
Faster R-CNN is a two-stage object detection algorithm. It uses a Region Proposal Network (RPN) and Convolutional Neural Networks (CNNs) to identify and locate objects in complex real-world images.
Developed by Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun in 2015, this model builds upon its predecessors, R-CNN and Fast R-CNN. Compared to its predecessors, this one is more efficient and accurate in identifying objects within images. The innovative architecture and training process of Faster R-CNN made it a cornerstone in computer vision applications, from autonomous driving to medical imaging.
Background Knowledge of Faster R-CNN
To learn Faster R-CNN, we must first go through those concepts that led to its development.
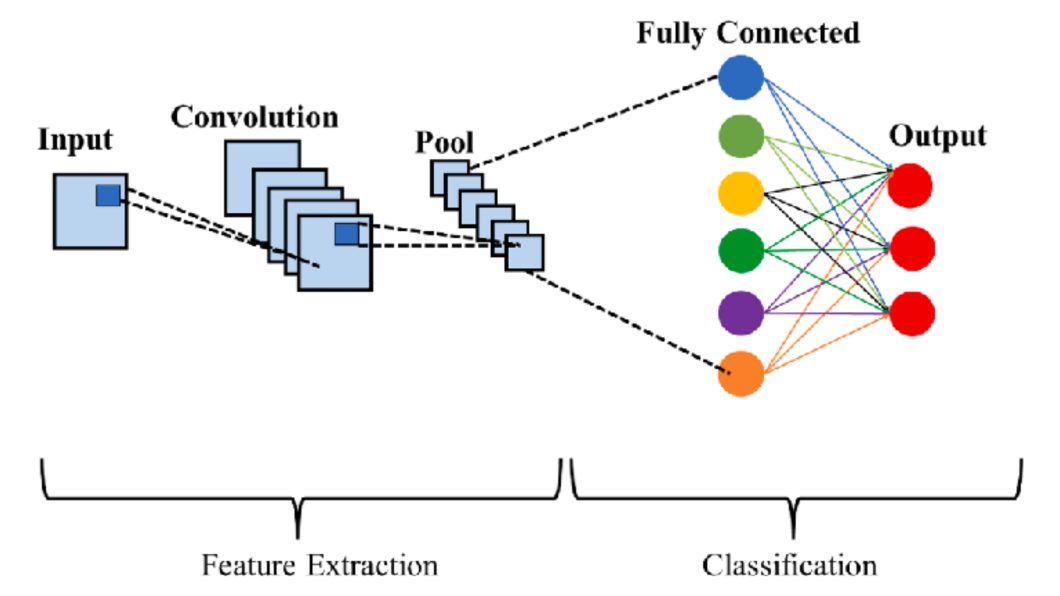
Convolution Neural Network (CNN)
A Convolutional Neural Network is a type of deep neural network that detects objects in an image. The main components in this CNN architecture are as follows:
- Convolutional layers: These are the primary building blocks of a network. Each convolutional layer applies multiple filters to the input. These filters extract feature maps from single image input.
- Activation functions: Basically, they are ReLU (Rectified Linear Unit) and add nonlinearity to the network so that it can catch complex patterns.
- Pooling layers: These layers down-sample feature maps in spatial dimensions. The most frequently used technique is max pooling.
- Fully connected layers: They are often placed at the end of the network and interact with each of them to give a final decision while collecting global information.
- Output layer: This is the final layer that produces the network output and, in most cases, applies softmax activation to classify.
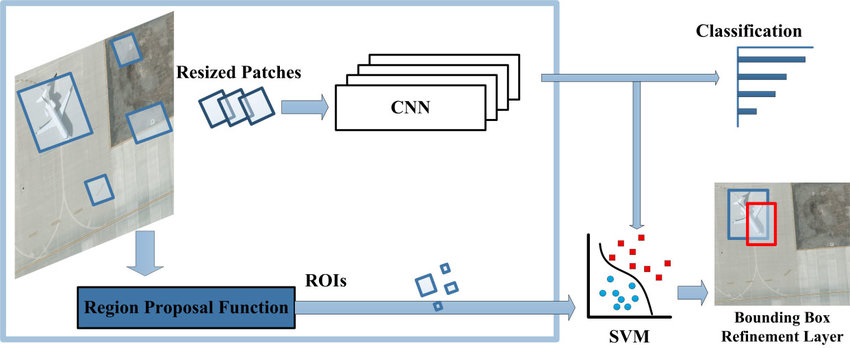
R-CNN
The first successful model to apply CNNs in object detection tasks was the Region-based Convolutional Neural Network (R-CNN).
