
Mask R-CNN is a Convolutional Neural Network (CNN) and a state-of-the-art model that performs object detection and instance segmentation. This Deep Neural Network variant detects objects in an image and generates high-quality segmentation masks for each instance.

To understand the differences between Mask RCNN, and Faster RCNN vs. RCNN, we introduce the concept of CNNs.
What is a Convolutional Neural Network (CNN)?
A Convolutional Neural Network (CNN) is a type of artificial neural network for image recognition for processing pixel data. Therefore, Convolutional Neural Networks are the fundamental building blocks for the computer vision task of image segmentation (CNN segmentation).
The Convolutional Neural Network Architecture consists of three main layers:
- Convolutional layer: abstracts the input image as a feature map via the use of filters and kernels.
- ROI Pooling layer: downsamples feature maps by summarizing the presence of features in patches of the feature map.
- Fully connected layer: Fully connected layers connect every neuron in one layer to every neuron in another layer.
Combining the layers of a CNN teaches the designed neural network to identify an image’s object of interest. Simple CNNs are useful for image classification and object detection with a single object in the image.
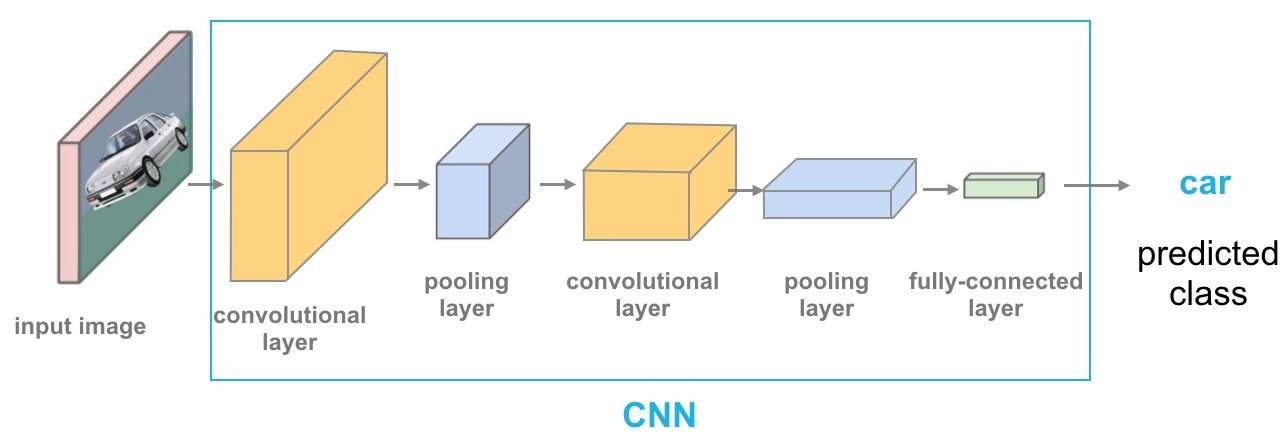
In a more complex situation with multiple objects in an image, a simple CNN architecture isn’t optimal. For this, Mask R-CNN is a state-of-the-art architecture and an extension of R-CNN (also referred to as RCNN).
What is R-CNN?
R-CNN, or RCNN, stands for Region-Based Convolutional Neural Network. It is a type of machine learning model for computer vision tasks, specifically for object detection.
To understand what RCNN is, we will look next into the RCNN architecture.
How does R-CNN Work?
