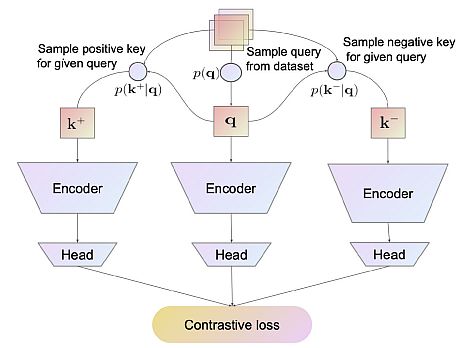
The goal of contrastive learning is to extract meaningful representations by comparing pairs of positive and negative instances. It assumes that dissimilar cases should be farther apart and put the comparable instances closer in the learning embedding space.
Contrastive learning (CL) enables models to identify pertinent characteristics and similarities in the data by presenting learning as a discrimination task. In other words, samples from the same distribution are pushed apart from one another in the embedding space. In addition, samples from other distributions are pulled to one another.
Get a Demo
Discover why enterprises choose Viso Suite for scalable, secure, and adaptable AI vision infrastructure.
Models can derive meaningful representations from unlabeled data through contrastive learning. Contrastive learning allows models to separate dissimilar instances while mapping comparable ones close together by utilizing similarity and dissimilarity.
This method has shown promise in a variety of fields, including reinforcement learning, computer vision, and natural language processing (NLP).
Overview of the Contrastive Representation Learning Framework – Source
The benefits of contrastive learning include:
Using similarity and dissimilarity to map instances in a latent space, CL is a potent method for extracting meaningful representations from unlabeled data.
Contrastive learning enhances model performance and generalization in a wide range of applications, including data augmentation, supervised learning, semi-supervised learning, and NLP.
Data augmentation, encoders, and projection networks are crucial elements that capture pertinent characteristics and parallels.
Contrastive learning employs different loss functions: Logistic loss, N-pair loss, InfoNCE, Triplet, and Contrastive loss.
How to Implement Contrastive Learning
Contrastive learning is a potent method that enables models to use vast quantities of unlabeled data while still enhancing performance with a small quantity of labeled data.
The main goal of contrastive learning is to drive dissimilar samples farther away and map comparable instances closer in a learned embedding space. To implement CL you have to perform data augmentation and train the encoder and projection network.
Data Augmentation
The goal of data augmentation is to expose the model to several viewpoints on the same instance and increase the data variations. Data augmentation creates diverse instances or augmented views by applying different transformations (perturbations) to unlabeled data. It is often the first step in contrastive learning.
Cropping, flipping, rotation, random cropping, and color changes are examples of common data augmentation techniques. Contrastive learning guarantees that the model learns to collect pertinent information despite input data changes by producing various instances.
Encoder and Projection Network
Training an encoder network is the next stage of contrastive learning. The augmented instances are fed into the encoder network, which then maps them to a latent representation space where significant similarities and features are recorded.
Usually, the encoder network is a deep neural network, like a recurrent neural network (RNN) for sequential data or a CNN for visual data.
The learned representations are further refined using a projection network. The output of the encoder network is projected onto a lower-dimensional space, also known as the projection or embedding space (a projection network).
The projection network makes the data less complicated and redundant by projecting the representations to a lower-dimensional space, which makes it easier to distinguish between similar and dissimilar instances.
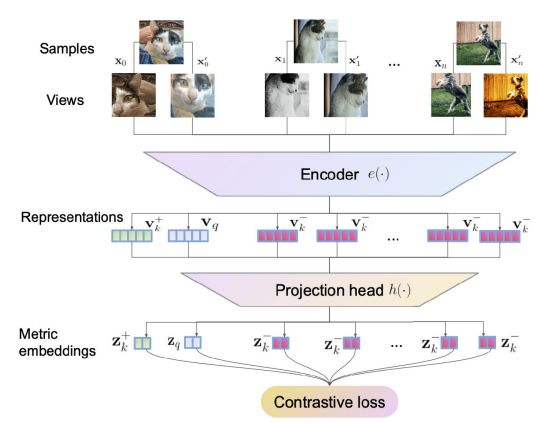
Contrastive learning in the Instance Discrimination pretext task for self-supervised visual representation learning – Source
Training and Optimization
After the loss function has been established, a large unlabeled dataset is used to train the model. The model’s parameters are iteratively updated during the training phase to minimize the loss function.
