We’ve built a powerful platform for businesses to develop computer vision solutions with minimal integration work. Companies worldwide use it to bring all their computer vision initiatives on one platform that scales. Thus, to develop, deploy, and monitor computer vision systems end-to-end.
We’ve built a powerful platform for businesses to develop computer vision solutions with minimal integration work. Companies worldwide use it to bring all their computer vision initiatives on one platform that scales. Thus, to develop, deploy, and monitor computer vision systems end-to-end.
The traditional machine learning (ML) paradigm involves training models on extensive labeled datasets. This is done to extract patterns and test these models on unseen samples to evaluate performance.
However, the method requires a sufficient volume of labeled training data. This prevents you from applying artificial intelligence (AI) in several real-world industrial use cases, such as healthcare, retail, and manufacturing, where data is scarce.
But that’s where the N-shot learning paradigms come into play.
In this article, we will discuss
Types of N-shot learning paradigms
Different frameworks and approaches
Applications
Challenges and Future Research
Book a Demo
To get started with enterprise-grade computer vision, book a demo with our team of experts.
Unlike supervised learning, N-shot learning works to overcome the challenge of training deep learning and computer vision models with limited labeled data.
The techniques make AI model development scalable and computationally inexpensive, as you can build large models with several parameters to capture general data patterns from a few samples.
Also, you can use N-shot learning models to label data samples with unknown classes and feed the new dataset to supervised learning algorithms for better training.
The AI community categorizes N-shot approaches into few-shot, one-shot, and zero-shot learning. Let’s discuss each in more detail.
Few-Shot Learning
In few-shot learning (FSL), you define an N-way K-shot problem that aims to train a model on N classes with K samples. For example, a situation where you have two image classes, each with three examples, would be a 2-way 3-shot problem.
Similarly, a case where you have N classes and 2 examples per class would be a two-shot learning problem.
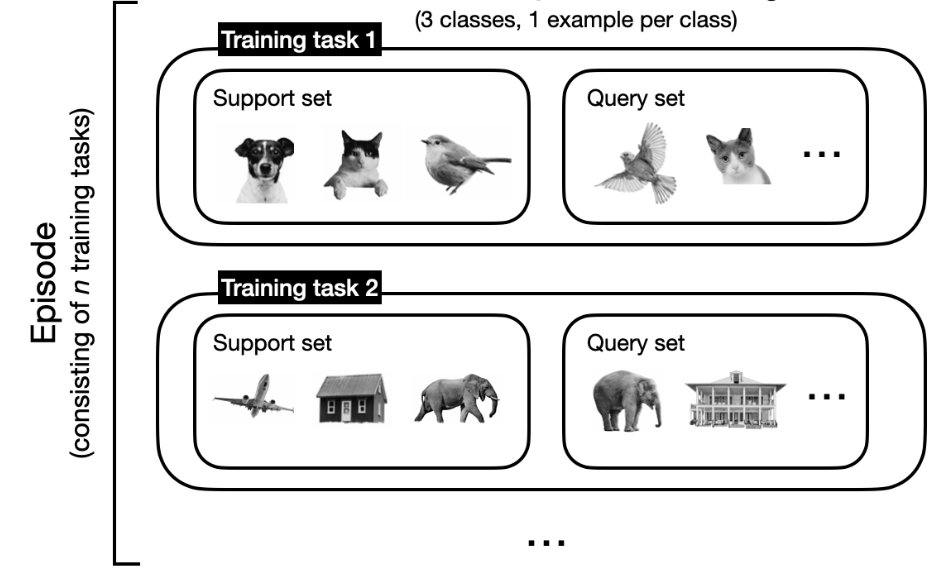
We call the N * K dataset a support set S, from which we derive a query set Q containing samples for classification. We train the model on several training tasks – called an episode – each consisting of several support and query sets.
The image below clarifies the concept.
Training Tasks: The query set Q contains images that the model must classify during training by learning patterns from the support set S – source.