The R-CNN pipeline works in such a way that the input image goes through pre-processing until proposals in different regions are generated. Each proposal is resized and passed through the CNN for feature extraction. These features are then used to deduce the object’s presence and class of interest from the Support Vector Machines (SVMs) classifiers. Finally, the bounding box regressor fine-tunes the locations of the objects.
Here is the R-CNN architecture delineating how it processes input images for object detection tasks:
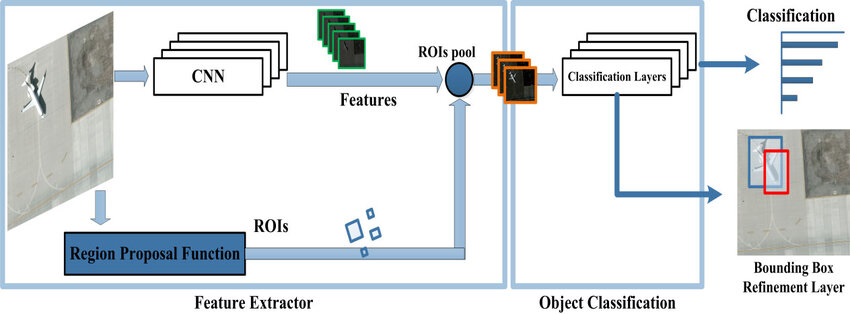
Fast R-CNN
Fast R-CNN addresses many of R-CNN’s limitations. Instead of processing each region proposal separately, Fast R-CNN applies the CNN to the entire image at once. It then uses a Region of Interest (RoI) pooling layer to extract fixed-size feature maps for each proposal from the CNN’s output. These features pass through fully connected layers for classification and bounding box regression.
Key Components of Faster R-CNN
Faster R-CNN builds upon the success of Fast R-CNN by introducing a novel component: the Region Proposal Network (RPN). RPN allows the model to generate its region proposals, creating an end-to-end trainable object detection system. Let’s explore the key components that make Faster R-CNN so effective.
Backbone Network
The backbone network acts as the feature extractor for Faster R-CNN. Generally, this is a pre-trained Convolutional Neural Network, for example, ResNet and VGG. This network processes the entire input image to get a rich feature map that subsequently encodes the hierarchical visual information.
This output of the backbone network is a feature map of a spatially smaller size than the input image and with a deeper channel size. This compacted form contains very high-level semantic information, which is highly significant for both region proposal and object classification tasks.
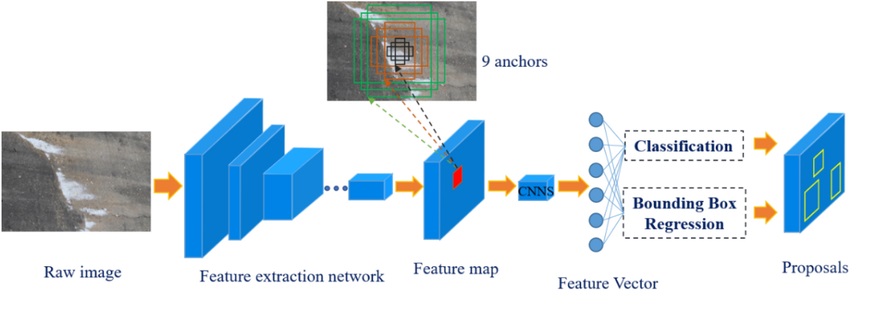
Region Proposal Network (RPN)
RPN is the heart of the Faster R-CNN. It is a fully convolutional network. The input of RPN is the feature map produced by the backbone network. The process of generating region proposals is accomplished by sliding a small network over the feature map.
At each location of a sliding window, it predicts multiple region proposals, each having a classification score. This score indicates how likely an object might be present in the input image.
RPN introduces the concept of anchors, predefined boxes of various scales and aspect ratios centered at each location in the feature map.
For each anchor, the RPN predicts two things:
- An “objectness or classification” score indicates the probability that the anchor contains an object of interest.
