
Face recognition is a method of identifying or verifying the identity of an individual using their face. It is one of the most important computer vision applications with great commercial interest. Hence, static or real-time face recognition is among the most widely studied topics in computer vision and artificial intelligence (AI). There is an extensive range of applications in security and surveillance, law enforcement, biometrics, services industries, marketing, and many more.

The technology is related to face detection used to detect, localize, and extract the face region from the image background before face recognition methods can be applied.
History of deep face recognition
- In the early 1990s, facial recognition technology gained popularity following the introduction of the historical Eigenface approach. In the 1990s and 2000s, holistic approaches dominated the face recognition community. Holistic approaches derive the low-dimensional representation through certain distribution assumptions, such as linear subspace, manifold, and sparse representation. The problem with holistic methods is their failure to address uncontrolled facial changes that deviate from their prior assumptions. This led to the development of local feature-based face recognition in the early 2000s.
- In the early 2000s and 2010s, local facial feature-based recognition and learning-based local descriptors were introduced. Face Recognition software using Gabor filters and Local Binary Patterns (LBP), as well as their multilevel and high-dimensional extensions, achieved robust performance through some invariant properties of local filtering. Unfortunately, handcrafted features suffered from a lack of distinctiveness and compactness. In the early 2010s, learning-based local descriptors were introduced for face recognition, in which local filters are learned for better distinctiveness, and the encoding codebook is learned for better compactness.
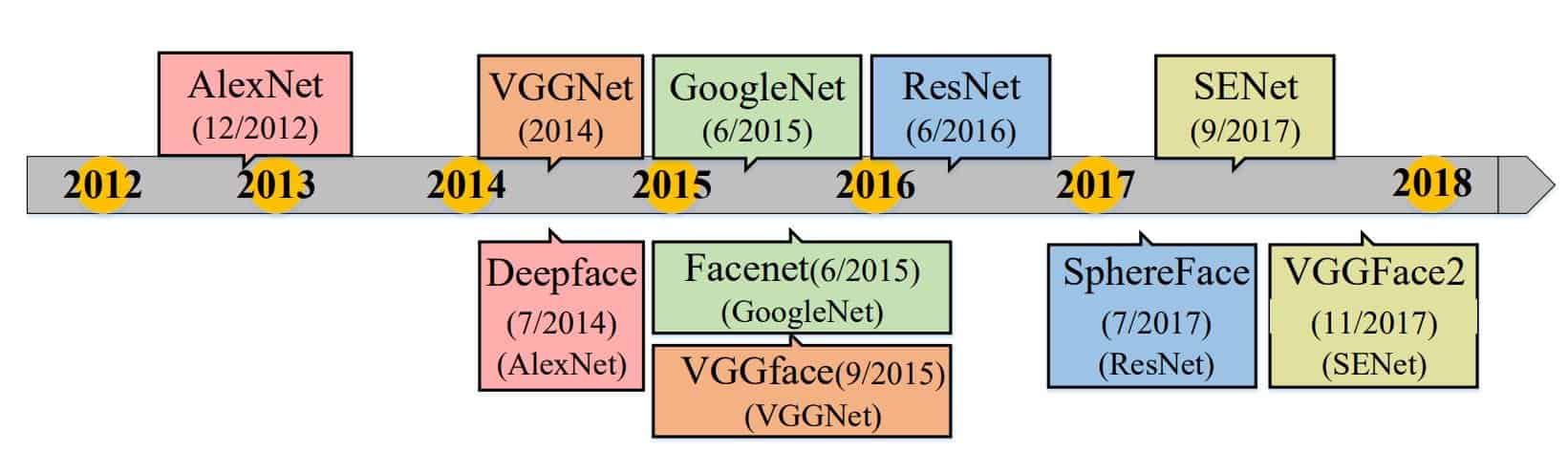
- In 2014, Facebook’s DeepFace and DeepID achieved state-of-the-art accuracy on the famous Labeled Faces in the Wild (LFW) benchmark, surpassing human performance in the unconstrained scenario for the first time. Since then, the research focus has shifted to deep-learning-based approaches. Deep learning methods use a cascade of multiple layers of processing units for feature extraction and transformation. Hence, larger-scale face databases and advanced face-processing techniques have been developed to facilitate deep face recognition. As a result, with the representation pipelines becoming deeper, the LFW (Labeled Face in the Wild) performance steadily improved from around 60% to above 97%.