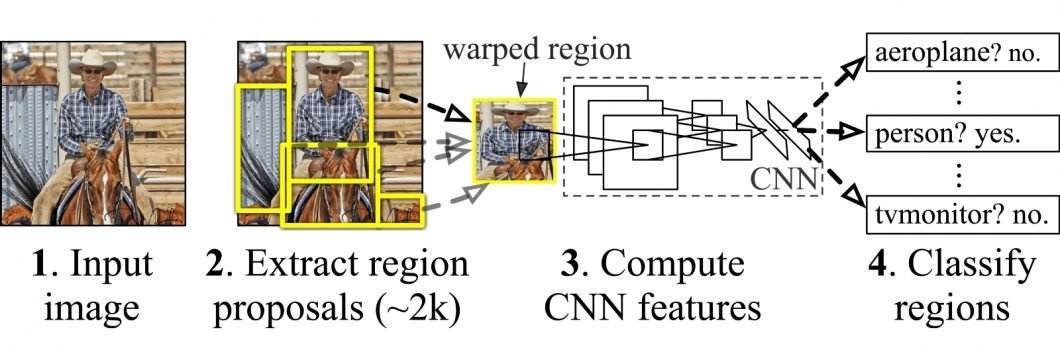
The following image depicts the concept of region-based CNN (R-CNN). This approach utilizes bounding boxes across the object regions. It then evaluates CNNs independently on all Regions of Interest (ROI) to classify image regions into the proposed class.
The RCNN architecture solves image detection tasks. Its architecture forms the basis of Mask R-CNN, with researchers later developing improvements to create Faster R-CNN.
What is Faster R-CNN?
Fast R-CNN is an improved version of R-CNN architectures with two stages:
- Region Proposal Network (RPN) is a Neural Network proposing multiple objects available within a particular image.
- Fast R-CNN extracts features using RoIPool from each candidate box and performs classification and bounding-box regression. RoIPool is an operation for extracting a small feature map from each RoI in detection, considering various aspect ratios.
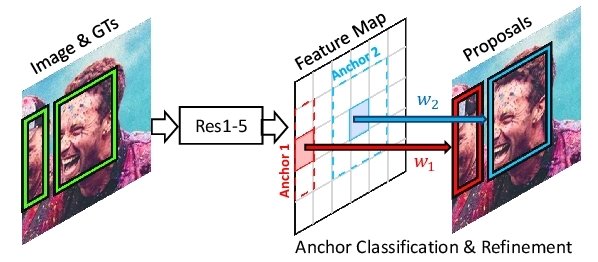
Faster R-CNN advances this stream by learning the attention mechanism with an RPN and Fast R-CNN architecture. “Fast R-CNN” is faster because you need to feed 2’000 region proposals to CNN every time. Instead, the system performs the convolution operation only once per image, generating a feature map from it.
Furthermore, Faster R-CNN models are an optimized form of R-CNN built to enhance computation speed.

The main difference between Fast and Faster RCNN is that Fast R-CNN uses selective search. This is for generating Regions of Interest, while Faster R-CNN uses a “Region Proposal Network” (RPN). Let’s move on to see how Faster R-CNN helped build Mask-R-CNN.
What is Mask R-CNN?
Mask R-CNN is a state-of-the-art CNN in terms of image segmentation and instance segmentation. Researchers developed Mask R-CNN on top of Faster R-CNN, a Region-Based Convolutional Neural Network.
The first step to understanding how Mask R-CNN works requires an understanding of the concept of Image Segmentation.
Image Segmentation is the computer vision task that partitions a digital image into multiple segments. This segmentation locates objects and boundaries (lines, curves, etc.).
Two main types of image segmentation fall under Mask R-CNN:
Semantic Segmentation
Semantic segmentation classifies each pixel into a fixed set of categories without differentiating object instances. It deals with the identification/classification of similar objects as a single class from the pixel level.
As shown in the image above, the system classified all objects as a single entity (person). We also refer to this as background segmentation, because it separates the subjects of the image from the background.
