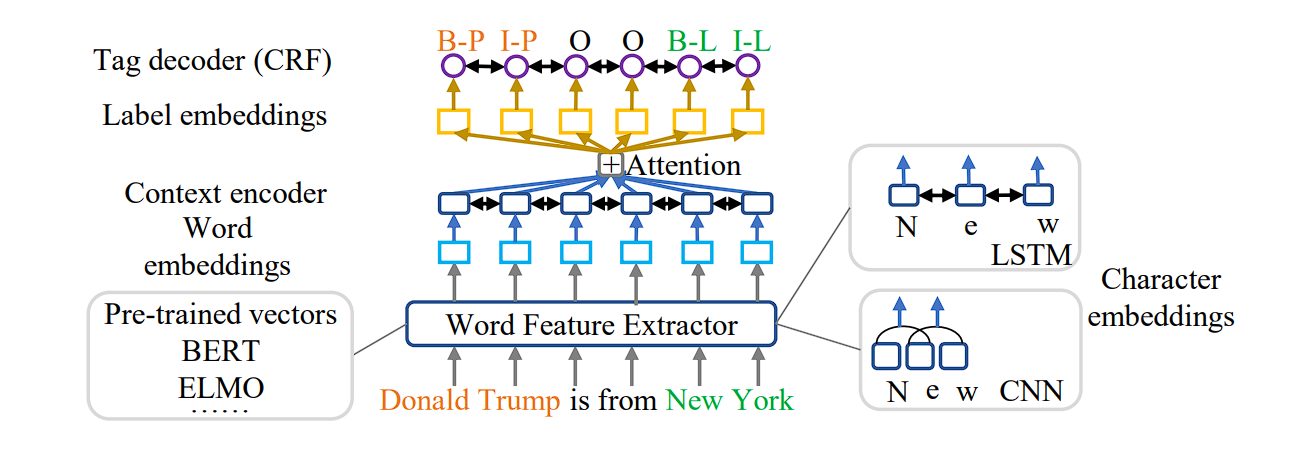
Deep learning models are revolutionizing NER, especially for unstructured data. These models treat NER as a sequence-to-sequence (seq2seq) problem, transforming word sequences into labeled sequences (word + entity type).
- Context Encoders: Deep learning architectures employ various encoders (CNNs, LSTMs, etc.) to capture contextual information from the input sentence. These encoders generate contextual embeddings that represent word meaning in relation to surrounding words.
- Attention Mechanisms: Attention mechanisms further enhance deep learning models by focusing on specific parts of the input sequence that are most relevant to predicting the entity tag for a particular word.
- Pre-trained Language Models: Utilizing pre-trained language models like BERT or ELMo injects rich background knowledge into the NER process. These models provide pre-trained word embeddings that capture semantic relationships between words, improving NER performance.
Entity Typing
Entity Recognition (NER) identifies entities within text data; in contrast, Entity Typing (ET) assigns a more specific, fine-grained type to these entities, like classifying “Donald Trump” as both a “politician” and a “businessman.”
Valuable details about entities are lost without ET. For instance, simply recognizing “Donald Trump” doesn’t reveal his various roles. Fine-grained typing heavily relies on context. For example, “Manchester United” could refer to the soccer team or the city itself depending on the surrounding text.
Similar to Named Entity Recognition (NER), attention mechanisms can focus on the most relevant parts of a sentence in Entity Typing (ET) to predict the entity type. This helps the model identify the specific words or phrases that contribute most to understanding the entity’s role.
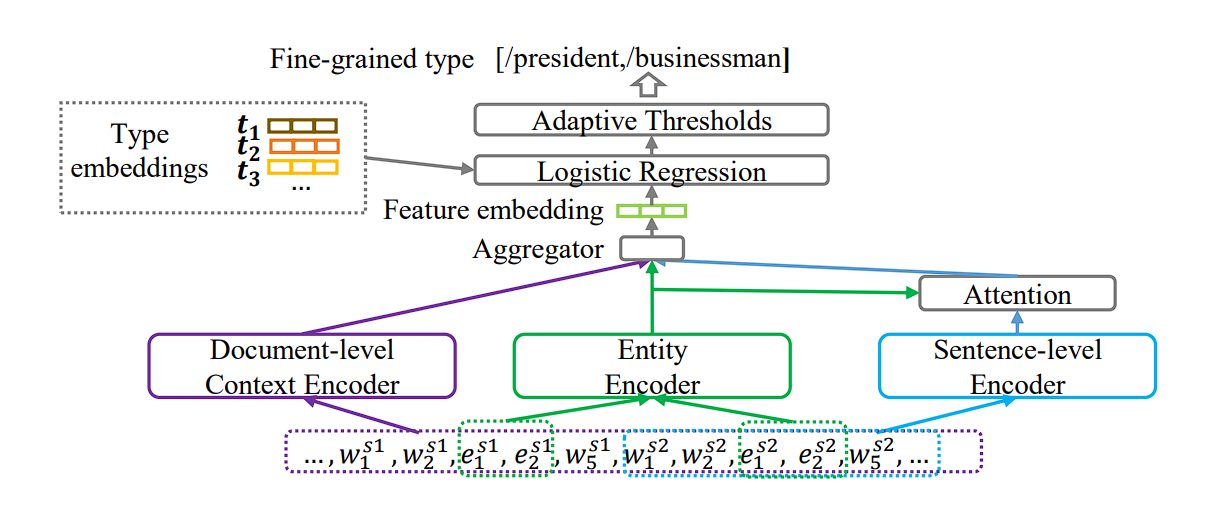
Entity Linking
Entity Linking (EL), also known as entity disambiguation, plays a vital role in enriching information extraction.
