
This article provides an introduction to data collection for AI model training in computer vision. Data preparation for machine learning (ML) is an essential step toward the training of a high-performing ML model that can be used by computers to analyze video or image data.
We will cover machine learning data preparation and how to create a dataset using image or video data from a camera to train a custom machine learning model. Depending on the use case, you can reuse existing photos or video files from private databases or public datasets, or record footage to prepare data for machine learning tasks.
Data Collection To Train AI Models
AI models are software programs that have been trained on a set of data to perform specific decision-making tasks. Simply speaking, these models are developed to replicate the thinking and decision-making process of human experts. Similar to humans, artificial intelligence methods require data sets to learn from (ground truth) to apply the insights to new data.
The data collection process is crucial for developing an efficient ML model. The quality and quantity of your dataset directly affect the AI model’s decision-making process. These two factors determine the robustness, accuracy, and performance of the AI algorithms. As a result, collecting and structuring data is often more time-consuming than training the model on the data.
The data collection is followed by image annotation, the process of manually providing information about the ground truth within the data. In simple words, image annotation is the process of visually indicating the location and type of objects that the AI model should learn to detect.
For example, to train a deep learning model for detecting cats, image annotation would require humans to draw boxes around all the cats present in every image or video frame. In this case, the bounding boxes would be linked to the label named “cat.” The trained model will be able to detect the presence of cats in new images.

What Is Data Collection for Machine Learning?
Data collection is the process of gathering relevant data and arranging it to create data sets for machine learning. The type of data (video sequences, frames, photos, patterns, etc.) depends on the problem that the AI model aims to solve. In computer vision, robotics, and video analytics, AI models are trained on image datasets to make predictions related to image classification, object detection, image segmentation, and more.
Therefore, the image or video data sets should contain meaningful information that can be used to train the model for recognizing various patterns and making recommendations based on the same. Therefore, the characteristic situations need to be captured to provide the ground truth for the ML model to learn from.
For example, in industrial automation, image data needs to be collected that contains specific part defects. Therefore a camera needs to gather footage from assembly lines to provide video or photo images that can be used to create a dataset.

How To Create an Image Dataset for Machine Learning
Creating a proper machine learning dataset is a complex and laborious process. You need to follow a structured approach to acquiring data that can be used to form a high-quality dataset. The first step in data collection is identifying the different data sources you’ll be using for training the particular model. There are several sources available when it comes to image or video data collection for computer vision-related tasks.
Use a Public Image Dataset
The easiest way is to opt for a public machine learning dataset. Those are generally available online, are open-source, and are free to use, share, and modify by anyone. However, make sure to check the license of the dataset. Many public datasets require a paid subscription or license if used for commercial ML projects. In particular, copyleft licenses may pose a risk if used in commercial projects because they require that any derivative works (your model or the entire AI application) be made available under the same copyleft license.
Public datasets contain collections of data for machine learning, some containing millions of data points and an immense amount of annotations that can be reused for training or fine-tuning AI models. Compared to creating a custom data set by collecting video data or images, it’s much faster and cheaper to use a public dataset. Using a fully prepared dataset is favorable if the detection task involves common objects (people, faces) or situations and is not highly specific.
Some datasets are created for specific computer vision tasks such as object detection, facial recognition, or pose estimation. Hence, they may be unsuitable to use for training your own AI models to solve a different problem. In this case, the creation of a custom dataset is required.
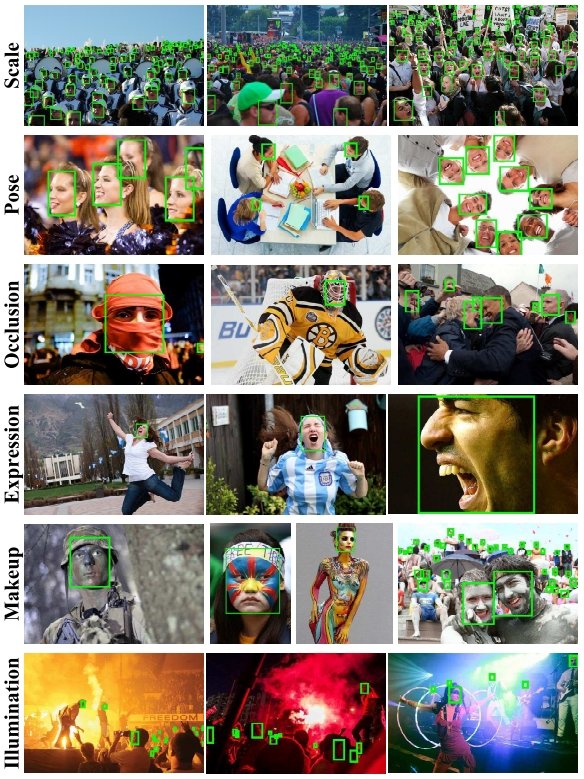
Create a Custom Dataset
Custom training sets for machine learning can be created by collecting data using web scraping software tools, cameras, and other devices with a sensor (mobile phones, CCTV video cameras, webcams, etc.). Third-party dataset service providers can help with data collection for machine learning tasks. This is a good choice if you don’t have the resources or software tools to create a quality dataset yourself.