The model’s hyperparameters are frequently adjusted using optimization methods like stochastic gradient descent (SGD) or variations. Additionally, batch size updates are used for training, processing a portion of augmented instances at once.
During training, the model gains the ability to identify pertinent characteristics and patterns in the data. The iterative optimization process results in better discrimination and separation between similar and different instances, which also improves the learned representations.
Supervised vs Self-supervised CL
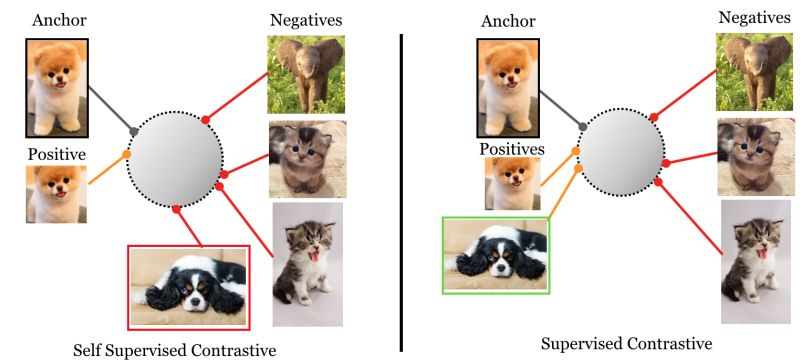
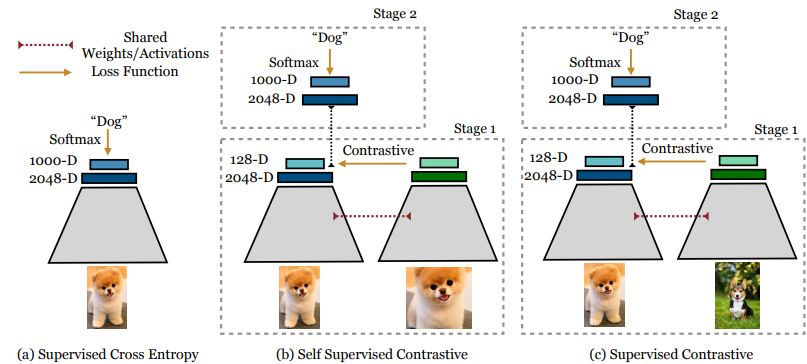
The field of supervised contrastive learning (SCL) systematically trains models to distinguish between similar and dissimilar instances using labeled data. Pairs of data points and their labels – which indicate whether the data points are similar or dissimilar, are used to train the model in SCL.
The model gains the ability to distinguish between similar and dissimilar cases by maximizing this goal, which enhances performance on subsequent challenges.
A different strategy is self-supervised contrastive learning (SSCL), which does not rely on explicit class labels but instead learns representations from unlabeled data. Pretext tasks can help SSCL to generate positive and negative pairings from the unlabeled data.
Supervised vs. self-supervised contrastive learning – Source
The purpose of these well-crafted pretext assignments is to motivate the model to identify significant characteristics and patterns in the data.
SSCL has demonstrated remarkable outcomes in several fields, including natural language processing and computer vision. SSCL is also successful in computer vision tasks such as object identification and image classification problems.
Loss Functions in CL
Contrastive learning utilizes multiple loss functions to specify the learning process’s goals. These loss functions let the model distinguish between similar and dissimilar instances and capture meaningful representations.
To identify pertinent characteristics and patterns in the data and improve the model’s capacity, we should know the various loss functions employed in contrastive learning.
