
Deep Reinforcement Learning is the combination of Reinforcement Learning and Deep Learning. This technology enables machines to solve a wide range of complex decision-making tasks. Thus, opening new applications across key sectors such as healthcare, smart grids, self-driving cars, and many more.
What is Deep Reinforcement Learning?
Reinforcement Learning Concept
Reinforcement Learning (RL) is a subfield of Artificial Intelligence (AI) and machine learning. The Learning Method deals with learning from interactions with an environment to maximize a cumulative reward signal.
Reinforcement Learning relies on the concept of Trial and Error. An RL agent performs a sequence of actions in an uncertain environment. This is to learn from experience by receiving feedback, aka rewards and penalties. We deliver feedback in the form of a Reward Function, thus maximizing reward.
With the gathered experience, the AI agent should be able to optimize objectives in the form of cumulative rewards. The objective of the agent is to learn the optimal policy. This is a mapping between states and actions that maximizes the expected cumulative reward.
Behavioral psychology (Sutton, 1984) inspired the Reinforcement Learning Problem. It led to the introduction of a formal framework to solve decision-making tasks. The concept is that an agent can learn by interacting with its environment, similar to a biological agent.
Reinforcement Learning is different from supervised learning, unsupervised learning, and other methods. Other than those, it does not rely on a labeled dataset or a pre-defined set of rules. Instead, it uses trial and error to learn from experience and improve its policy over time.
Reinforcement Learning Methods
Some of the common Reinforcement Learning methods are:
- Value-Based Methods: Estimate the value function, the expected cumulative reward for taking an action in a particular state. Q-Learning and SARSA are popular Value-Based Methods.
- Policy-Based Methods: Policy-based methods directly learn the policy. This is a mapping between states and actions that maximizes the expected cumulative reward. REINFORCE and Policy Gradient Methods are common Policy-Based Methods.
- Actor-Critic Methods: Combine Value-Based and Policy-Based Methods with two separate networks, the Actor and the Critic. The Actor selects actions based on the current state, while the Critic evaluates the goodness of the Actor’s actions. We find this by estimating the value function. The Actor-Critic algorithm updates the policy using the TD (Temporal Difference) error.
- Model-Based Methods: Learn the environment’s dynamics by building a model of the environment. This includes the state transition function and the reward function. The model allows the agent to simulate the environment and explore various actions before taking them.
- Model-Free Methods: These methods do not require the reinforcement learning agent to build a model of the environment. Instead, they learn directly from the environment by using trial and error to improve the policy. Temporal difference learning (TD-Learning), State–Action–Reward–State–Action (SARSA), and Q-Learning are Model-Free Methods.
- Monte Carlo Methods: Follow a simple concept where agents learn about states and rewards when interacting with the environment. Monte Carlo Methods are applicable to both Value-Based and Policy-Based Methods.
Active Learning improves the learning efficiency and performance of agents by learning from the most informative and relevant samples. This is useful in situations where:
- The state space is large or complex
- The agent may not be able to explore all possible states and actions in a reasonable amount of time
Markov Decision Process (MDP)
The Markov Decision Process (MDP) is a mathematical framework in Reinforcement Learning (RL) to model sequential decision-making problems. It provides a formal representation of the environment in states, actions, transitions between states, and a reward function definition.
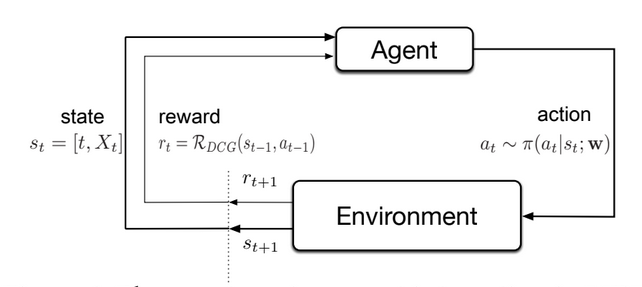
The MDP framework assumes that the current state depends only on the previous state and action. This simplifies the problem and makes it computationally tractable. Using the Markov Decision Process, reinforcement learning algorithms can compute the optimal policy that maximizes the expected cumulative reward.
