
Compared to robotic systems, humans are excellent navigators of the physical world. Physical processes aside, this largely comes down to innate cognitive abilities still lacking in most robotics:
- The ability to localize landmarks at varying ontological levels, such as a “book” being “on a shelf” or “in the living room”
- Being able to quickly determine whether there is a navigable path between two points based on the environment layout
Early robotic navigation systems relied on basic line-following systems. These eventually evolved into navigation based on visual perception, provided by cameras or LiDAR, to construct geometric maps. Later on, Simultaneous Localization and Mapping (SLAM) systems were integrated to provide the ability to plan routes through environments.
About Multimodal Robot Navigation
More recent attempts to endow robotics with the same capabilities have centered around building geometric maps for path planning and parsing goals from natural language commands. However, this approach struggles when it comes to generalizing for new or previously unseen instructions. Not to mention environments that change dynamically or are ambiguous in some way.
Furthermore, learning methods directly optimize navigation policies based on end-to-end language commands. While this method is not inherently bad, it does require vast amounts of data to train models.
Current Artificial Intelligence (AI) and deep learning models are adept at matching object images to natural language descriptions by leveraging training on internet-scale data. However, this capability does not translate well to mapping the environments containing the said objects.
New research aims to integrate multimodal inputs to enhance robotic navigation in complex environments. Instead of basing route planning on one-dimensional visual input, these systems combine visual, audio, and language cues. This allows for creating a richer context and improving situational awareness.
Two key approaches
One potentially groundbreaking area of study in this field relates to so-called VLMaps (Visual Language Maps) and AVLMaps (Audio Visual Language Maps). The recent papers, “Visual Language Maps for Robot Navigation” and “Audio Visual Language Maps for Robot Navigation” by Chenguang Huang et al., explore the prospect of using these models for robotic navigation in great detail.
VLMaps directly fuses visual-language features from pre-trained models with 3D reconstructions of the physical environment. This enables precise spatial localization of navigation goals anchored in natural language commands. It can also localize landmarks and spatial references for landmarks.
The main advantage is that this allows for zero-shot spatial goal navigation without additional data collection or fine-tuning.
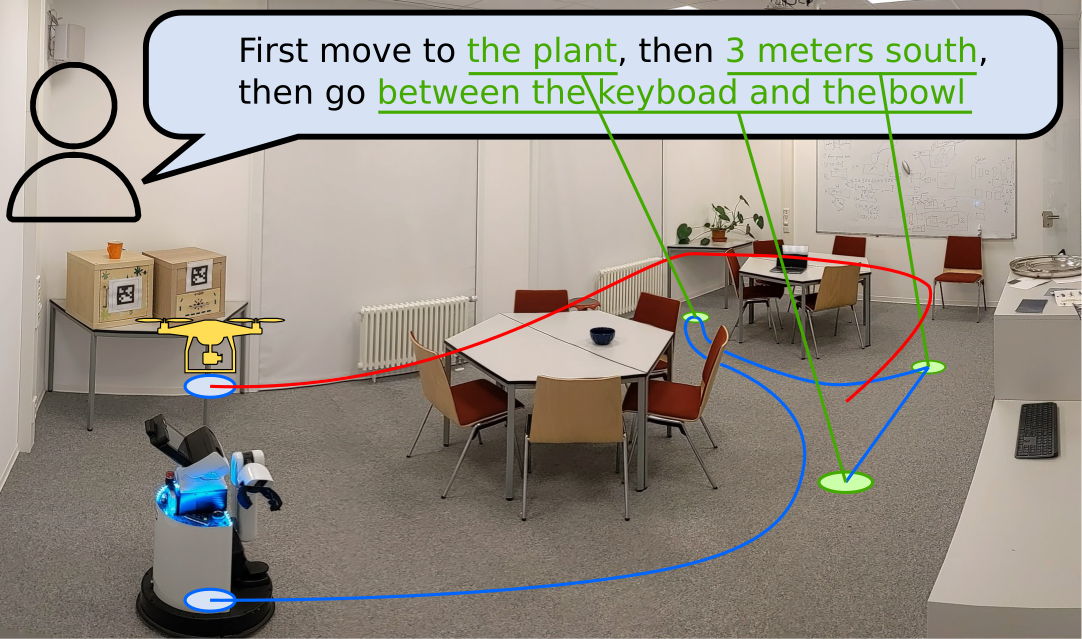
This approach allows for more accurate execution of complex navigational tasks and the sharing of these maps with different robotic systems.