Triplet Loss
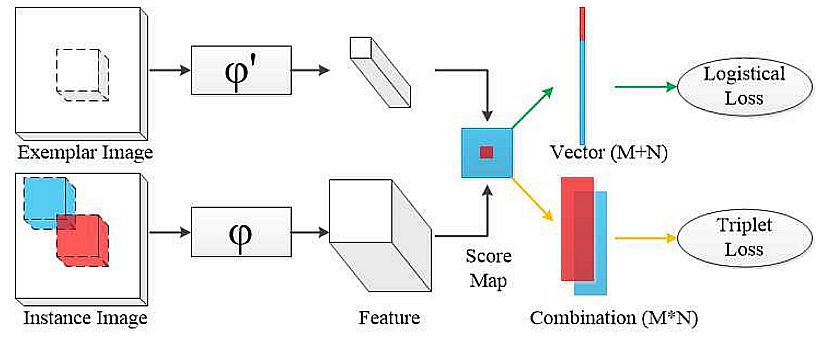
A common loss function used in contrastive learning is triplet loss. Preserving the Euclidean distances between instances is its goal. Triplet loss is the process of creating triplets of instances: a basis instance, a negative sample that is dissimilar from the basis, and a positive sample that is comparable to the basis.
The goal is to guarantee that, by a predetermined margin, the distance between the basis and the positive sample is less than the distance between the basis and the negative sample.
Training framework of the Triplet loss in Siamese network – Source
Triplet loss is very useful in computer vision tasks where collecting fine-grained similarities is essential, e.g. face recognition and image retrieval. However, because selecting meaningful triplets from training data can be difficult and computationally costly, triplet loss may be sensitive to triplet selection.
N-pair Loss
An expansion of triplet loss, N-pair loss, considers several positive and negative samples for a specific basis instance. N-pair loss tries to maximize the similarity between the basis and all positive instances while reducing the similarity between the basis and all negative instances. It doesn’t compare a basis instance to a single positive (negative) sample.
N-pair loss provides strong supervision learning, which pushes the model to grasp subtle correlations among numerous samples. It enhances the discriminative power of the learned representations and can capture more intricate patterns by taking into account many instances at once.
N-pair loss has applications in multiple tasks, e.g., image recognition, where identifying subtle differences among similar instances is crucial. By utilizing a variety of both positive and negative samples it mitigates some of the difficulties related to triplet loss.
Contrastive Loss
One of the basic loss functions in contrastive learning is contrastive loss. In the learned embedding space, it seeks to reduce the agreement between instances from separate samples and maximize the agreement between positive pairs (instances from the same sample).
Training setup for the Self-supervised Contrastive loss and Supervised Contrastive loss – Source
The contrastive loss function is a margin-based loss in which a distance metric, and measures how similar two examples are. To calculate the contrastive loss – researchers penalized positive samples for being too far apart and negative samples for being too close in the embedding space.
Contrastive loss is efficient in a variety of fields, including computer vision and natural language processing. Moreover, it pushes the model to develop discriminative representations that capture significant similarities and differences.
Contrastive Learning Frameworks
Many contrastive learning frameworks have become well-known in deep learning in recent years because of their efficiency in learning potent representations. Here we’ll elaborate on the most popular contrastive learning frameworks:
NNCLR
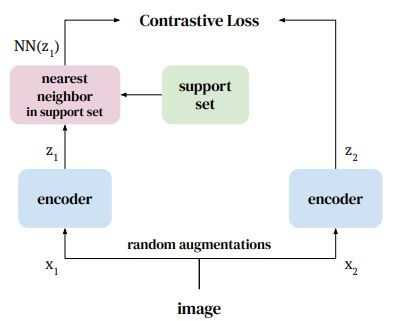
The Nearest-Neighbor Contrastive Learning (NNCLR) framework attempts to use different images from the same class, instead of augmenting the same image. In opposite, most methods treat different views of the same image as positives for a contrastive loss.
NNCLR Training – a simple self-supervised learning method that uses similar examples – Source
By sampling the dataset’s nearest neighbors in the latent space and using them as positive samples, the NNCLR model produces a more varied selection of positive pairs. It also improves the model’s learning capabilities.
Similar to the SimCLR framework, NNCLR employs the InfoNCE loss. However, the positive sample is now the basis image’s closest neighbor.