The MDP provides a framework for evaluating the performance of different RL algorithms and comparing them to each other.
Deep Reinforcement Learning
In the past few years, Deep Learning techniques have become very popular. Deep Reinforcement Learning combines Reinforcement Learning with Deep Learning techniques to solve challenging sequential decision-making problems.
The use of deep learning is most useful in problems with high-dimensional state space. With deep learning, Reinforcement Learning solves complicated tasks with lower prior knowledge. This is because of its ability to learn different levels of abstraction from data.
To use reinforcement learning successfully in situations approaching real-world complexity, however, agents receive a difficult task. They must derive efficient representations of the environment from high-dimensional sensory inputs. Then, they must use these to generalize experience to new situations.
This makes it possible for machines to mimic some human problem-solving capabilities, even in high-dimensional space. Only a few years ago, this problem-solving was difficult to conceive.
Applications of Deep Reinforcement Machine Learning
Some prominent projects used deep Reinforcement Learning in games with results that are far beyond what is humanly possible. RL techniques have demonstrated their ability to tackle a wide range of problems that were previously unsolved.
Deep Reinforcement Learning in Gaming
Deep RL has achieved human-level or superhuman performance for many two-player or even multi-player games. Such achievements with popular games are significant because they show the potential of deep Reinforcement Learning. With games, we have good or even perfect simulators, and can easily generate unlimited data.
- Atari 2600 games: Machines achieved superhuman-level performance in playing Atari games.
- Go: Mastering the game of Go with deep neural networks.
- Poker: AI can beat professional poker players in the game of heads-up no-limit Texas hold ’em.
- Quake III: An agent achieved human-level performance in a 3D multiplayer first-person video game. It used only pixels and game points as input.
- Dota 2: An AI agent learned to play Dota 2 by playing over 10,000 years of games against itself (OpenAI Five).
- StarCraft II: An agent learned how to play StarCraft II with a 99\% win rate. It used only 1.08 hours on a single commercial machine.
Deep Reinforcement Training in the Real World
Those achievements set the basis for the development of real-world deep reinforcement learning applications:
- Robot control: We apply robust adversarial reinforcement learning as an agent operating in the presence of an adversary. This adversary applies disturbance forces to the system. The machine learns an optimal destabilization policy. AI-powered robots have a wide range of applications, e.g. in manufacturing, supply chain automation, healthcare, and many more.
- Self-driving cars: Deep Reinforcement Learning often plays a role in autonomous driving. Autonomous driving scenarios involve interacting agents and require negotiation and dynamic decision-making, which suits Reinforcement Learning.
- Healthcare: Artificial Intelligence (AI) has enabled the development of advanced intelligent systems. These can learn about clinical treatments, provide clinical decision support, and discover breakthroughs with Big Data. Reinforcement Learning enabled advances such as personalized medicine to systematically optimize patient health care. In particular, for chronic conditions and cancers, with individual patient information.
- Other: In terms of applications, many areas will feel the impact of possibilities brought by deep Reinforcement Learning. These include finance, business management, marketing, resource management, education, smart grids, transportation, science, engineering, and art. Deep RL systems are already in production environments. For example, Facebook uses Deep Reinforcement Learning for pushing notifications and for faster video loading with smart prefetching.

Challenges of Deep Reinforcement Learning
Multiple challenges arise in applying Deep Reinforcement Learning algorithms. In general, it is difficult to explore the environment efficiently or generalize good behavior in a slightly different context. Therefore, researchers proposed multiple algorithms for the Deep Reinforcement Learning framework. These depend on a variety of settings of the sequential decision-making tasks.
Many challenges appear when moving from a simulated setting to solving real-world problems.
- Limited agent freedom: Even when the task is well-defined, sometimes the agent cannot interact sufficiently in the environment. This may be due to safety, cost, or time constraints.
- Reality gap: Situations where the agent cannot interact with the true environment, only with an inaccurate simulation of it. The reality gap describes the difference between the learning simulation and the effective real-world domain.
- Limited observations: For some cases, the acquisition of new observations may not be possible anymore (e.g., the batch setting). These scenarios occur in condition-dependent tasks like weather conditions or trading markets, i.e., stock markets.