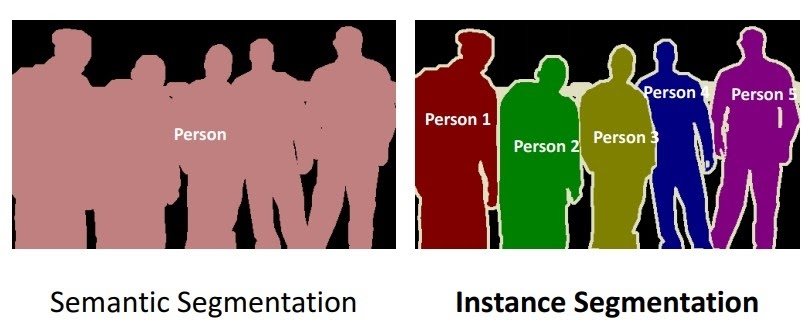
Instance Segmentation
Instance Segmentation deals with the correct detection of all objects in an image while also precisely segmenting each instance. It is, therefore, the combination of object detection, object localization, and object classification. In other words, this type of segmentation gives a clear distinction between each object classified as a similar instance.
In the example image above, all objects are persons but separated as a single entity. Semantic segmentation, or foreground segmentation, accentuates the subjects of the image instead of the background.
How does Mask R-CNN work?
Researchers built Mask R-CNN using Faster R-CNN. Faster R-CNN has 2 outputs for each candidate object, a class label, and a bounding-box offset.
However, Mask R-CNN has the addition of a third branch that outputs the object mask. The additional mask output is distinct from the class and box outputs. Thus, requiring the extraction of a much finer spatial layout of an object.
Mask R-CNN is an extension of Faster R-CNN. It adds a branch for predicting an object mask (RoI) in parallel with the existing branch for bounding box recognition.
Advantages of Mask R-CNN
- Simplicity: Mask R-CNN is simple to train.
- Performance: Mask R-CNN outperforms all existing, single-model entries on every task.
- Efficiency: The method is very efficient and adds only a small overhead to Faster R-CNN.
- Flexibility: Mask R-CNN is easy to generalize to other tasks. For example, it is possible to use Mask R-CNN for human pose estimation in the same framework.
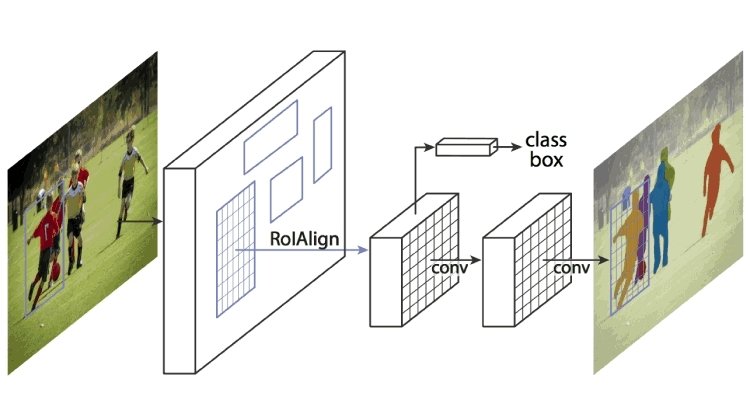
The key element of Mask R-CNN is the pixel-to-pixel alignment, which is the main missing piece of Fast/Faster R-CNN. It adopts the same two-stage procedure with an identical first stage (which is RPN). In the second stage, in parallel to predicting the class and box offset, it also outputs a binary mask for each RoI. This is in contrast to most recent systems, where classification depends on mask predictions.
Furthermore, it is simple to implement and train given the Faster R-CNN framework. This facilitates a wide range of flexible architectural designs. Additionally, the mask branch only adds a small computational overhead, enabling a fast system and rapid experimentation.
Community Projects using Mask R-CNN
R-CNN improved OpenStreetMap by adding baseball, soccer, tennis, football, and basketball fields.