- Bounding box refinements which are adjustments to the anchor’s coordinates to better fit the object.
RoI Pooling Layer
The Region of Interest (RoI) pooling layer is crucial for handling the variable sizes of region proposals. It takes fixed-size feature maps from the region proposals regardless of their original size and/or aspect ratio.
In other words, RoI pooling divides each of the region proposals into a fixed grid, say 7×7, and then performs a max-pool over features residing in each of the grid cells. This operation outputs a fixed-sized feature map for each proposal, generally having dimensions such as 7x7x512.
In this manner, RoI pooling allows Faster R-CNN to operate over multiple region proposals with different sizes in a computationally efficient manner. These fixed-size inputs also permit the fully connected layers in a network to be present for the final classification and regression.
Classification and Bounding Box Regression Heads
The last component of Faster R-CNN is comprised of two parallel fully connected layers:
- A classification head that predicts the class of the object in each region proposal.
- A bounding box regression head that further refines the coordinates of the detected object.
These heads act on the fixed-sized feature maps that are outputted by the RoI pooling layer.
The classification head, in this case, is a softmax activation that returns class probabilities for the proposals. Through the bounding box regression head, we get refined coordinates per class, and this allows the network to predict the bounding box correctly, finally making the needed adjustment.
The loss function for training these heads combines cross-entropy loss for classification and smooth L1 loss for bounding box regression. This approach allows Faster R-CNN to optimize simultaneously over object classification accuracy and localization.
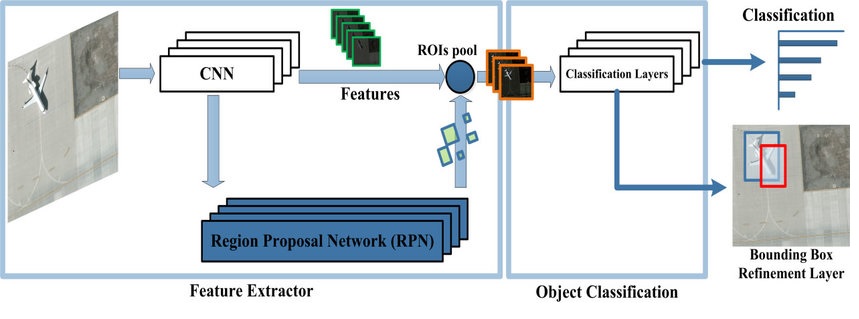
The Architecture of Faster R-CNN
Faster R-CNN unifies these components into a single network. An input image first goes through the backbone CNN. The resulting feature map is fed into the RPN and ROI pooling layer. The RPN scans the given image with different anchor boxes and proposes regions by calculating scores, while the ROI pooling layers take these region proposals and perform object classification.
A classification layer/head predicts the class of an object in each region proposal. The classification data is fed into the bounding box regression head, which performs further regression of the coordinates and yields the final detection output.
Training Process
Training Faster R-CNN requires careful consideration due to its complex architecture. Researchers have come up with several strategies for training these models effectively.
Some of them are:
Alternating Training Strategy
In this approach, the RPN and detection network train separately in alternating steps. First, we train the RPN, and then its proposals are used to train the detection network. Then, the detection network’s weights are initialized with a new RPN, which is fine-tuned. This process can repeat for several iterations.
Approximate Joint Training
Approximate joint training streamlines the process even further by training both networks simultaneously. It treats RPN proposals as fixed to avoid the complexity of backpropagating through the proposal generation step. While not truly end-to-end, this method still inherits the benefits of being end-to-end with a clean and unified framework during testing.
Non-Approximate Joint Training
This approach aims at true end-to-end training; gradients have to pass through the entire network, including the proposal generation step. This step is more theoretically correct, but more computationally expensive and tricky to implement effectively.
Community Projects of Faster R-CNN
The impact of Faster R-CNN goes beyond academic research. The Faster R-CNN model has been embraced by the computer vision community, resulting in many implementations and applications. Well-developed open-source programming languages such as Tensorflow and Pytorch provide implementations of Faster R-CNN making it available for developers and researchers all over the world.
Currently, Faster R-CNN can be implemented in numerous domains in the following aspects. Autonomous driving assists the vehicle to identify objects on the road. The technology is utilized in medical imaging to help diagnose diseases based on identifying abnormalities in X-rays and MRIs.