How to address those challenges:
- Simulation: For many cases, a solution is the development of a simulator that is as accurate as possible.
- Algorithm Design: The design of the learning algorithms and their level of generalization have a great impact.
- Transfer Learning: A crucial technique to utilize external task expertise to benefit the learning process of the target task.
Reinforcement Machine Learning and Computer Vision
Computer Vision is about how computers gain understanding from digital images and video streams. Computer Vision has been making rapid progress recently, and deep learning plays an important role.
Reinforcement learning is effective for many computer vision problems, like image classification, object detection, face detection, captioning, and more. It is key for interactive perception, where perception and interaction with the environment would be mutually beneficial.
This includes tasks like:
- Object segmentation
- Articulation model estimation
- Object dynamics learning
- Haptic property estimation
- Object recognition or categorization
- Multimodal object model learning
- Object pose estimation
- Grasp planning
- Manipulation skill learning
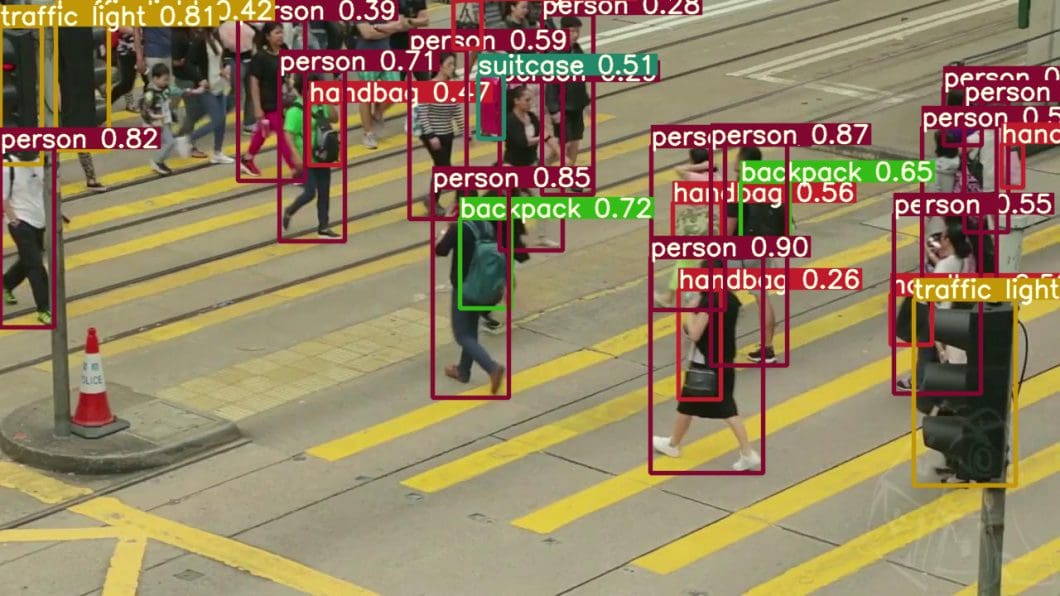
More topics of applying Deep Reinforcement Learning to computer vision tasks, such as
- Semantic parsing of large-scale 3D point clouds for indoor scene understanding
- Teaching a machine to read maps with deep reinforcement learning
- Image-based data augmentation tasks and deep reinforcement learning
- View Planning, generating a sequence capable of sensing all accessible areas of an object represented as a 3D model
- Face hallucination, generating a high-resolution face image from a low-resolution input image
What’s Next for Deep Reinforcement Learning?
In the future, we expect to see deep reinforcement algorithms going in the direction of meta-learning. We can embed previous knowledge, for example, in the form of pre-trained Deep Neural Networks. This improves performance and reduces training time.
Advances in transfer learning capabilities will allow machines to learn complex decision-making problems in simulations, gathering samples flexibly. They will then use the learned skills in real-world environments.
Check out our guide about supervised learning vs. unsupervised learning, or explore another related topic:
- Examples, methods, and applications of Self-Supervised Learning
- Explore an extensive list of Computer Vision Applications
- Learn about deep learning-based Mask R-CNN
- Read our easy-to-understand guide about Image Segmentation