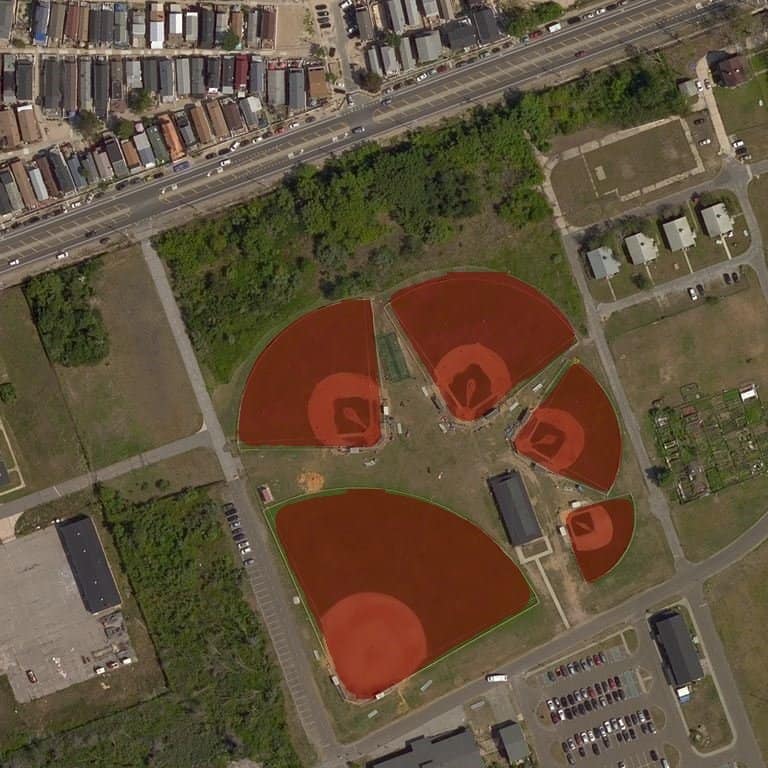
The project applied the Mask R-CNN algorithm to detect features to identify sports fields in satellite images. Sports fields are a good fit for the Mask R-CNN algorithm. They are visible for detection in satellite images regardless of the tree cover (unlike buildings). Also, the method is efficient because sports fields are “blob” shape and not a line shape (unlike streets).
In a similar application, satellite imagery helps create maps for use by humanitarian organizations.
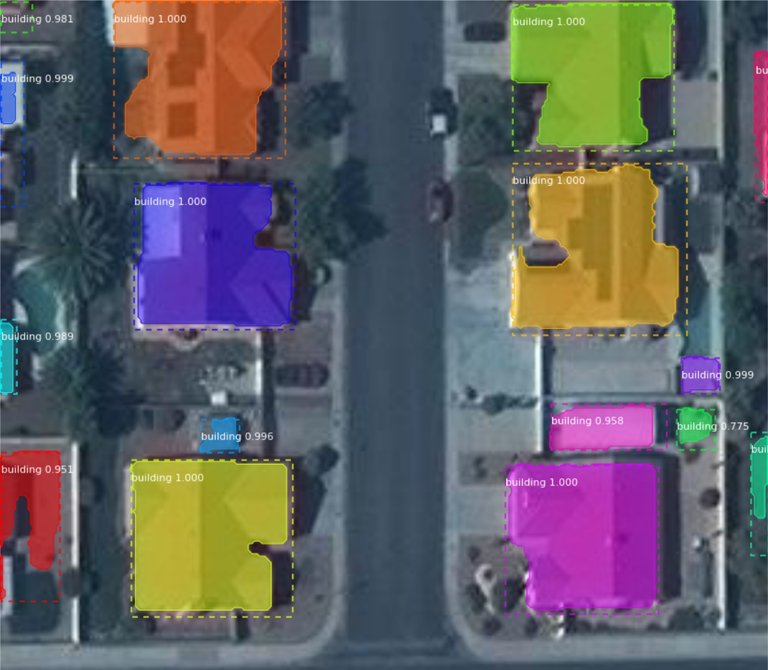
Visit this article about image segmentation to explore Mask R-CNN use cases and applications, and similar algorithms. Popular applications include autonomous vehicles and medical applications, such as tumor detection or even detecting features related to the coronavirus.
Implementing Computer Vision with Mask R-CNN
If you enjoyed reading this article, I recommend:
- View an extensive list of Computer Vision applications
- Applications of Computer Vision in Sports
- Read about Object Detection Algorithms
- Learn about the popular YOLO real-time object detector