Contrastive Language-Image Pre-training (CLIP) is a multimodal learning architecture developed by OpenAI. It learns visual concepts from natural language supervision. It bridges the gap between text and visual data by jointly training a CLIP model on a large-scale dataset containing images and their corresponding textual descriptions. This is similar to the zero-shot capabilities of GPT-2 and GPT-3.
This article will provide insights into how CLIP bridges the gap between natural language and image processing. In particular, you’ll learn:
- How does CLIP work?
- Architecture and the training process
- How CLIP resolves key challenges in computer vision
- Practical applications
- Challenges and limitations while implementing CLIP
- Future advancements
How Does CLIP Work?
CLIP (Contrastive Language–Image Pre-training) is a model developed by OpenAI that learns visual concepts from natural language descriptions. Its effectiveness comes from a large-scale, diverse dataset of images and texts.
What is contrast learning?
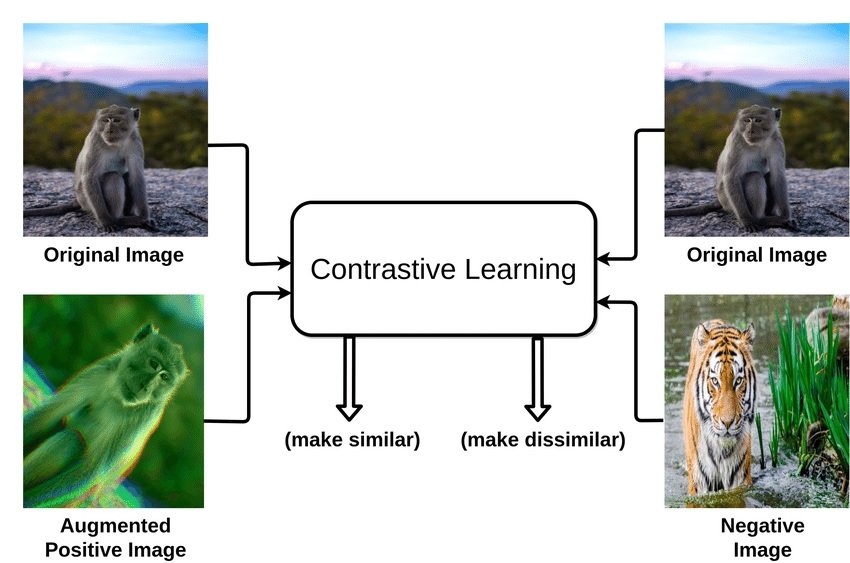
Contrastive learning is a technique used in machine learning, particularly in the field of unsupervised learning. Contrastive learning is a method where we teach an AI model to recognize similarities and differences of a large number of data points.
Imagine you have a main item (the “anchor sample”), a similar item (“positive”), and a different item (“negative sample”). The goal is to make the model understand that the anchor and the positive item are alike, so it brings them closer together in its mind while recognizing that the negative item is different and pushing it away.
What is an example of contrast learning?
In a computer vision example of contrast learning, we aim to train a tool like a convolutional neural network to bring similar image representations closer and separate the dissimilar ones.
A similar or “positive” image might be from the same category (e.g., dogs) as the main image or a modified version of it, whereas a “negative” image would be entirely different, typically from another category (e.g., cats).