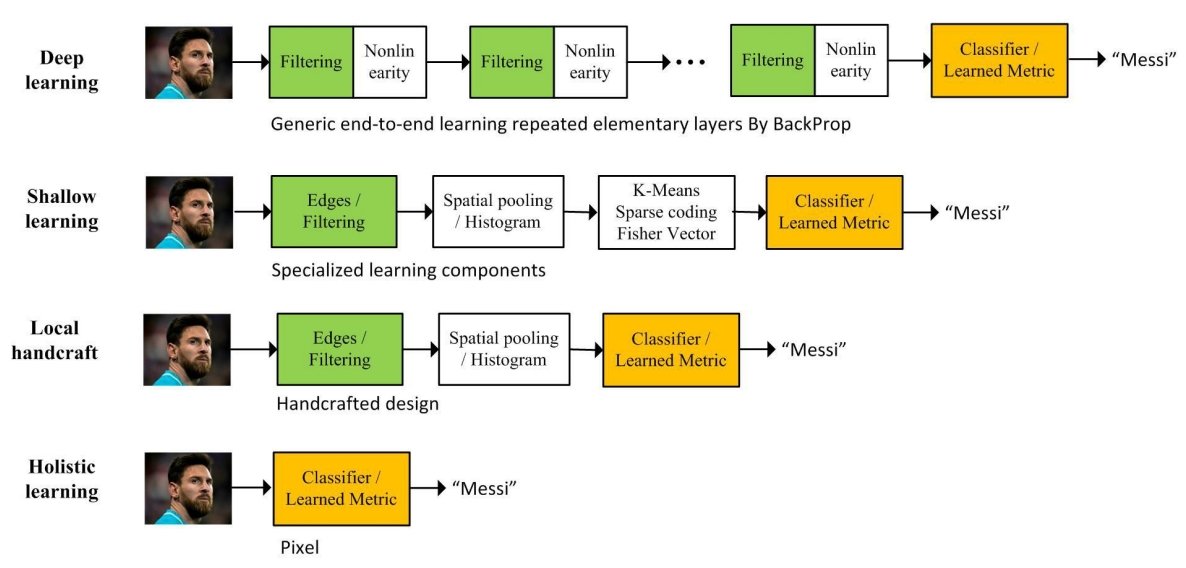
Face recognition and deep learning
Deep learning, in particular the deep convolutional neural networks (CNN), has received increasing interest in face recognition, and several deep learning methods have been proposed.
Deep learning technology has reshaped the research landscape of face recognition since 2014, launched by the breakthroughs of DeepFace and DeepID methods. Since then, deep face recognition techniques, which leverage the hierarchical architecture to learn discriminative face representation, have dramatically improved state-of-the-art performance and fostered numerous successful real-world applications. Deep learning applies multiple processing layers to learn representations of data with multiple levels of feature extraction.
In the following, the most popular evaluation datasets for face recognition are listed:
- Fast face verification datasets
- Large-scale face verification and identification datasets
- Video-based face verification datasets
- YouTube Faces Database (YTF)
How does deep neural network face recognition work?
Due to its non-intrusive and natural characteristics, face recognition has been the prominent biometric technique for identity authentication. As a result, it has been widely used in many areas, such as the military, finance, public security, and daily life.
The face recognition task is different from generic object classification tasks because of the particularity of faces: It has to deal with a massive number of classes with tiny inter-class differences and great intrapersonal variations due to different poses, illuminations, expressions, ages, and occlusions. Deep learning methods learn multiple levels of representations that correspond to different levels of abstraction. The levels form a hierarchy of concepts, showing strong invariance to the facial pose, lighting, and expression changes.
With extensive training data and modern graphics processing units (GPUs), deep face recognition methods have drastically increased in performance and fostered numerous successful real-world applications in the past five years. As a result, several surveys have been conducted on face recognition and its subdomains, including illumination-invariant face recognition, 3D face recognition, pose-invariant face recognition, masked face detection, and more.
Based on massive amounts of annotated data, algorithms, and GPUs, deep face recognition has achieved beyond human performance on some standard benchmarks, specifically near-frontal face verification, similar-looking face discrimination, and cross-age face verification.