AVLMaps are based on the same approach but also incorporate audio cues to construct a 3D voxel grid using pre-trained multimodal models. This makes zero-shot multimodal goal navigation possible by indexing landmarks using textual, image, and audio inputs. For example, this would allow a robot to carry out a navigation goal such as “go to the table where the beeping sound is coming from.”
Audio input can enrich the system’s world perception and help disambiguate goals in environments with multiple potential targets.
VLMaps
Related work in AI and computer vision has played a pivotal role in developing VLMaps. For instance, the maturation of SLAM techniques has greatly advanced the ability to translate semantic information into 3D maps. Traditional approaches either relied on densely annotated 3D volumetric maps with 2D semantic segmentation Convolutional Neural Networks (CNNs) or object-oriented methods to build 3D Maps.
While progress has been made in generalizing these models, it’s heavily constrained by operating on a predefined set of semantic classes. VLMaps overcomes this limitation by creating open-vocabulary semantic maps that allow natural language indexing.
Improvements in Vision and Language Navigation (VLN) have also led to the ability to learn end-to-end policies that follow route-based instructions on topological graphs of simulated environments. However, until now, their real-world applicability has been limited by a reliance on topological graphs and a lack of low-level planning capabilities. Another downside is the need for huge data sets for training.
For VLMaps, the researchers were influenced by pre-trained language and vision models, such as LM-Nav and CoW (CLIP on Wheels). The latter performs zero-shot language-based object navigation by leveraging CLIP-based saliency maps. While these models can navigate to objects, they struggle with spatial queries, such as “to the left of the chair” and “in between the TV and the sofa.”
VLMaps extend these capabilities by supporting open-vocabulary obstacle maps and complex spatial language indexing. This allows navigation systems to build queryable scene representations for LLM-based robot planning.

Key components
Several key components in the development of VLMaps allow for building a spatial map representation that localizes landmarks and spatial references based on natural language.
Building a VVLMap
VLMaps uses a video feed from robots combined with standard exploration algorithms to build a visual-language map. The process involves:
- Visual feature extraction: Using models like CLIP to extract visual-language features from image observations.
- 3D reconstruction: Combining these features with 3D spatial data to create a comprehensive map.
- Indexing: Enabling the map to support natural language queries, allowing for the indexing and localization of landmarks.
Mathematically, suppose VV represents the visual features and LL represents the language features. In that case, their fusion can be represented as M=f(V, L)M = f(V, L), where MM is the resulting visual-language map.
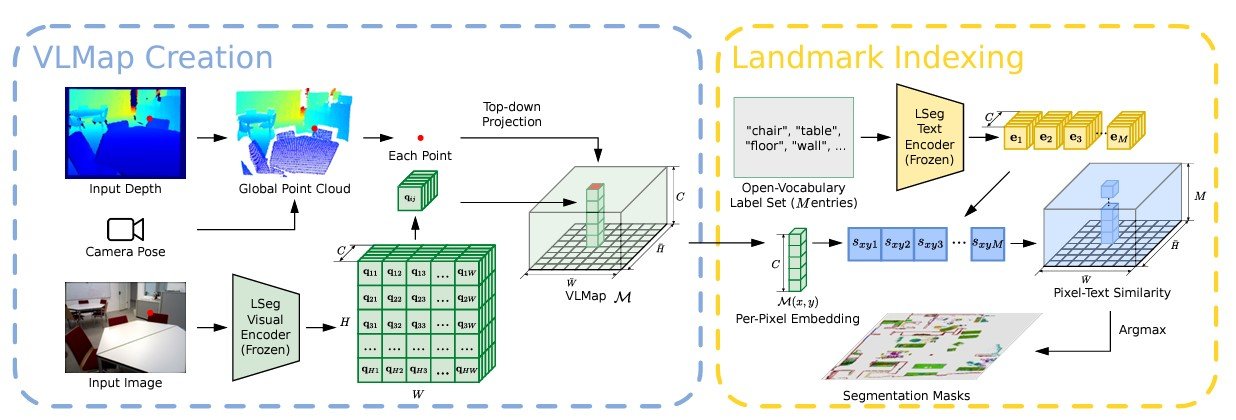
Localizing Open-Vocabulary Landmarks
To localize landmarks in VLMaps using natural language, an input language list is defined with representations for each category in text form. Examples include [“chair”, “sofa”, “table”] or [“furniture”, “floor”]. This list is converted into vector embeddings using the pre-trained CLIP text encoder.