Modern computer vision platforms such as Viso Suite provide the ability to collect video data with the same devices used to apply the AI model for inferencing tasks (computer vision applications). This is probably the easiest and fastest way to gather a high-quality dataset for specific tasks. Using the same edge devices to collect ML training data and perform inference tasks (“applying the AI model”) is a new trend in Edge AI that allows high-performance on-device machine learning with small datasets.
Regardless of which data collection source you use, it’s important to align the data with the specific goals and characteristics of the machine learning or computer vision task. In addition, you need to annotate the data and label the individual data points appropriately so that they fit well with the type of AI algorithm that you intend to use.
Image Data Collection (Image Datasets)
Most computer vision-related models are trained on data sets consisting of hundreds (or even thousands) of images. A good dataset is essential to ensure that your AI model can classify or predict the outcomes with high accuracy. However, new methods are much more efficient and allow us to achieve the same accuracy/performance with significantly smaller data sets.
There are a few key characteristics that can help you identify a good image dataset to improve the accuracy of the computer vision algorithm. Firstly, the images in your data need to be of high quality. In other words, the image should be detailed enough to enable the AI model to identify and locate the target object.
In most cases, AI algorithms don’t yet achieve human-level accuracy on computer vision tasks. Hence, if you are having trouble identifying the object in an image at first glance, you can’t expect your machine learning model to provide accurate results.
Secondly, the collected image data types need to have variety. The greater the variety in the training dataset, the better the robustness of the AI algorithm and its performance in different settings. Unless you have a healthy collection of objects, scenarios, or even groups, your computer vision model is sure to struggle to maintain consistency in its predictions.
Third, the amount of data is a very significant factor. In general, your data set should consist of plenty of images – the more, the better! Training your models on a large amount of accurately labeled data will maximize their chances of coming up with accurate predictions. Not only the number of images but also the density of target objects within the images is crucial for a good dataset. After all, there is a thing called too much data when it comes to training your AI models.
Best Public Sources For Image Data Collection
ImageNet
The ImageNet dataset is one of the most popular image databases for computer vision applications. It provides over 14 million annotated images divided across 20’000 categories and is an open database that is free to researchers for non-commercial use.
MS Coco
MS Coco, which stands for Common Objects in Context, is a large-scale image dataset published by Microsoft. It has an extensive collection of annotated image data specifically useful for image detection, segmentation, and captioning applications. To learn more, I recommend reading our article What is the COCO Dataset? What you need to know.

Google’s Open Images
The Open Images Dataset (OID) is an open-source project published by Google. The free dataset provides collections of more than 9 million images that are available with rich annotations (8.4 objects per image on average). It provides databases and samples for machine learning and computer vision tasks. The OID is provided under the CC-by 4.0 license that allows commercial use (“copyright” free).
CIFAR-10
CIFAR-10 is one of the most widely used datasets in computer vision. The dataset is divided into 10 classes, each with 6000 low-resolution images, a total of 50’000 training images, and 10’000 test images. The data set CIFAR-10 is used primarily for research purposes.
Video Data Collection (Video Datasets)
While computer vision models are predominantly trained on image datasets, they may not provide satisfactory results in certain situations. For example, you may not get the proper outcomes when you build a computer vision model for tasks like video classification, motion detection, human activity recognition, anomaly detection, or video object tracking.
Videos are, generally speaking, just a set of images arranged in a particular order. Hence, video ML data collection also involves the collection and annotation of individual images (frames). Thus, models trained on video data work quite similarly to those trained on image data sets. The process of video data collection essentially starts with identifying the best sources. Training your computer vision model on a high-quality video dataset is significant for increasing the accuracy of the predictions.
The following example shows a computer vision application in agriculture built with the low-code platform Viso Suite. We collected video data and annotated over 30’000 animal instances (pigs) to train our deep learning algorithm that can be deployed to edge devices and analyze video streams in real time.