Deep neural network face recognition applications
Face recognition variants
- 3D face recognition has inherent advantages over 2D methods, but 3D deep face recognition is not well-developed due to the lack of large annotated 3D data. To enlarge 3D training datasets, most works use the methods of “one-to-many augmentation” to synthesize 3D faces. However, the effective methods for extracting deep features of 3D faces remain to be explored.
- Partial face recognition is used to recognize an arbitrary image patch of a holistic face. Partial faces frequently appear in unconstrained image capture environments, particularly when faces are captured by surveillance cameras (CCTV) or handheld devices like mobile phones. Also, masked face recognition, a computer vision application useful for coronavirus control, falls into the category of partial face recognition.
- Face recognition for mobile devices. With the emergence of mobile phones, tablets, and augmented reality, face recognition has been applied in mobile devices. However, due to computational limitations, the recognition tasks in these devices need to be carried out in a light but timely fashion. MobiFace is a deep neural network that provides a simple but effective approach that can be used for productively deploying face recognition on mobile devices. Despite being lightweight, it achieves excellent performance results (99.7% on the LFW database and 91.3% on the Megaface database).
Face anti-attack
The success of face recognition techniques also sparked the emergence of various types of attacks, mainly adversarial machine learning attacks, that may become big threats.
- Face spoofing involves presenting a fake face to the biometric sensor using a printed photograph, a worn mask, or even an image displayed on another electronic device. To defend against this type of attack, multiple methods were developed, for example, a two-stream CNN in which the local features discriminate the spoof patches that are independent of the spatial face areas. Another method is the use of holistic depth maps to ensure that the input live sample has a face-like depth. Neural networks have been fine-tuned from a pre-trained model by training sets of real and fake images (deepfakes).
- Adversarial perturbation is another type of attack that can be defined as the addition of a minimal vector. With the addition of this vector to the input image, the deep learning model misclassifies the input. There are implementations of adversarial detection and mitigation algorithms.
- Template reconstruction attacks: A neighborly deconvolutional neural network (NbNet) can be used to reconstruct face images from their deep templates.
Despite the progress of anti-attack algorithms, attack methods are updated as well, and facial recognition systems need to increase security and robustness further.

Debiasing facial recognition systems
Existing datasets are highly biased in terms of the distribution of demographic cohorts, which may dramatically impact the fairness of deep models. To address this issue, some works seek to introduce fairness into facial recognition software and mitigate demographic bias, for example, unbalanced training, attribute removal, and domain adaptation.
- Unbalanced training methods mitigate the bias via model regularization, taking into consideration the fairness of face recognition systems. A prominent issue is an imbalanced representation, such as the underrepresentation of certain demographic groups in data for face recognition. For example, error rates for non-Caucasians are usually much higher compared to those for Caucasians. A reinforcement learning-based race balance network (RL-RBN) was developed to mitigate bias in face recognition using skewness-aware reinforcement learning. The method is an approach to reducing the skewness of feature scatter between races.
- Attribute removal methods confound or remove demographic information of faces to learn attribute-invariant representations. For example, a method was introduced that applies a confusion loss to make a classifier fail to distinguish attributes of examples so that multiple spurious variations are removed from the feature representation. For example, SensitiveNets introduced privacy-preserving neural network feature representation to suppress the sensitive information of a learned space while maintaining the utility of the data. It minimizes sensitive information while maintaining distances between positive and negative embedding.
- Domain adaptation methods propose to investigate the data bias problem from a domain adaptation point of view and attempt to design domain-invariant feature representations to mitigate bias across domains. For example, an information maximization adaptation network (IMAN) was developed to mitigate racial bias, which matches global distribution at the domain level and, in the meantime, learns discriminative target distribution at the cluster level. Another method directly converted the Caucasian data to the non-Caucasian domain in the image space with the help of sparse reconstruction coefficients learned in the common subspace.

What’s next for deep neural network face recognition?
If you want to learn more about other computer vision topics, we recommend you explore the following articles:
- Learn about Adversarial Machine Learning, used to attack ML models
- Everything you need to know about Pose Estimation
- The Guide to Image Data Augmentation for Computer Vision
- Read about Self-supervised Learning
- Explore an extensive list of computer vision applications
- DeepFace, the most powerful deep face recognition library
- What is AI Pattern Recognition? A Gentle Introduction