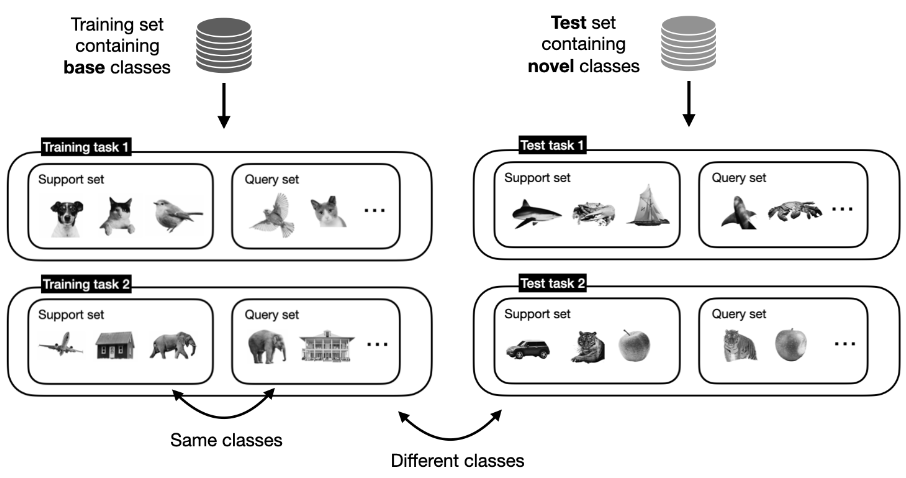
Once training is complete, we validate the model on several test tasks containing support and query sets whose classes and samples differ from those used in training.
Training vs. Test tasks: Query and support sets in training and test tasks do not overlap – source.
Single-Shot Learning
Single or one-shot learning (OSL) is a specific case of few-shot learning. This is where the support and query set contains a single example per class for training.
Face recognition is one example where an OSL model classifies a candidate’s face based on a single reference image.
Zero-Shot Learning
Lastly, we have zero-shot learning (ZSL), aiming to classify data samples with zero training examples. The trick is to train the model using a similar dataset of labeled classes and auxiliary information. Auxiliary information can include text descriptions, summaries, definitions, etc., to help the model learn general patterns and relationships.
For example, you can train a ZSL model on a dataset containing images and descriptions or labels of land animals.
Once trained, the model can classify marine animals using the knowledge gained from learning patterns in the training set.
Few-Shot Learning Approaches
The research community uses multiple approaches to develop FSL, ZSL, and OSL models. Let’s briefly overview each method to understand the N-shot learning paradigm better.
We often term the FSL approach as meta-learning. The objective is to teach a model how to learn by classifying different samples in multiple training tasks.
Within meta-learning, you have a data-based approach and a parameter-level approach. The former simply means synthesizing more data for training tasks using generative and augmentation methods. The latter involves directing the model to find an optimal parameter set using regularization techniques and carefully crafted loss functions.
The following algorithms combine the two approaches to solve the FSL problem.
Model Agnostic Meta-Learning (MAML)
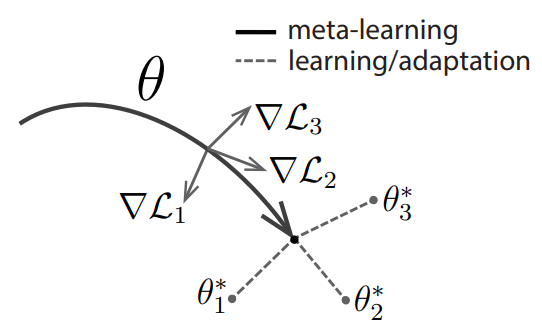
In MAML, the task is to find a suitable pre-trained parameter set that can quickly adapt and approach the most optimal parameters for a particular task with only a few gradient steps. The technique requires no prior assumption regarding the original model.
MAML: The pre-trained parameter theta is such that it requires only a few learning steps to approach the optimal set theta-star for new tasks – source.
Prototypical Networks
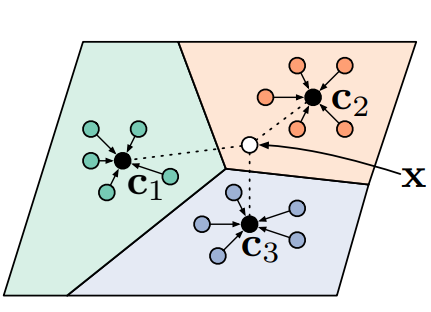
Prototypical networks for few-shot learning compute embeddings over different samples in training tasks and calculate a mean embedding per class, called a prototype.
