
Image segmentation is a fundamental computer vision task that aims to partition a digital image into multiple segments or sets of pixels. These segments correspond to different objects, materials, or semantic parts of the scene. The goal of image segmentation is to simplify and/or change the representation of an image into something more meaningful and easier to analyze. There are three main types of image segmentation: semantic segmentation, instance segmentation, and panoptic segmentation.
What is Panoptic Segmentation?
The term “panoptic” originates from two Greek words: “pan” (all) and “optic” (vision). In the context of computer vision, panoptic segmentation aspires to capture “everything visible” in an image. It achieves this by combining the capabilities of semantic segmentation, which assigns a class label to each pixel (e.g., car, person, tree), and instance segmentation, which identifies and separates individual object instances within a class (e.g., distinguishing between multiple cars in an image).
Panoptic segmentation provides a more comprehensive understanding of the scene that enables systems to reason about both the semantics and the instances present in the image.
Panoptic image segmentation was first introduced by Alexander Kirillov and his team in 2018. The researchers define this technique as a “unified or global view of segmentation.”
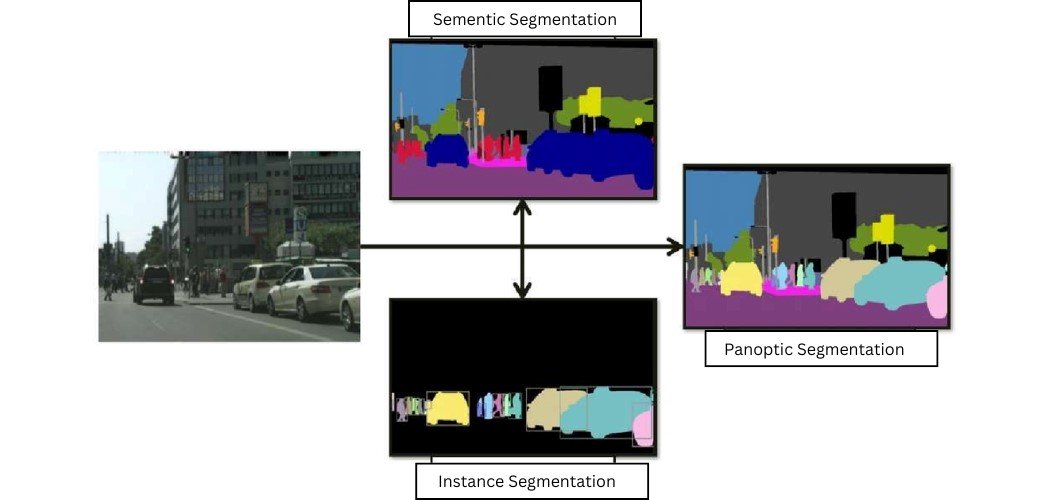
Core Principles of Panoptic Segmentation
The panoptic segmentation task can be broken down into three main steps:
Step 1 (Object separation)
First of all, the panoptic segmentation model divides a digital image into meaningful individual parts. It ensures that each object in an image is isolated from its surroundings.
Step 2 (Labeling)
Then, panoptic segmentation assigns a unique identifier (instance ID) to each separated object. It labels each separated object with a unique color or identifier.
Step 3 (Classification)
Once the objects are labeled, the background and objects are then classified into distinct categories (such as “car,” “person,” and “road”).
The final output of panoptic segmentation is a single image where each pixel is assigned a unique label that encodes both the instance ID (for objects) and the semantic class (for objects and background).
Understanding Semantic Segmentation Vs Panoptic Segmentation Vs Instance Segmentation
For a more comprehensive understanding, let’s break down the key differences between these three image segmentation techniques.
Semantic Segmentation
Semantic segmentation focuses on classifying each pixel in an image into a specific category. It assigns a unique class label to each pixel in an image and divides it into one of the predefined set of semantic categories, such as person, car, or tree. However, this segmentation technique does not differentiate between instances of the same class and treats them as a single entity.
Imagine coloring a scene where all cars are blue, all people are red, and everything else is green – that’s semantic segmentation in action.

Instance Segmentation
Instance segmentation goes a step further by not only identifying the category of an object but also delineating its boundaries. This allows us to distinguish between multiple instances of the same class.
For example, if an image contains multiple cars, instance segmentation would assign a unique label to each car, distinguishing them from one another. Similarly, if an image has more than one person, it’ll assign unique labels or distinct colors to each person in the image. In short, we can say instance segmentation technique creates separate segmentation masks/labels for each instance in a scene.

Panoptic Segmentation
Panoptic segmentation combines the strengths of semantic and instance segmentation by assigning both a semantic label and an instance ID to every pixel in the image. It assigns a unique label to each pixel, corresponding to either a “thing” (countable object instances like cars, people, or animals) or “stuff” (amorphous regions like grass, sky, or road). This comprehensive approach allows for a complete understanding of the visual scene, enabling systems to reason about the semantics of different regions while also distinguishing between individual instances of the same class.