CLIP Architecture explained
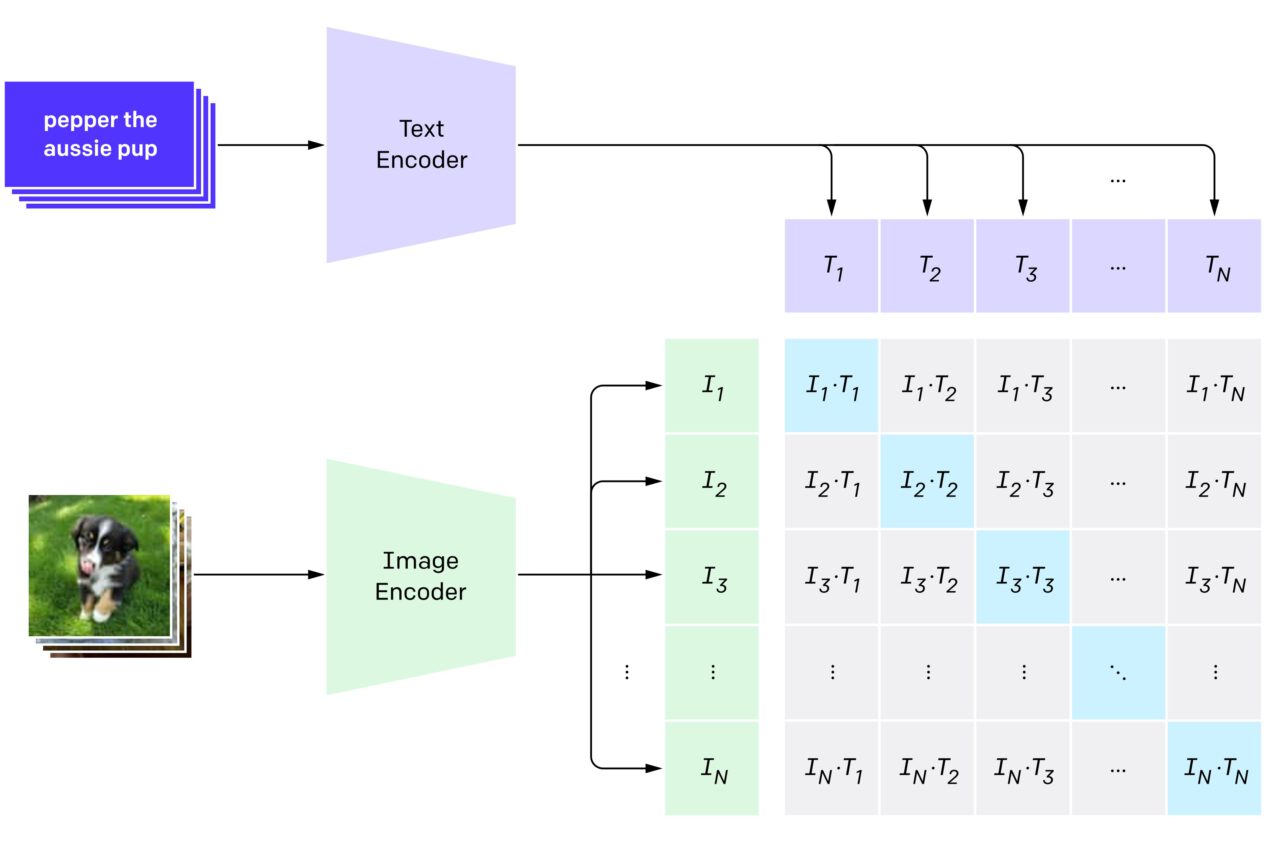
Contrastive Language-Image Pre-training (CLIP) uses a dual-encoder architecture to map images and text into a shared latent space. It works by jointly training two encoders. One encoder for images (Vision Transformer) and one for text (Transformer-based language model).
- Image Encoder: The image encoder extracts salient features from the visual input. This encoder takes an ‘image as input’ and produces a high-dimensional vector representation. It typically uses a convolutional neural network (CNN) architecture, like ResNet, for extracting image features.
- Text Encoder: The text encoder encodes the semantic meaning of the corresponding textual description. It takes a ‘text caption/label as input’ and produces another high-dimensional vector representation. It often uses a transformer-based architecture, like a Transformer or BERT, to process text sequences.
- Shared Embedding Space: The two encoders produce embeddings in a shared vector space. These shared embedding spaces allow CLIP to compare text and image representations and learn their underlying relationships.
CLIP Training Process
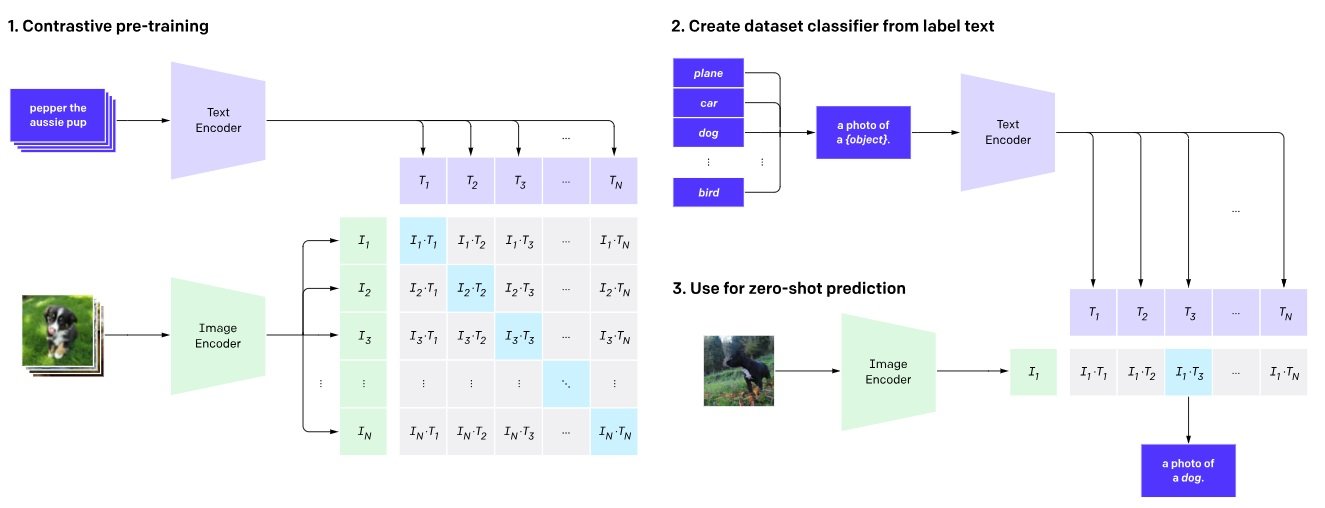
Step 1: Contrastive Pre-training
CLIP is pre-trained on a large-scale dataset of 400 million (image, text data) pairs collected from the internet. During pre-training, the model is presented with pairs of images and text captions. Some of these pairs are genuine matches (the caption accurately describes the image), while others are mismatched. It creates shared latent space embeddings.