It connects textual mentions of entities in data to their corresponding entries within a Knowledge Graph (KG). For example, the sentence “Tesla is building a new factory.” EL helps disambiguate “Tesla” – is it the car manufacturer, the scientist, or something else entirely?
Relation Extraction
Relation extraction is the task of detecting and classifying semantic relationships between entities within a text. For example, in the sentence “Barack Obama was born in Hawaii,” relation extraction would identify “Barack Obama” and “Hawaii” as entities and classify their relationship as “born in.”
Relation Extraction (RE) plays a crucial role in populating Knowledge Graphs (KGs) by identifying relationships between entities mentioned in text data.
Deep Learning Architectures for Relation Extraction Tasks:
- CopyAttention: This model incorporates a unique mechanism. It not only generates new words for the relation and object entity but can also “copy” words directly from the input sentence. This is particularly helpful for relational phrases that use existing vocabulary from the text itself.
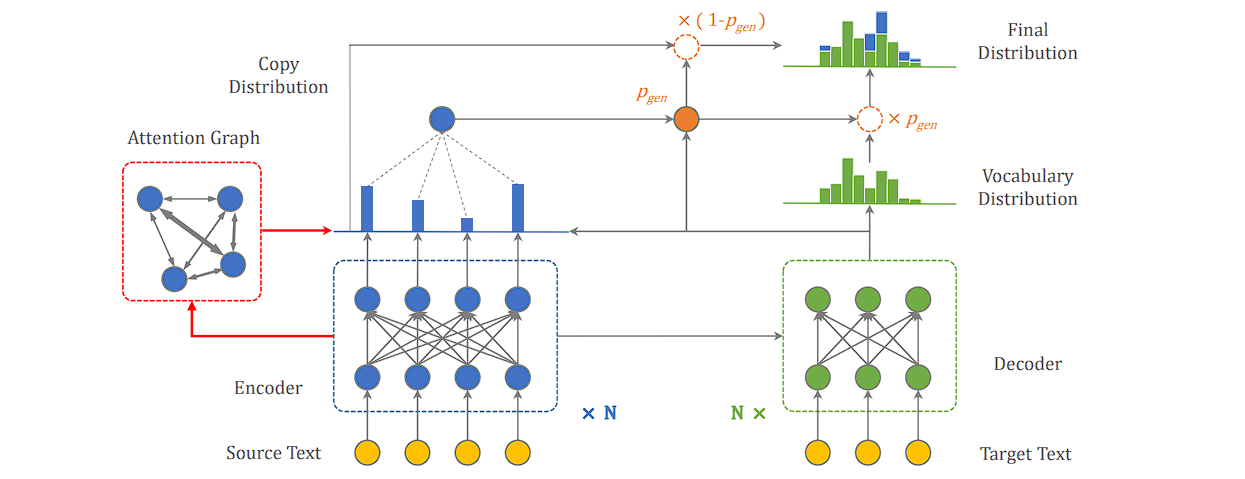
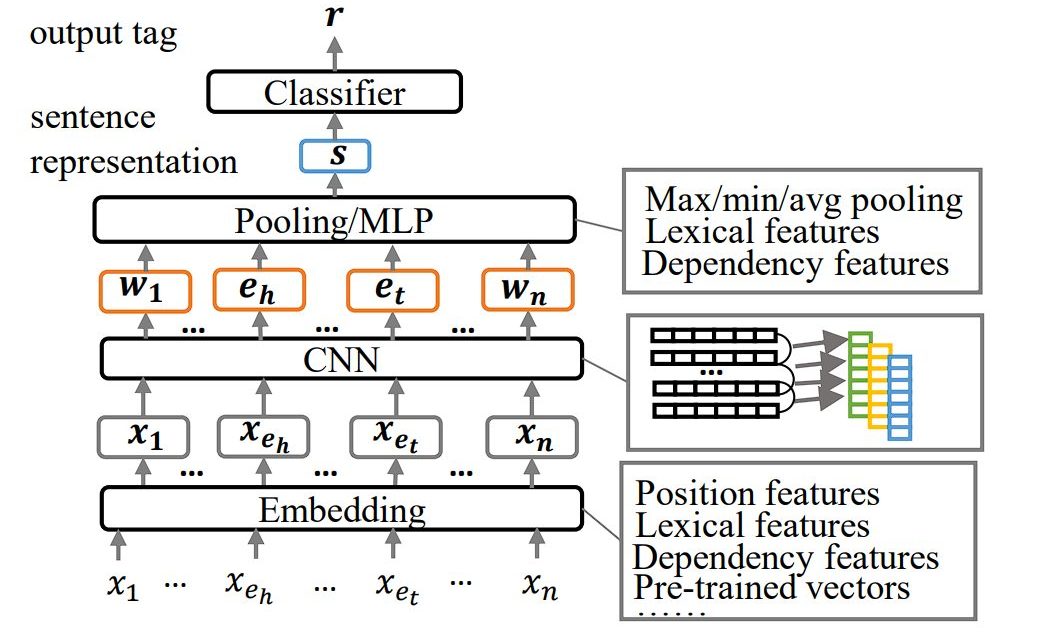
- CNN-based Models: It focuses on local contexts and combines convolutional layers with max-pooling strategies to aggregate local features. Using multi-scale convolution windows enhances feature aggregation further.

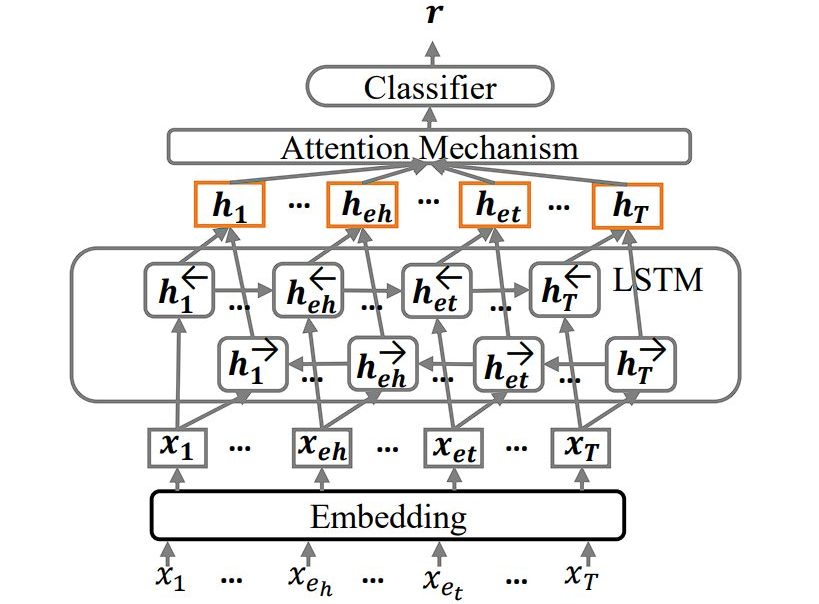
CNN Model-source - LSTM and BiLSTM Models: Captures long-distance dependencies between entities using recurrent neural architectures. BiLSTM models, in particular, employ inter-word attention mechanisms to focus on the relevant parts of the sentence for relation classification.