Learning involves minimizing the loss function based on the distance between the prototype and the embedded query sample.
Prototypical Network: The algorithm computes prototypes c_k using examples per class and classifies a query data point x by measuring its distance from c_k – source.
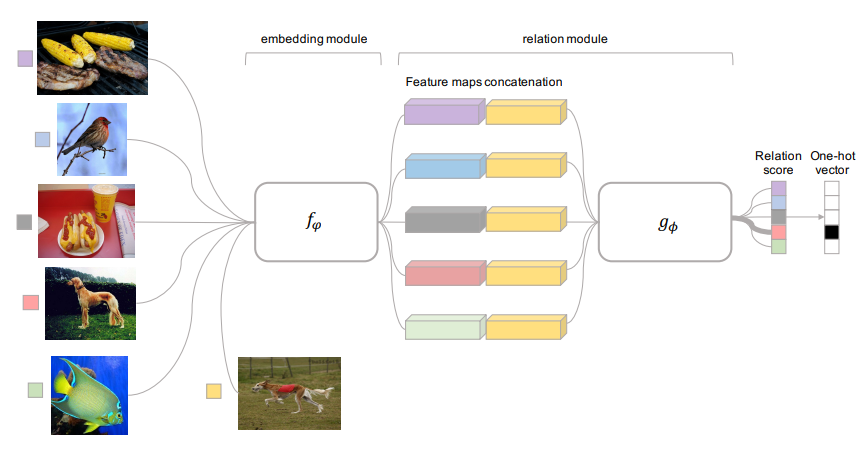
Relation Networks
Relation networks compute the prototype for each class and concatenate the query embedding with each prototype to compute a relation score. The pair with the highest score is used to classify the query set sample.
Relation Networks: The embedding module computes embeddings for each class in the support set, and the relation module concatenates the query embedding to compute the relation score – source.
Single-Shot Learning Approaches
Single-shot techniques involve matching, siamese, and memory-augmented networks. In the following, we will look into those in more detail.
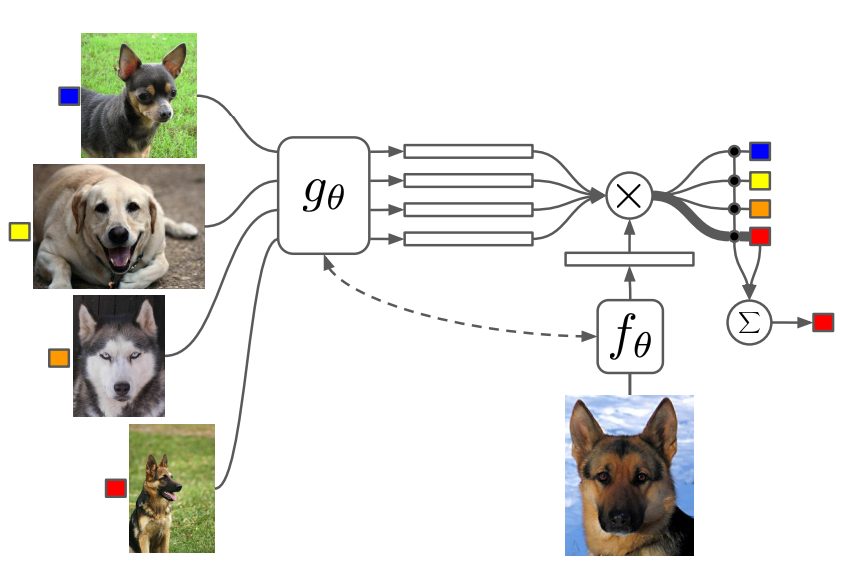
Matching Networks
Matching networks learn separate embedding functions for the support and query sets and classify the embedded query through a nearest-neighbor search. The diagram below illustrates the algorithm.
Matching Networks: The algorithm computes embeddings using a support set, and one-shot learns by classifying the query data sample based on which support set embedding is closest to the query embedding – source.
The embedding functions can be convolutional neural networks (CNNs). This allows you to apply gradient descent and attention mechanisms for faster learning.