The map embeddings are then flattened into matrix form. The pixel-to-category similarity matrix is computed, with each element indicating the similarity value. Applying the argmax operator and reshaping the result gives the final segmentation map, which identifies the most related language-based category for each pixel.
Generating Open-Vocabulary Obstacle Maps
Using a Large Language Model (LLM), VLMap interprets commands and breaks them into subgoals, allowing for specific directives like “in between the sofa and the TV” or “three meters east of the chair.”
The LLM generates executable Python code for robots, translating high-level instructions into parameterized navigation tasks. For example, commands such as “move to the left side of the counter” or “move between the sink and the oven” are converted into precise navigation actions using predefined functions.

AVLMaps
AVLMaps largely builds on the same approach used in developing VLMaps, but is extended with multimodal capabilities to process auditory input as well. In AVLMaps, objects can be directly localized from natural language instructions using both visual and audio cues.
For testing, the robot was also provided with an RGB-D video stream and odometry information, but this time with an audio track included.
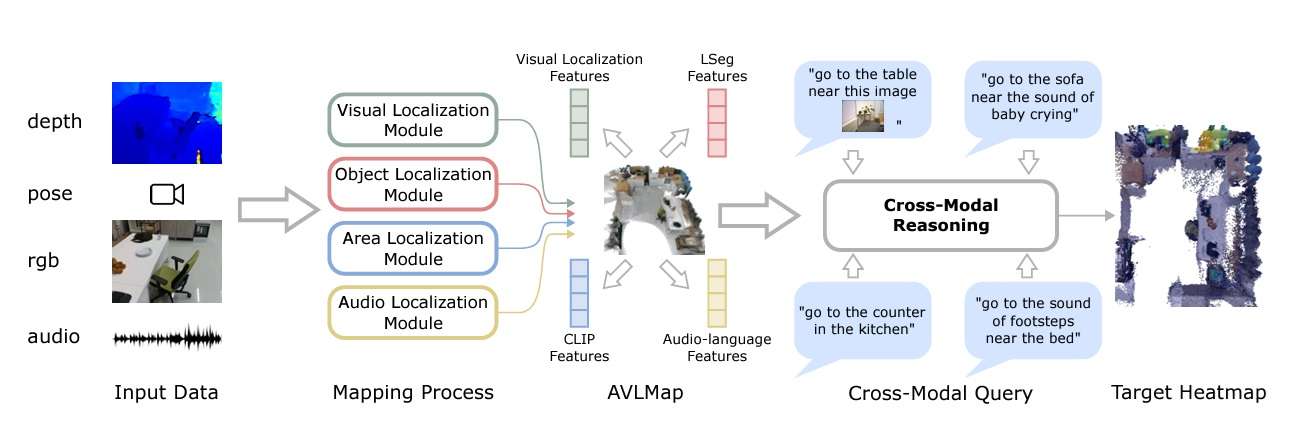
Module types
In AVLMaps, the system uses four modules to build a multimodal features database. They are:
- Visual localization module: Localizes a query image in the map using a hierarchical scheme, computing both local and global descriptors in the RGB stream.
- Object localization module: Uses open-vocabulary segmentation (OpenSeg) to generate pixel-level features from the RGB image, associating them with back-projected depth pixels in 3D reconstruction. It computes cosine similarity scores for all point and language features, selecting top-scoring points in the map for indexing.
- Area localization module: The paper proposes a sparse topological CLIP features map to identify coarse visual concepts, like “kitchen area.” Also, using cosine similarity scores, the model calculates confidence scores for predicting locations.
- Audio localization module: Partitions an audio clip from the stream into segments using silence detection. Then, it computes audio-lingual features for each using AudioCLIP to come up with matching scores for predicting locations based on odometry information.