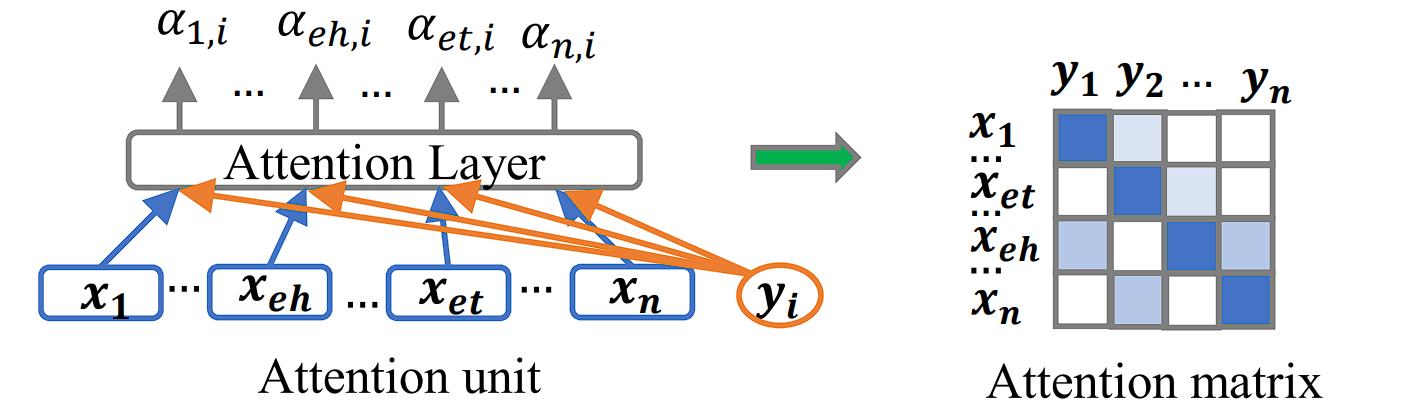
LSTM Model –source - Attention Mechanisms: This is also integrated into CNN and LSTM frameworks to select entity-relevant contexts and model salient interactions. Attention mechanisms help in focusing the model on the most informative parts of the sentence for determining relations.

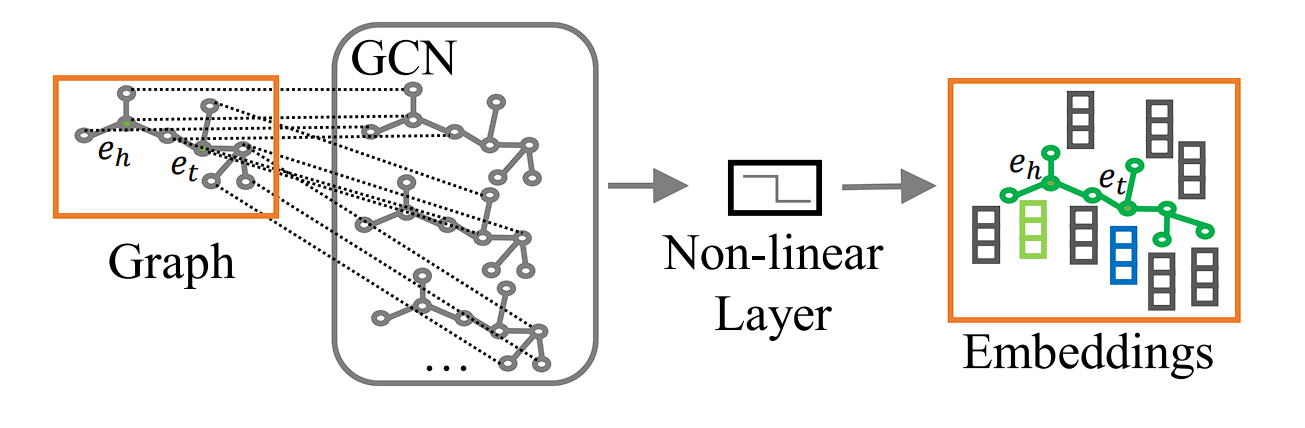
Attention Mechanism –source - Graph Convolutional Networks (GCNs): Utilize the structured information in sentences, such as dependency trees, to model relations at the graph level. GCNs have been combined with attention mechanisms and pre-trained models like BERT to leverage background knowledge and capture high-order features.

GCN Model –source
Tools and Technologies for Building and Maintaining
Building and managing knowledge graphs involves a combination of AI software tools, libraries, and frameworks. Each application is suited for different aspects of the process we discussed above. Here are to name a few.
Graph Databases(Neo4j): A graph database that offers a powerful and flexible platform for building knowledge graphs, with support for Cypher query language.
Graph Visualization and Analysis (Gephi): Gephi is an open-source network analysis and visualization software package written in Java, designed to allow users to intuitively explore and analyze all kinds of networks and complex systems. Great for researchers, data analysts, and anyone needing to visualize and explore the structure of large networks and knowledge graphs.
Data Extraction and Processing(Beautiful Soup & Scrapy): Python libraries for web scraping data from web pages.
Named Entity Recognition and Relationship Extraction:
- SpaCy: SpaCy is an open-source natural language processing (NLP) library in Python, offering powerful capabilities for named entity recognition (NER), dependency parsing, and more.
- Stanford NLP: The Stanford NLP Group’s software provides a set of natural language analysis tools that can take raw text input and give the base forms of words, their parts of speech, and parse trees, among other things.
- TensorFlow and PyTorch: Machine learning frameworks that can be used for building models to enhance knowledge graph representation.