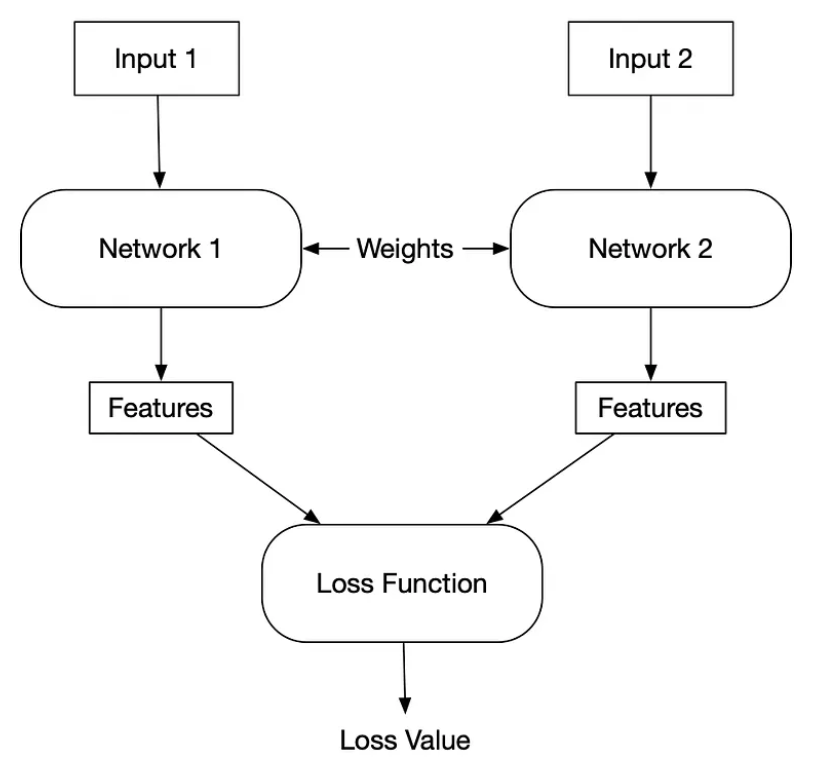
Siamese Neural Networks
Siamese networks optimize a triplet loss function to distinguish between an input sample and a reference data point called the anchor.
The network comprises two sub-networks with the same architecture, parameters, and update process. The sub-networks compute the feature vectors for the anchor, a positive sample, which is a variation of the anchor, and a negative sample, which differs from the anchor.
Siamese Neural Network: Each sub-network takes two inputs (one anchor and one positive or negative sample) for comparison. The model minimizes a triplet loss function by measuring the distance between the input’s feature vectors – source.
The network aims to learn a similarity function to maximize the distance between the anchor and the negative sample and minimize it against the positive sample.
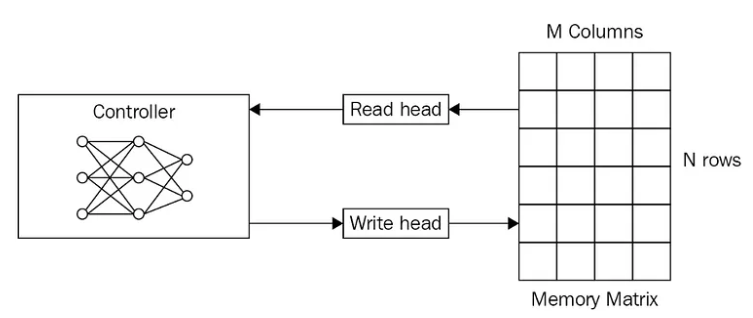
Memory-Augmented Neural Networks (MaNNs)
Memory-Augmented Neural Networks consist of a controller, read and write heads, and a memory module.
MANN Architecture: The controller connects with the memory module through the read and write heads. Each cell in the memory matrix consists of patterns, relationships, and context – source.
The controller is a neural network that computes underlying data patterns and writes them to the memory module. The controller reads the memory module for classifying a query sample by comparing its features against those stored in memory.
Zero-Shot Learning Approaches
ZSL involves embedding-based and generative-based approaches.