Some common uses include the management of stocks in retail companies and self-checkout systems. These applications demonstrate the ability and efficiency of the algorithm in different scenarios. Here is one of the example community projects.
Faster R-CNN for Pedestrian Detection from Drone Images
Pedestrian detection from drone images is important in search and rescue, surveillance, and infrastructure monitoring. It poses challenges because of variations in position and the direction of shots, distances, lighting, weather, and background complexity. Recent deep learning models, particularly Faster R-CNN, exhibit great success in object detection tasks.
Based on this community project, drone images can detect pedestrians with the help of Faster R-CNN. The Faster R-CNN integrates a backbone network for feature map extraction, an RPN for the generation of each region proposal, and a detection network for refining proposals and classifying objects.
The model trains on a dataset of 1500 images. The images are taken by an S30W drone under various conditions, including different locations, viewpoints, and both daytime and nighttime settings.
Experimental Results
These are the model performance outputs:
- Precision: 98%
- Recall: 99%
- F1 Measure: 98%
These results suggest that Faster R-CNN is effective in recognizing pedestrians from drone images with high levels of accuracy and resilience.
The findings of this study indicate that Faster R-CNN is promising for pedestrian detection in various settings and may, therefore, be valuable in practical applications. Future work could improve the reliability of the results under different conditions or investigate online tracking on drones.

Challenges of Faster R-CNN
Nevertheless, Faster R-CNN has some issues. The model can have difficulties with small objects or those with unusual aspect ratios. It also has difficulty with heavily occluded objects or those in cluttered scenes. The computational requirements, while improved from previous models, can become an issue for real-time processing for resource-constrained devices.
Improvements and Advanced Variants of Faster R-CNN
There are still some limitations in Faster R-CNN and researchers develop a lot of variations from its basis. Let us consider some significant enhancements and variants.
Feature Pyramid Network (FPN)
FPN improves the Faster R-CNN network in detecting objects at different scales. It generates the pyramid of the feature map, which enables the model to identify small objects from detailed features and large objects from the abstract features. This multi-scale technique helps in increasing the detection accuracy, especially for small objects.
It improves Faster R-CNN by:
- Creating a top-down pathway that combines high-level semantic features with low-level fine-grained features.
- Enabling the network to detect objects across a wide range of scales more effectively.
- Improving performance on small object detection
- Maintaining computational efficiency despite the added complexity.
Mask R-CNN
Mask R-CNN, an extension of Faster R-CNN, is capable of instance segmentation in addition to object detection. It incorporates a branch for segmenting the masks on all the predicted ROIs. This extension enables Mask R-CNN not only for detection but also to detect the boundaries of specific objects as well.
Key improvements include:
- Adding a branch for predicting segmentation masks on each Region of Interest (RoI).
- Introducing RoIAlign, which replaces RoIPool to preserve spatial information more accurately.
- Improving overall detection accuracy due to the multi-task training (detection and segmentation).
- Enabling pixel-level segmentation, providing more detailed object information.
Cascade R-CNN
Cascade R-CNN addresses the problem of the inconsistency of the IoU threshold for training and inference of the object detection system. It uses a sequence of detectors with increasing IoU thresholds. It helps refine predictions at each stage. This cascade of classifiers enhances localization accuracy, especially concerning high-quality detections.
Its improvements include:
- Implementing a cascade of detectors trained with increasing IoU thresholds.
- Gradually refining detection results through multiple stages.
- Significantly improving detection accuracy, especially for high-quality (high IoU) detection.
- Enhancing performance on challenging datasets with strict evaluation metrics.
All these architectures have improved the state of the art in object detection and instance segmentation, building upon the solid foundation developed by Faster R-CNN. They address different limitations of the original model, from multi-scale detection to pixel-level segmentation and high-quality object localization.
What’s Next?
The field of object detection continues to evolve, with researchers exploring new architectures, loss functions, and training strategies. Future developments may likely focus on improving real-time detection capabilities, handling diverse object categories, and integrating with multimodal data.
If you enjoyed reading this article, we have some other recommendations for you too:
- Understand the Differences and Similarities Between ANN and CNN
- Learn How Transfer Learning Can Save Training Time and Resources
- Discover the Advancements of YOLOv6 – A Single-Stage Object Detection
- Learn DeepLab – An Advanced Visual Processing Technique