SimCLR
The efficacy of the self-supervised contrastive learning framework Simple Contrastive Learning of Representations (SimCLR) in learning representations is rather high. By utilizing a symmetric neural network architecture, a well-crafted contrastive aim, and data augmentation, it expands on the ideas of contrastive learning.
SimCLR’s main goal is to minimize the agreement between views from various instances. Also, it maximizes the agreement between augmented views of the same instance. To provide effective and efficient contrastive learning, the system uses a large-batch training approach.
In several fields, such as CV, NLP, and reinforcement learning, SimCLR has shown outstanding performance. It demonstrates its efficacy in learning potent representations by outperforming previous approaches in several benchmark datasets and tasks.
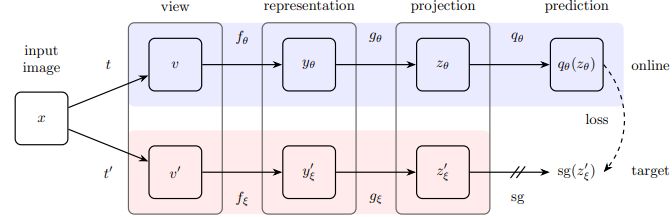
BYOL
Bootstrap Your Own Latent (BYOL) updates the target network parameters in the self-supervised contrastive learning framework online. Using a pair of online and target networks, it updates the target network by taking exponential moving averages of the weights in the online network. BYOL also emphasizes learning representations without requiring unfavorable examples.
The approach decouples the similarity estimation from negative samples while optimizing agreement between enhanced perspectives of the same instance. In several fields, such as computer vision and NLP, BYOL has shown remarkable performance. In addition, it has produced state-of-the-art results and demonstrated notable improvements in representation quality.
CV Applications of Contrastive Learning
Contrastive Learning has been successfully applied in the field of computer vision. The main applications include:
Object Detection: A contrastive self-supervised method for object detection employs two techniques: 1) multi-level supervision to intermediate representations, and 2) contrastive learning between the global image and local patches.
Semantic Segmentation: applying contrastive learning for the segmentation of real images. It utilizes supervised contrastive loss to pre-train a model and the conventional cross-entropy for fine-tuning.
Video Sequence Prediction: The model employs a contrastive machine learning algorithm for unsupervised representation learning. Engineers utilize some of the sequence’s frames to enhance the training set as positive/negative pairs.
Remote Sensing: The model employs a self-supervised pre-training and supervised fine-tuning technique to segment data from remote sensing images.
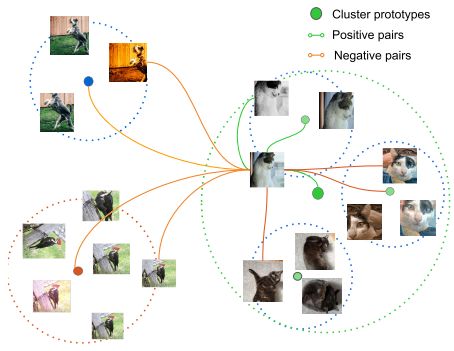
Illustration of contrastive methods on clusters – Source
What’s Next?
Today, contrastive learning is gaining popularity as a method for improving current supervised and self-supervised learning approaches. Methods based on contrastive learning have improved performance on tasks involving representation learning and semi-supervised learning.
Its basic idea is to compare samples from a dataset and push or pull representations in the original images according to whether the samples are part of the same or different distribution (e.g., the same object in object detection tasks, or class in classification models).
FAQs
Contrastive learning drives dissimilar samples farther away and maps comparable instances closer in a learned embedding space.
Loss functions specify the goals of the machine learning model. They let the model distinguish between similar and dissimilar instances and capture meaningful representations.
The main frameworks for contrastive learning include Nearest-Neighbor Contrastive Learning (NNCLR), SimCLR, and Bootstrap Your Own Latent (BYOL).
The applications of contrastive learning in computer vision include object detection, semantic segmentation, remote sensing, and video sequence prediction.