Embedding-Based Approach
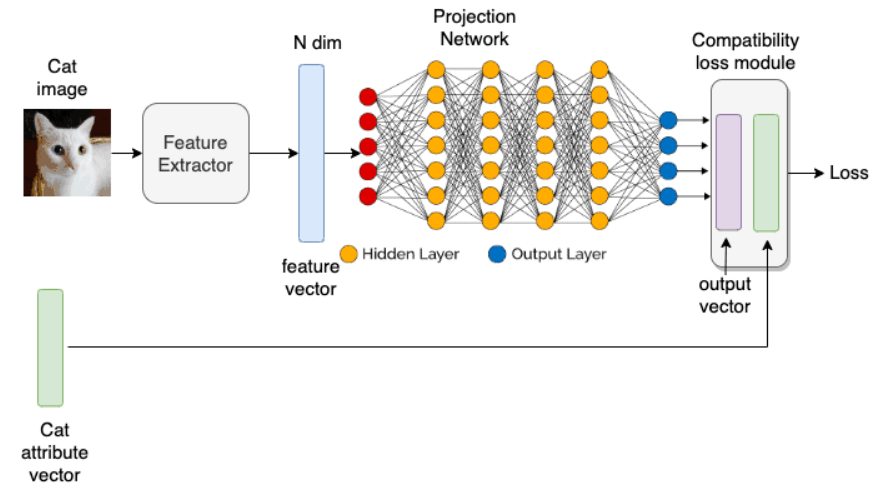
In the embedding-based approach, a feature extractor converts data with labeled classes into embeddings. It projects these embeddings into a lower-dimensional output vector – called the semantic space – using a deep neural network. This semantic space serves as a refined feature representation.
Training happens by learning a projection function. The projection function correctly classifies data from seen classes by comparing the output from the network with the attribute vector of a seen class. The process involves refining the feature representation in the semantic space, enabling effective learning and classification tasks.
Embedding-based approach: The network converts the cat’s image into an output vector. The model learns to produce an output vector matching the attribute vector to minimize loss – source.
The testing phase involves passing an unknown class’s attribute vector to the network and comparing its embeddings with those in the semantic space learned during training. The machine learning model assigns the unknown sample a class whose embedding is closest to the embedding of the unknown class.
Contrastive Language-Image Pre-Training (CLIP) is a popular ZSL model that uses a variant of the embedding-based approach by converting images and corresponding labels into embeddings through image and text encoders.
Generative-Based Approach
Embedding-based methods do not perform well in cases where unknown classes differ significantly from those in the training set. The reason for low performance is that the model is biased toward predicting labels present in the training set only and tends to misclassify novel classes.
A more recent approach involves generative methods where we aim to train a neural net on seen and unseen class feature vectors. This allows for a more balanced predictive performance. Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) are two primary methods under this approach.
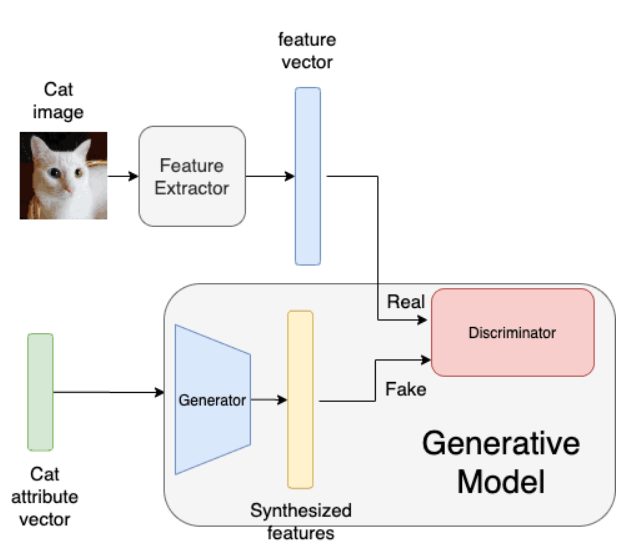
GANs: In Generative Adversarial Networks, we use a feature extractor to generate a feature vector of a seen class and pass it to a discriminator. Next, we pass the attribute vector of the seen class to a generator and train it to produce a synthesized feature vector. The discriminator compares the original feature vector and the synthesized variant to discriminate between the two.Learning happens by teaching the generator to produce a synthesized vector indistinguishable from the original vector.