Due to the lack of available video material, popular sources are one or multiple online video databases like YouTube-8 M, Kinetics, UCF101, etc. Most specific computer vision applications, especially in industrial automation or medical imaging, require recording video material that contains relevant situations and objects.
After identifying the right data source, you have to record the video files before extracting the frames from the video to classify or label them individually. Then, finally, you need to preprocess the raw video data to convert it into a usable dataset to train your AI model. Preprocessing the data ensures a clean and high-quality data set that can work well with machine learning or deep learning algorithms.
Tools for Video Data Collection, Machine Learning, and Annotation
Popular open-source tools to record video footage include OBS Studio and VirtualDub. However, storing the raw frames without quality loss is surprisingly challenging since downsampling (reducing the bit rate), rescaling, and converting could alter the image quality and ultimately result in poor algorithm performance.
When you use an end-to-end computer vision platform such as Viso Suite, you can collect, store, and annotate data in one place. This likely provides the best results because you can collect highly relevant data from devices to which the trained AI model is later deployed. This means you need a small image dataset to train your ML model and achieve better efficiency and machine learning performance of custom computer vision solutions.
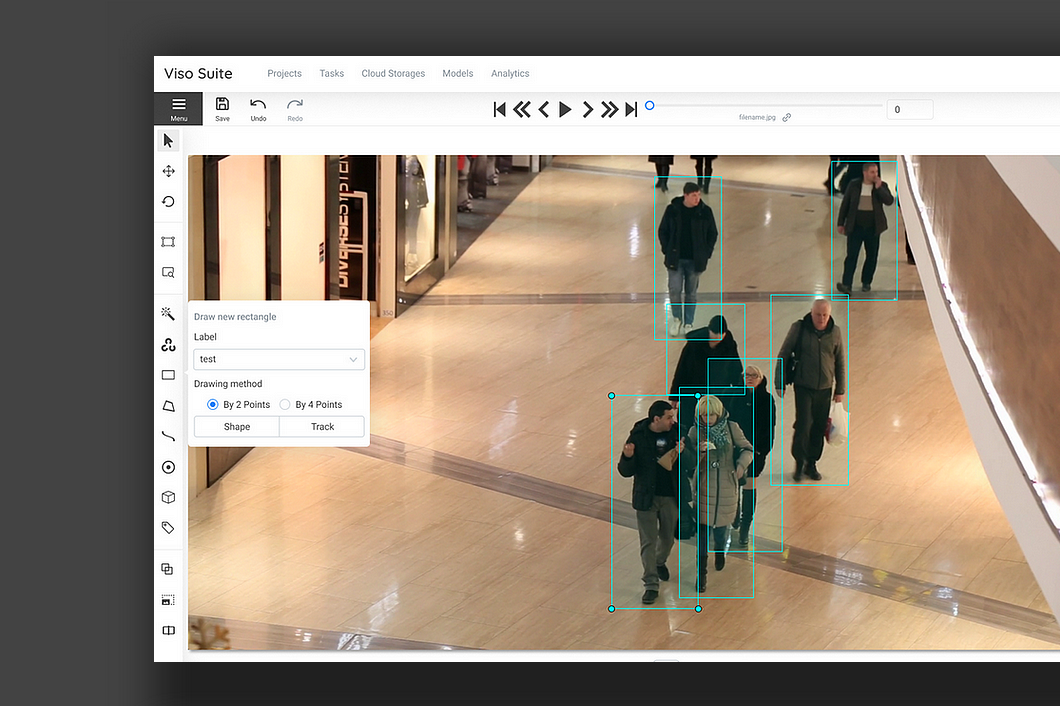
To annotate the image data you have collected, you can use commercial tools or widely popular open-source software (which many commercial tools are built upon). For example, you might want to check out the Computer Vision Annotation Tool (CVAT) that is developed and open-sourced by Intel. To find all the best tools for image annotation and labeling, check out our article: What is Image Annotation? (Easy-to-understand Guide).
Conclusion and How To Get Started
Data collection is a tough yet essential part of creating your computer vision application. Depending on the specific task at hand, you can either choose from the various publicly available datasets or create a custom one by gathering data manually. Because in the end, the success of your computer vision model depends to a great extent on the quality and quantity of the data used for training it.
If you are looking for an enterprise-grade platform that you can use to collect video data at scale, check out Viso Suite infrastructure. The enterprise-grade solution helps businesses cover the entire application lifecycle, from data collection to annotation, device management, and AI model deployment.
Industry leaders use Viso Suite to manage AI models and deliver their real-world AI vision applications with one automated platform and without writing code. Reach out to learn more.
Read more about related topics: