
Autoencoders are a powerful tool used in machine learning for feature extraction, data compression, and image reconstruction. These neural networks have made significant contributions to computer vision, natural language processing, and anomaly detection, among other fields. An autoencoder model can automatically learn complex features from input data. This has made them a popular method for improving the accuracy of classification and prediction tasks.
In this article, we will explore the fundamentals of autoencoders and their diverse applications in the field of machine learning.
- The basics of autoencoders, including the types and architectures.
- How autoencoders are used with real-world examples
- We will explore the different applications of autoencoders in computer vision.
What is an Autoencoder?
Explanation and Definition of Autoencoders
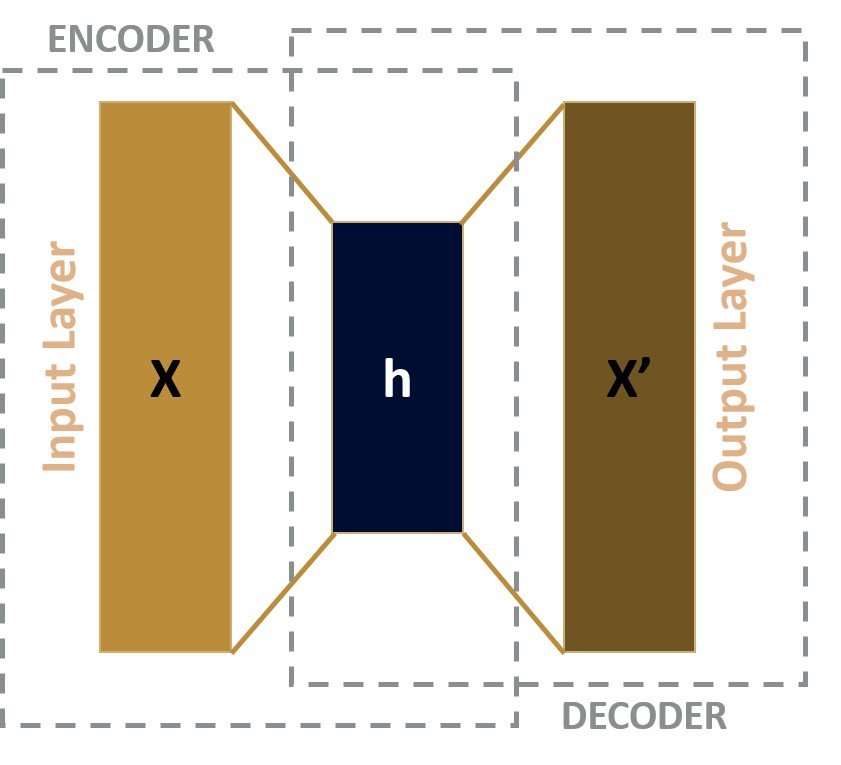
Autoencoders are neural networks that can learn to compress and reconstruct input data, such as images, using a hidden layer of neurons. An autoencoder model consists of two parts: an encoder and a decoder.
The encoder takes the input data and compresses it into a lower-dimensional representation called the latent space. The decoder then reconstructs the input data from the latent space representation. In an optimal scenario, the autoencoder performs as close to perfect reconstruction as possible.
Loss Function and Reconstruction Loss
Loss functions play a critical role in training autoencoders and determining their performance. The most commonly used loss function for autoencoders is the reconstruction loss. It is used to measure the difference between the model input and output.
The reconstruction error is calculated using various loss functions, such as mean squared error, binary cross-entropy, or categorical cross-entropy. The applied method depends on the type of data being reconstructed.
The reconstruction loss is then used to update the weights of the network during backpropagation to minimize the difference between the input and the output. The goal is to achieve a low reconstruction loss. A low loss indicates that the model can effectively capture the salient features of the input data and reconstruct it accurately.
Dimensionality Reduction
Dimensionality reduction is the process of reducing the number of dimensions in the encoded representation of the input data. Autoencoders can learn to perform dimensionality reduction by training the encoder network to map the input data to a lower-dimensional latent space. Then, the decoder network is trained to reconstruct the original input data from the latent space representation.
The size of the latent space is typically much smaller than the size of the input data, allowing for efficient storage and computation of the data. Through dimensionality reduction, autoencoders can also help to remove noise and irrelevant features. This is useful for improving the performance of downstream tasks such as data classification or clustering.
Most Popular Autoencoder Models
There are several types of autoencoder models, each with its unique approach to learning these compressed representations:
- Autoencoding models: These are the simplest type of autoencoder model. They learn to encode input data into a lower-dimensional representation. Then, they decode this representation back into the original input.
- Contractive autoencoder: This type of autoencoder model is designed to learn a compressed representation of the input data while being resistant to small perturbations in the input. This is achieved by adding a regularization term to the training objective. This term penalizes the network for changing the output in response to small changes in the input.
- Convolutional autoencoder (CAE): A Convolutional Autoencoder (CAE) is a type of neural network that uses convolutional layers for encoding and decoding of images. This autoencoder type aims to learn a compressed representation of an image by minimizing the reconstruction error between the input and output of the network. Such models are commonly used for image generation tasks, image denoising, compression, and image reconstruction.
- Sparse autoencoder: A sparse autoencoder is similar to a regular autoencoder, but with an added constraint on the encoding process. In a sparse autoencoder, the encoder network is trained to produce sparse encoding vectors, which have many zero values. This forces the network to identify only the most important features of the input data.
- Denoising autoencoder: This type of autoencoder is designed to learn to reconstruct an input from a corrupted version of the input. The corrupted input is created by adding noise to the original input, and the network is trained to remove the noise and reconstruct the original input. For example, BART is a popular denoising autoencoder for pretraining sequence-to-sequence models. The model was trained by corrupting text with an arbitrary noise function and learning a model to reconstruct the original text. It is very effective for natural language generation, text translation, text generation, and comprehension tasks.
- Variational autoencoders (VAE): Variational autoencoders are a type of generative model that learns a probabilistic representation of the input data. A VAE model is trained to learn a mapping from the input data to a probability distribution in a lower-dimensional latent space, and then to generate new samples from this distribution. VAEs are commonly used in image and text generation tasks.
- Video Autoencoder: Video Autoencoder has been introduced for learning representations in a self-supervised manner. For example, a model was developed that can learn representations of 3D structure and camera pose in a sequence of video frames as input (see Pose Estimation). Hence, Video Autoencoder can be trained directly using a pixel reconstruction loss, without any ground truth 3D or camera pose annotations. This autoencoder type can be used for camera pose estimation and video generation by motion following.
- Masked Autoencoders (MAE): A masked autoencoder is a simple autoencoding approach that reconstructs the original signal given its partial observation. A MAE variant includes masked autoencoders for point cloud self-supervised learning, named Point-MAE. This approach has shown great effectiveness and high generalization capability on various tasks, including object classification, few-shot learning, and part-segmentation. Specifically, Point-MAE outperforms all the other self-supervised learning methods.
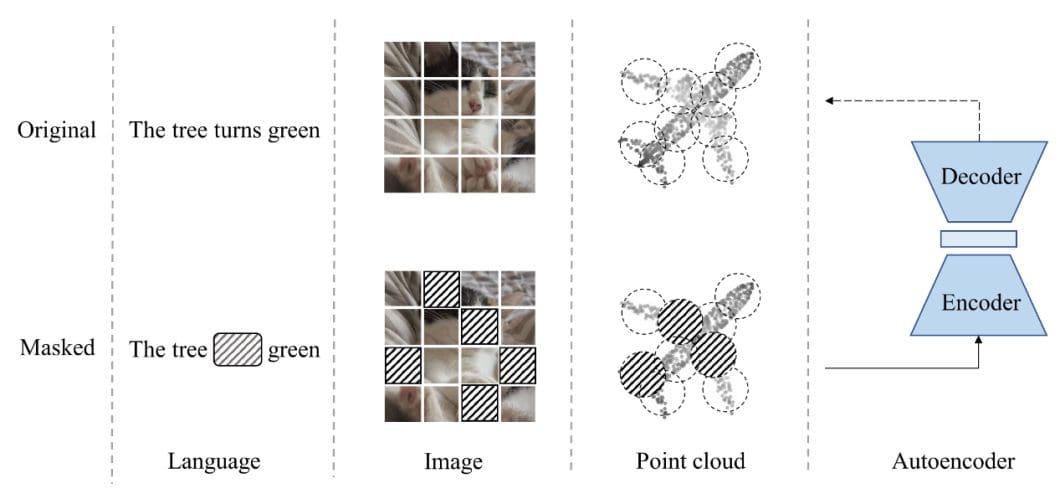
How Autoencoders Work in Computer Vision
Autoencoder models are commonly used for image processing tasks in computer vision. In this use case, the input is an image and the output is a reconstructed image. The model learns to encode the image into a compressed representation. Then, the model decodes this representation to generate a new image that is as close as possible to the original input.
Input and output are two important components of an autoencoder model. The input to an autoencoder is the data that we want to encode and decode. And the output is the reconstructed data that the model produces after encoding and decoding the input.
The main objective of an autoencoder is to reconstruct the input as accurately as possible. This is achieved by feeding the input data through a series of layers (including hidden layers) that encode and decode the input. The model then compares the reconstructed output to the original input and adjusts its parameters to minimize the difference between them.
In addition to reconstructing the input, autoencoder models also learn a compressed representation of the input data. This compressed representation is created by the bottleneck layer of the model, which has fewer neurons than the input and output layers. By learning this compressed representation, the model can capture the most important features of the input data in a lower-dimensional space.
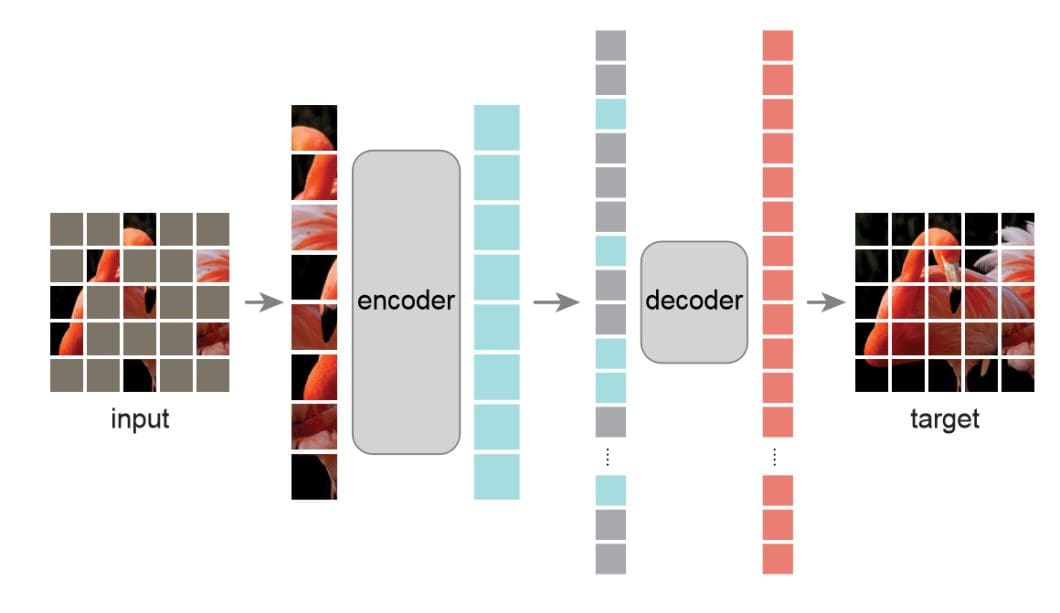
Step-by-step process of autoencoders
Autoencoders extract features from images in a step-by-step process as follows:
- Input Image: The autoencoder takes an image as input, which is typically represented as a matrix of pixel values. The input image can be of any size, but it is typically normalized to improve the performance of the autoencoder.
- Encoding: The autoencoder compresses the input image into a lower-dimensional representation, known as the latent space, using the encoder. The encoder is a series of convolutional layers that extract different levels of features from the input image. Each layer applies a set of filters to the input image and outputs a feature map that highlights specific patterns and structures in the image.
- Latent Representation: The output of the encoder is a compressed representation of the input image in the latent space. This latent representation captures the most important features of the input image and is typically a smaller dimensional representation of the input image.
- Decoding: The autoencoder reconstructs the input image from the latent representation using the decoder. The decoder is a set of multiple deconvolutional layers that gradually increase the size of the feature maps until the final output is the same size as the input image. Every layer applies a set of filters that up-sample the feature maps, resulting in a reconstructed image.
- Output Image: The output of the decoder is a reconstructed image that is similar to the input image. However, the reconstructed image may not be identical to the input image since the autoencoder has learned to capture the most important features of the input image in the latent representation.
By compressing and reconstructing input images, autoencoders extract the most important features of the images in the latent space. These features can then be used for tasks such as image classification, object detection, and image retrieval.
Limitations and Benefits of Autoencoders for Computer Vision
Traditional feature extraction methods involve the need to manually design feature descriptors that capture important patterns and structures in images. These feature descriptors are then used to train machine learning models for tasks such as image classification and object detection.
However, designing feature descriptors manually can be a time-consuming and error-prone process that may not capture all the important features in an image.