The key differentiator of AVLMaps is its ability to disambiguate goals by cross-referencing visual and audio features. In the paper, this is achieved by creating heatmaps with probabilities for each voxel position based on the distance to the target. The model multiplies the results from heatmaps for different modalities to predict the target with the highest probabilities.
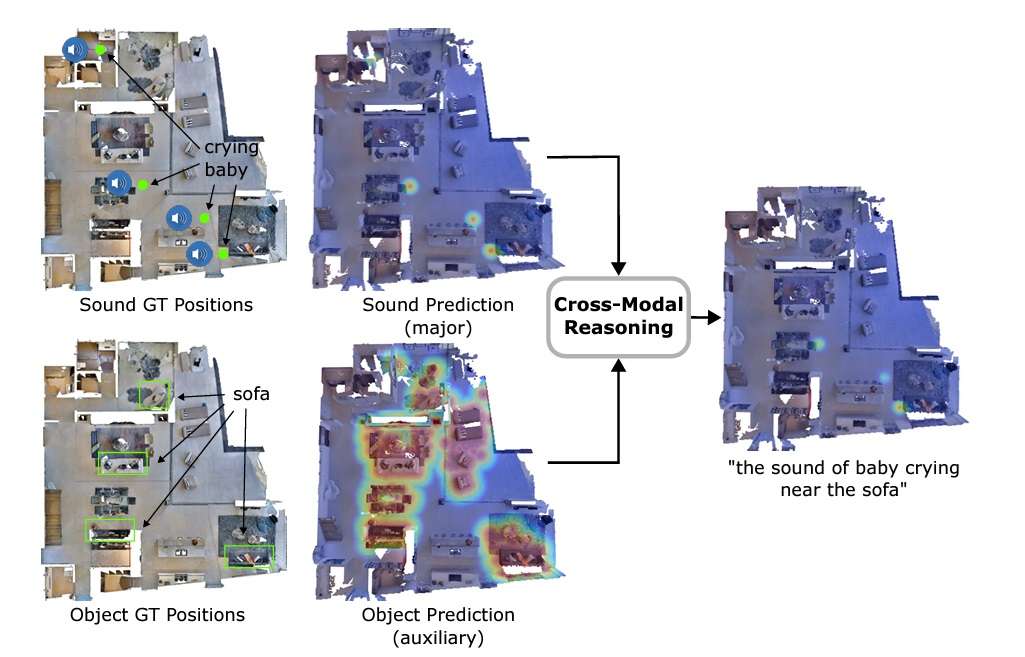
Other methods
Experimental results show the promise of utilizing techniques like VLMaps for robotic navigation. Looking at the object, various models were generated for the object type “chair.” For example, VLMaps is more discerning in its predictions.

In multi-object navigation, VLMaps significantly outperformed conventional models. This is largely because VLMaps don’t suffer from generating as many false positives as the other methods.
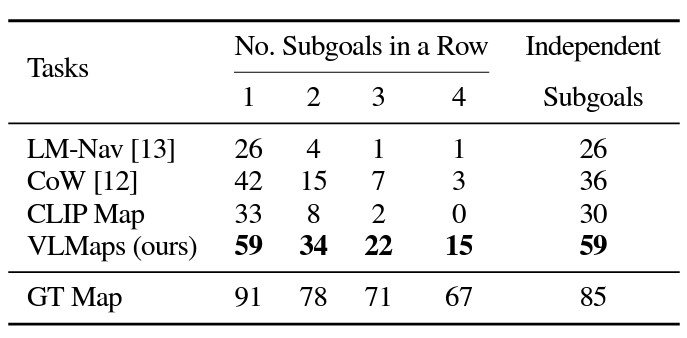
VLMaps also achieves much higher zero-shot spatial goal navigation success rates than the other open-vocabulary zero-shot navigation baseline alternatives.