Step 2: Create Dataset Classifiers from Label Text
For each image, multiple text descriptions are created, including the correct one and several incorrect ones. This creates a mix of positive samples (matching) and negative sample (mismatched) pairs. These descriptions are fed into the text encoder, generating class-specific embeddings.
At this stage, one crucial function also came into play: Contrastive Loss Function. This function penalizes the model for incorrectly matching (image-text) pairs. But, rewards it for correctly matching (image-text) pairs in the latent space. It encourages the model to learn representations that accurately capture visual and textual information similarities.
Step 3: Zero-shot Prediction
Now, the trained text encoder is used as a zero-shot classifier. With a new image, CLIP can make zero-shot predictions. This is done by passing it through the image encoder and the dataset classifier without fine-tuning.
CLIP computes the cosine similarity between the embeddings of all image and text description pairs. It optimizes the parameters of the encoders to increase the similarity of the correct pairs. Thus, decreasing the similarity of the incorrect pairs.
This way, CLIP learns a multimodal embedding space where semantically related images and texts are mapped close to each other. The predicted class is the one with the highest logit value.
Integration Between Natural Language and Image Processing
CLIP’s ability to map images and text into a shared space allows for the integration of NLP and image processing tasks. This allows CLIP to:
- Generate text descriptions for images. It can retrieve relevant text descriptions from the training data by querying the latent space with an image representation. In turn, effectively performing image captioning.
- Classify images based on textual descriptions. It can directly compare textual descriptions with the representations of unseen images in the latent space. As a result, zero-shot image classification is performed without requiring labeled training data for specific classes.
- Edit images based on textual prompts. Textual instructions can be used to modify existing images. Users can manipulate the textual input and feed it back into CLIP. This guides the model to generate or modify images following the specified textual prompts. This capability lays a foundation for innovative text-to-image generation and editing tools.
Major Problems in Computer Vision and How CLIP Helps
Semantic Gaps
One of the biggest hurdles in computer vision is the “semantic gap.” The semantic gap is the disconnect between the low-level visual features that computers extract from images and the high-level semantic concepts that humans readily understand.

Traditional vision models excel at tasks like object detection and image classification. However, they often struggle to grasp the deeper meaning and context within an image. This makes it difficult for them to reason about relationships between objects, interpret actions, or infer intentions.
On the other hand, CLIP can understand the relationships between objects, activities, and emotions depicted in images. Given an image of a child playing in a park, CLIP can identify the presence of the child and the park. Further, it can also infer that the child is having fun.
Data Efficiencies
Another critical challenge is the sheer amount of data required to train computer vision models effectively. Deep learning algorithms demand vast labeled image datasets to learn complex relationships between visual features and semantic concepts. Acquiring and annotating such large datasets is expensive and time-consuming, limiting the usability and scalability of vision models.
Meanwhile, CLIP can learn from fewer image-text pairs than traditional vision models. This makes it more resource-efficient and adaptable to specialized domains with limited data.
Lack of Explainability and Generalizability
Traditional computer vision models often struggle with explaining their reasoning behind predictions. This “black box” nature hinders trust and limits its application in diverse scenarios.
However, CLIP, trained on massive image-text pairs, learns to associate visual features with textual descriptions. This allows for generating captions that explain the model’s reasoning, improving interpretability and boosting trust. Additionally, CLIP’s ability to adapt to various text prompts enhances its generalizability to unseen situations.
Practical Applications of CLIP
Contrastive Language-Image Pre-training is useful for various practical applications, such as:
Zero-Shot Image Classification
One of the most impressive features of CLIP is its ability to perform zero-shot image classification. This means that CLIP can classify images it has never seen before, using only natural language descriptions.