GANs: Training the Generator – source.
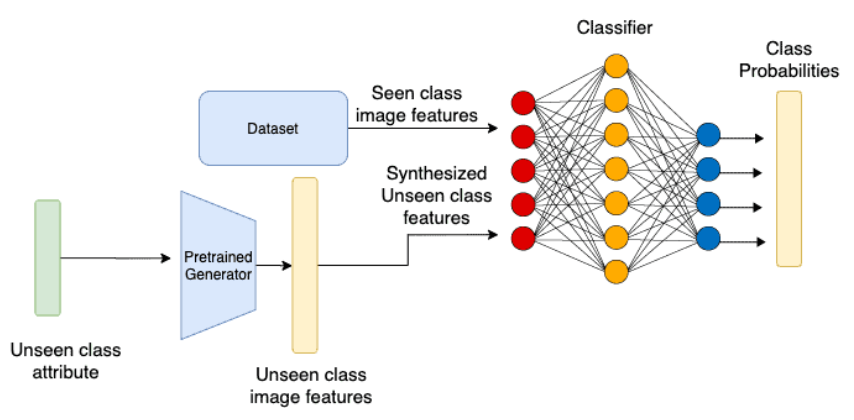
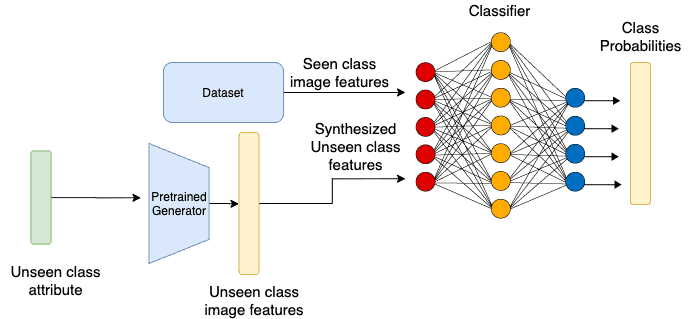
Once trained, we pass the attribute vector of the unknown class to the generator to get suitable feature vectors. We then train the projection network using feature vectors of known and unknown classes to avoid bias.
GANs: Using the Generator to create synthetic feature vectors – source.
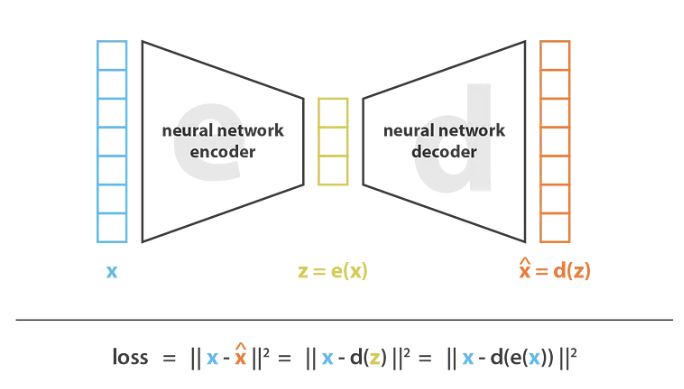
VAEs: VAEs use an encoder module to convert data samples from known classes concatenated with their attribute vectors into a latent distribution within the embedding space. The decoder network samples a random point from the latent distribution and predicts the label by reconstructing it into its original form. You train the decoder to correctly generate the original sample by minimizing the decoder’s reconstruction loss.
VAE: Encoder module converts attribute vector x of a known class into a latent distribution z. The decoder network attempts to reconstruct x from z – source.
Once trained, we can pass the attribute vector of unknown classes to the decoder network and generate sufficient labeled data samples. We can use these and samples from the known class for a more balanced training process.
N-Shot Learning Benchmarks
We use several benchmarks to compare the performance of FSL, OSL, and ZSL models on publicly available datasets such as MNIST, CUB-200-2011, ImageNet, etc. Famous metrics for evaluation include F1-score, top-1 accuracy, and mean average precision (mAP).
These metrics help assess classification problems and performance by computing the number of correct and incorrect predictions against the test set ground truth.