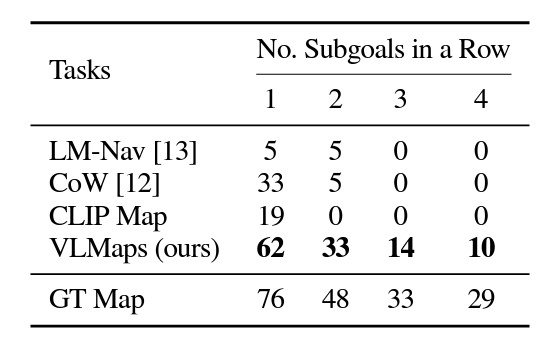
Another area where VLMaps shows promising results is in cross-embodiment navigation to optimize route planning. In this case, VLMaps generated different obstacle maps for robot embodiments, a ground-based LoCoBot, and a flying drone. When provided with a drone map, the drone significantly improved its performance by creating navigation maps to fly over obstacles. This shows VLMap’s efficiency at both 2D and 3D spatial navigation.

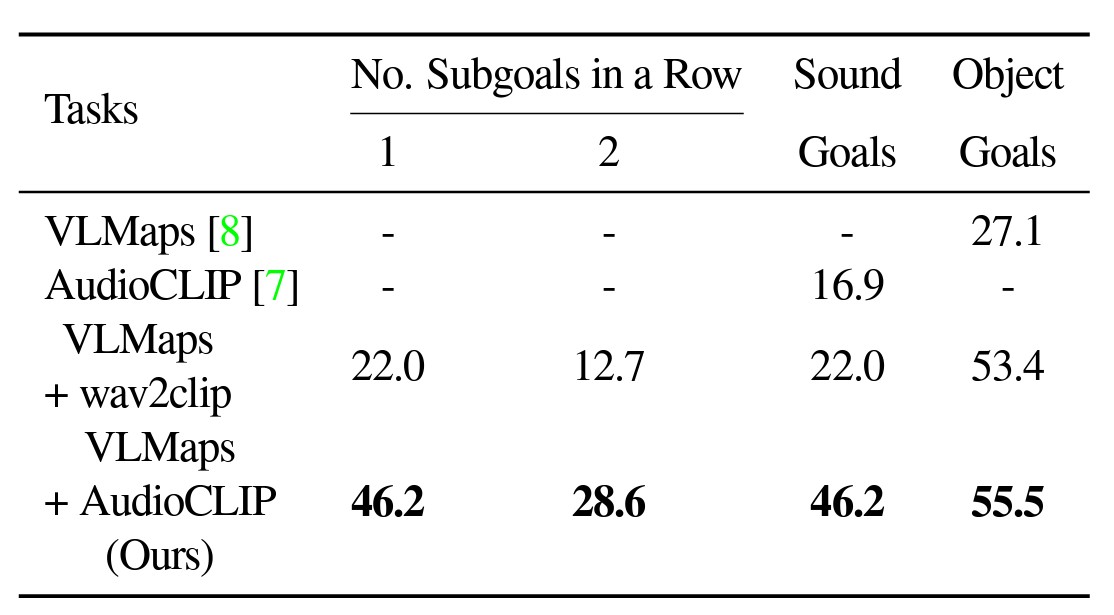
Similarly, during testing, AVLMaps outperformed VLMaps with both standard AudioCLIP and wav2clip in solving ambiguous goal navigation tasks. For the experiment, robots were made to navigate to one sound goal and one object goal in a sequence.
What’s next for robotic navigation?
While models like VLMaps and AVLMaps show potential, there is still a long way to go. To mimic the navigational capabilities of humans and be useful in more real-life situations, we need systems with even higher success rates in carrying out complex, multi-goal navigational tasks.
Furthermore, these experiments used basic, drone-like robotics. We have yet to see how these advanced navigational models can be combined with more human-like systems.
Another active area of research is Event-based SLAM. Instead of relying purely on sensory information, these systems can use events to disambiguate goals or open up new navigational opportunities. Instead of using single frames, these systems capture changes in lighting and other characteristics to identify environmental events.
As these methods evolve, we can expect increased adoption in fields like autonomous vehicles, nanorobotics, agriculture, and even robotic surgery.
To learn more about the world of AI and computer vision, check out the viso.ai blog:
- GoogLeNet Explained: The Inception Model that Won ImageNet
- Object Tracking: Technical Guide and Use Cases
- ImageNet Dataset: Evolution & Applications
- Facial Recognition: An Easy-to-Understand Overview