For traditional image classification tasks, AI models are trained on specifically labeled datasets, limiting their ability to recognize objects or scenes outside their training scope. With CLIP, you can provide natural language descriptions to the model. In turn, this enables it to generalize and classify images based on textual input without specific training in those categories.
Multimodal Learning
Another application of CLIP is its use as a component of multimodal learning systems. These can combine different types of data, such as text and images.
For instance, it can be paired with a generative model such as DALL-E. Here, it will create images from text inputs to produce realistic and diverse results. Conversely, it can edit existing images based on text commands, such as changing an object’s color, shape, or style. This enables users to create and manipulate images creatively without requiring artistic skills or tools.

Image Captioning
CLIP’s ability to understand the connection between images and text makes it suitable for computer vision tasks like image captioning. Given an image, it can generate captions that describe the content and context.
This functionality can be beneficial in applications where a human-like understanding of images is needed. This may include assistive technologies for the visually impaired or enhancing content for search engines. For example, it could provide detailed descriptions for visually impaired users or contribute to more precise search results.
Semantic Image Search and Retrieval
CLIP can be employed for semantic image search and retrieval beyond simple keyword-based searches. Users can input natural language queries, and the CLIP AI model will retrieve images that best match the textual descriptions.
This approach improves the precision and relevance of search results. Thus, making it a valuable tool in content management systems, digital asset management, and any use case requiring efficient and accurate image retrieval.
Data Content Moderation
Content moderation filters inappropriate or harmful content from online platforms, such as images containing violence, nudity, or hate speech. CLIP can assist in the content moderation process by detecting and flagging such content based on natural language criteria.
For example, it can identify images that violate a platform’s terms of service or community guidelines or that are offensive or sensitive to certain groups or individuals. Additionally, it can justify decisions by highlighting relevant parts of the image or text that triggered the moderation.
Deciphering Blurred Images
In scenarios with compromised image quality, such as in surveillance footage or medical imaging, CLIP can provide valuable insights by interpreting the available visual information in conjunction with relevant textual descriptions. It can provide hints or clues about what the original image might look like based on its semantic content and context. However, it can generate partial or complete images from blurred inputs using its generative capabilities or retrieving similar images from a large database.
CLIP Limitations and Challenges
Despite its impressive performance and potential applications, CLIP also has some limitations, such as:
Lack of Interpretability
Another drawback is the lack of interpretability in CLIP’s decision-making process. Understanding why the model classifies a specific image in a certain way can be challenging. This can hinder its application in sensitive areas where interpretability is crucial, such as healthcare diagnostics or legal contexts.
Lack of Fine-Grained Understanding
CLIP’s understanding is also limited in terms of fine-grained details. While it excels at high-level tasks, it may struggle with intricate nuances and subtle distinctions within images or texts. Thus, limiting its effectiveness in applications requiring granular analysis.
Limited Understanding of Relationships (Emotions, Abstract Concepts, etc.)
CLIP’s comprehension of relationships, especially emotions and abstract concepts, remains constrained. It might misinterpret complex or nuanced visual cues. In turn, impacting its performance in tasks requiring a deeper understanding of human experiences.

Biases in Pretraining Data
Biases present in the pretraining data can transfer to CLIP, potentially perpetuating and amplifying societal biases. This raises ethical concerns, particularly in AI applications like content moderation or decision-making systems. In those use cases, biased outcomes lead to real-world consequences.
CLIP Advancements and Future Directions
As CLIP continues to reshape the landscape of multimodal learning, its integration into real-world applications is promising. Data scientists are exploring ways to overcome its limitations, with an eye on developing even more advanced and interpretable models.
CLIP promises breakthroughs in areas like image recognition, NLP, medical diagnostics, assistive technologies, advanced robotics, and more. It paves the way for more intuitive human-AI interactions as machines grasp contextual understanding across different modalities.
The versatility of CLIP is shaping a future where AI comprehends the world as humans do. Future research will shape AI capabilities, unlock novel applications, drive innovation, and expand the horizons of possibilities in machine learning and deep learning systems.
What’s Next for Contrastive Language-Image Pre-Training?
As CLIP continues to evolve, it holds immense potential to change the way we interact with information across modalities. By bridging language and vision, CLIP promotes a future where machines can truly “see” and “understand” the world.
To gain a more comprehensive understanding, check out the following articles:
- Learn What is Natural Language Processing? A Guide to NLP
- Understand the basics to advance concepts in Supervised and Unsupervised Learning
- A Complete Guide to Image Recognition With Use Cases
- How Does Image Classification Work?
- How to identify AI-generated images, text, and video