The state-of-the-art (SOTA) for OSL is the Siamese Network, with a 97.5 accuracy score on the MNIST dataset. MAML has a 97 accuracy score on the Double MNIST dataset consisting of classes from 00 to 99.
The CLIP model for ZSL shows 64.3% accuracy on the ImageNet dataset consisting of a thousand object classes with over a million training examples. On the Caltech-USCD Birds-200-2011 (CUB-200-2011) dataset, the SOTA ZSL model stands at a 72.3 top-1 average classification accuracy score.
N-Shot Learning Applications
As discussed earlier, FSL, OSL, and ZSL allow you to apply AI in multiple real-world scenarios where sufficient labeled data is lacking. Below are a few use cases of these N-shot learning algorithms.
Medical Image Analysis: FSL models can help healthcare professionals build AI systems to analyze rare and complex medical images. They can train such models on a few examples for efficient diagnosis and patient outcomes.
Visual-Question Answering (VQA): ZSL models like CLIP can analyze multimodal datasets and relate textual descriptions to image embeddings. The functionality allows you to build VQA systems for analyzing images in multiple domains. For instance, in retail, for searching relevant products, in manufacturing for quality assurance, and in education for helping students learn concepts through visuals.
Autonomous Driving: Self-driving cars use ZSL models to detect unknown objects on roads for better navigation.
Image Retrieval and Action Recognition: ZSL helps you build retrieval systems that associate unknown image categories with known classes. Also, you can detect label actions a person performs in a video using ZSL, as it can recognize unknown actions efficiently.
Text Classification: N-shot learning models can be trained to accurately classify and comprehend textual data with minimal labeled examples. This is useful when obtaining a large labeled dataset is challenging. Thus, allowing for effective text classification with only a limited set of examples.
Face Recognition: Face Recognition is a prime application for OSL models where frameworks like the Siamese network compare a reference photo with a person’s input image to verify a person’s identity.
N-Shot Learning for Crowd Face Recognition using Viso Suite
Learning Challenges
As the need for AI increases in several domains, new challenges emerge, driving innovative research and development. Let’s explore a few of the main challenges of FSL, OSL, and ZSL and the latest research.
The challenges in N-shot learning involve hubness, overfitting and bias, computational power, and semantic loss.
Hubness: Hubness occurs when ZSL models predict only a few labels for novel classes. The problem is prominent where embeddings are high-dimensional, causing most samples to form clusters around a single class. During a nearest-neighbor search, the model mostly predicts a label belonging to this class.
Overfitting and Bias: FSL models use only a few samples for learning, making them biased toward the training set. The remedy for this is to have a large base dataset from which to create ample training tasks with support and query sets.
Computational Power: While training N-shot models is computationally efficient, classifying unknown samples relies on similarity search. This can require different degrees of computing power based on data complexity. Transfer learning with pre-trained models can be a viable alternative here, especially when dealing with complex tasks and limited labeled data.
Semantic Loss: N-shot learning approaches that transform data into embeddings can lead to semantic loss when the transformation process results in the loss of critical information.
N-Shot Learning for Small Object Detection with Viso Suite
Latest Research Trends
Researchers are exploring ways to integrate multimodal data for FSL. For instance, recent research from Carnegie Mellon developed a framework to use audio and text to learn about visual data.
Another research involves using Siamese neural nets to detect malware. The method overcomes the issue of data scarcity, as sufficient malware samples are difficult to find.
Finally, a paper from the University of British Columbia builds a technique for creating prompts to retrieve relevant code for fine-tuned training of FSL models on code-related tasks.
N-Shot Learning – Key Takeaways
N-shot learning is a vast field involving multiple algorithms, applications, and challenges. Below are a few points you should remember.
N-shot learning types: Few-shot, one-shot, and zero-shot are the primary learning paradigms that help you build classification and detection models with only a few training samples.
N-shot learning approaches: FSL approaches involve MAML, Prototypical, and relation networks, while OSL frameworks include MANNs, Siamese, and Matching networks. ZSL models can use generative or embedding-based methods.
N-shot learning challenges: Model overfitting and bias are the most significant challenges in FSL and ZSL models, while the computational power required for classification is an issue in OSL frameworks.
You can read more about computer vision in the following blogs:



{kind=link}