Advantages of Autoencoders
Advantages of Autoencoders over traditional feature extraction methods include:
- First, autoencoders learn features automatically from the input data, making them more effective in capturing complex patterns and structures in images (pattern recognition). This is particularly useful when dealing with large and complex datasets where manually designing feature descriptors may not be practical or even possible.
- Second, autoencoders are suitable for learning more robust features that generalize better to new data. Other feature extraction methods often rely on handcrafted features that may not generalize well to new data. Autoencoders, on the other hand, learn features that are optimized for the specific dataset, resulting in more robust features that can generalize well to new data.
- Finally, autoencoders are able to learn more complex and abstract features that may not be possible with traditional feature extraction methods. For example, autoencoders can learn features that capture the overall structure of an image, such as the presence of certain objects or the overall layout of the scene. These types of features may be difficult to capture using traditional feature extraction methods, which typically rely on low-level features such as edges and textures.
Disadvantages of Autoencoders
Disadvantages of autoencoders include the following limitations:
- One major limitation is that autoencoders can be computationally expensive (see the cost of computer vision), particularly when dealing with large datasets and complex models.
- Additionally, autoencoders may be prone to overfitting, where the model learns to capture noise or other artifacts in the training data that do not generalize well to new data.
Real-world Applications of Autoencoders
The following list shows tasks solved with an autoencoder in the current research literature:
| Task | Description | Papers | Share |
|---|---|---|---|
| Anomaly Detection | Identifying data points that deviate from the norm | 39 | 6.24% |
| Image Denoising | Removing noise from corrupted data | 27 | 4.32% |
| Time Series | Analyzing and predicting sequential data | 21 | 3.36% |
| Self-Supervised Learning | Learning representations from unlabeled data | 21 | 3.36% |
| Semantic Segmentation | Segmenting an image into meaningful parts | 16 | 2.56% |
| Disentanglement | Separating underlying factors of variation | 14 | 2.24% |
| Image Generation | Generating new images from learned distributions | 14 | 2.24% |
| Unsupervised Anomaly Detection | Identifying anomalies without labeled data | 12 | 1.92% |
| Image Classification | Assigning an input image to a predefined category | 10 | 1.60% |

Autoencoder Computer Vision Applications
Autoencoders have been used in various computer vision applications, including image denoising, image compression, image retrieval, and image generation. For example, in medical imaging, autoencoders have been used to improve the quality of MRI images by removing noise and artifacts.
Other problems that can be solved with autoencoders include facial recognition, anomaly detection, and feature detection. Visual anomaly detection is important in many applications, such as AI diagnosis assistance in healthcare and quality assurance in industrial manufacturing applications.
In computer vision, autoencoders are also widely used for unsupervised feature learning, which can help improve the accuracy of supervised learning models. For more, read our article about supervised vs. unsupervised learning.

Image generation with Autoencoders
Variational autoencoders, in particular, have been used for image generation tasks, such as generating realistic images of faces or landscapes. By sampling from the latent space, variational autoencoders can produce an infinite number of new images that are similar to the training data.
For example, the popular generative machine learning model DALL-E uses a variational autoencoder for AI image generation. It consists of two elements, an autoencoder and a transformer. The discrete autoencoder learns to accurately represent images in a compressed latent space, and the transformer learns the correlations between languages and the discrete image representation.

Future and Outlook
Autoencoders have tremendous potential in computer vision, and ongoing research is exploring ways to overcome their limitations. For example, new regularization techniques, such as dropout and batch normalization, can help prevent overfitting.
Additionally, advancements in AI hardware, such as the development of specialized hardware for neural networks, can help improve the scalability of autoencoder models.
In Computer Vision Research, teams are constantly developing new methods to reduce overfitting, improve efficiency, increase interpretability, improve data augmentation, and expand autoencoders’ capabilities to more complex tasks.
A Recap of Autoencoder
In conclusion, autoencoders are versatile and powerful tools in machine learning, with diverse applications in computer vision. They can automatically learn complex features from input data and extract useful information through dimensionality reduction.
While autoencoders have limitations such as computational expense and potential overfitting, they offer significant benefits over traditional feature extraction methods. Ongoing research is exploring ways to improve autoencoder models, including new regularization techniques and hardware advancements.
Autoencoders have tremendous potential for future development, and their capabilities in computer vision are only expected to expand.
Read about related topics and blog articles:
- Active learning can be applied to autoencoders in several ways to improve their performance
- ANN and CNN: Analyzing Differences and Similarities