Things and Stuff Classification in Panoptic Segmentation
In panoptic segmentation, objects in an image are typically classified into two main categories: “things” and “stuff.”
- Things: Things in a panoptic image segmentation technique refer to countable and distinct object instances within an image, such as cars, people, animals, furniture, etc. Each object and instance in a scene has well-defined boundaries and is identified and separated as individual instances.
- Stuff: Stuff in panoptic image segmentation refers to amorphous or uncountable regions in an image, such as sky, road, grass, walls, etc. These regions do not have well-defined boundaries and are typically treated as a single continuous segment without individual instances.
The classification of objects into “things” and “stuff” is crucial for panoptic image segmentation as it allows the model to apply different strategies for segmenting and classifying these two types of entities. Technically instance segmentation methods are applied to “things,” while semantic segmentation techniques are used for “stuff.”
How Does Panoptic Segmentation Work?
Traditional Architecture (FCN and Mask R-CNN Networks)
Panoptic segmentation takes the results of two different techniques, semantic and instance segmentation, and combines them into a single, unified output. Traditionally, this technique utilizes two network architectures. One network, called a Fully Convolutional Network (FCN) performs semantic segmentation tasks while the other network architecture Mask R-CNN handles instance segmentation tasks.
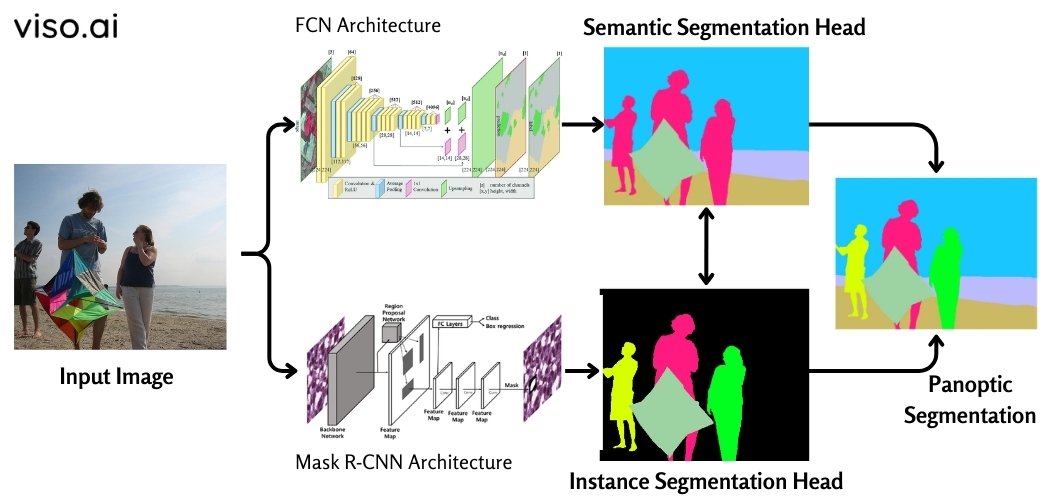
Here’s how these two networks work together:
- Output 1: Fully Convolutional Network (FCN): The FCN is responsible for capturing patterns from the objects or “stuff” in the image. It uses skip connections that enable it to reconstruct accurate segmentation boundaries and make local predictions that accurately define the global structure of the object. This network yields semantic segmentations for the amorphous regions in the image.
- Output 2: Mask R-CNN: The Mask R-CNN captures patterns of the countable objects or “things” in the image. It yields instance segmentations for these objects.
This network architecture processes its operations in two stages:
- Region Proposal Network (RPN): This process yields regions of interest (ROIs) in the image that are likely to contain objects. We can say it helps identify potential object locations.
- Faster R-CNN: This network, under Mask R-CNN, leverages the ROIs to perform object classification and create bounding boxes around the detected objects.
- Final Output: The outputs of both the FCN and Mask R-CNN networks are then combined to obtain a panoptic segmentation result, where each pixel is assigned a unique label corresponding to either a “thing” (instance segmentation) or “stuff” (semantic segmentation) category.
However, this traditional approach has several drawbacks, which may include computational inefficiency, inability to learn useful patterns, inaccurate predictions, and inconsistencies between the network outputs.
Modern Architecture (EfficientPS)
Researchers introduced a new panoptic image segmentation approach called Efficient Panoptic Segmentation (EfficientPS) to overcome the limitations of older CNN approaches. This new approach combines both semantic and instance segmentation into a single powerful network. Technically, we can say EfficientPS is an end-to-end network architecture that performs both semantic and instance segmentation simultaneously.
This advanced panoptic segmentation technique performs its operations in two stages:
- Stage 1: EfficientPS starts its operation using a backbone network. This backbone network of EfficientPS extracts meaningful features from the input image and sends them to the panoptic segmentation head for final segmentation. Some of the popular backbone networks used in this stage are ResNet, EfficientNet, and ResNeXt backbones.
- Stage 2: The meaningful features extracted from the EfficientPS backbone network are fed into another architecture called Panoptic Segmentation Head. This head uses the information from the backbone to perform two tasks at once: recognize objects (instance segmentation) and label background areas (semantic segmentation) to yield a combined final output.
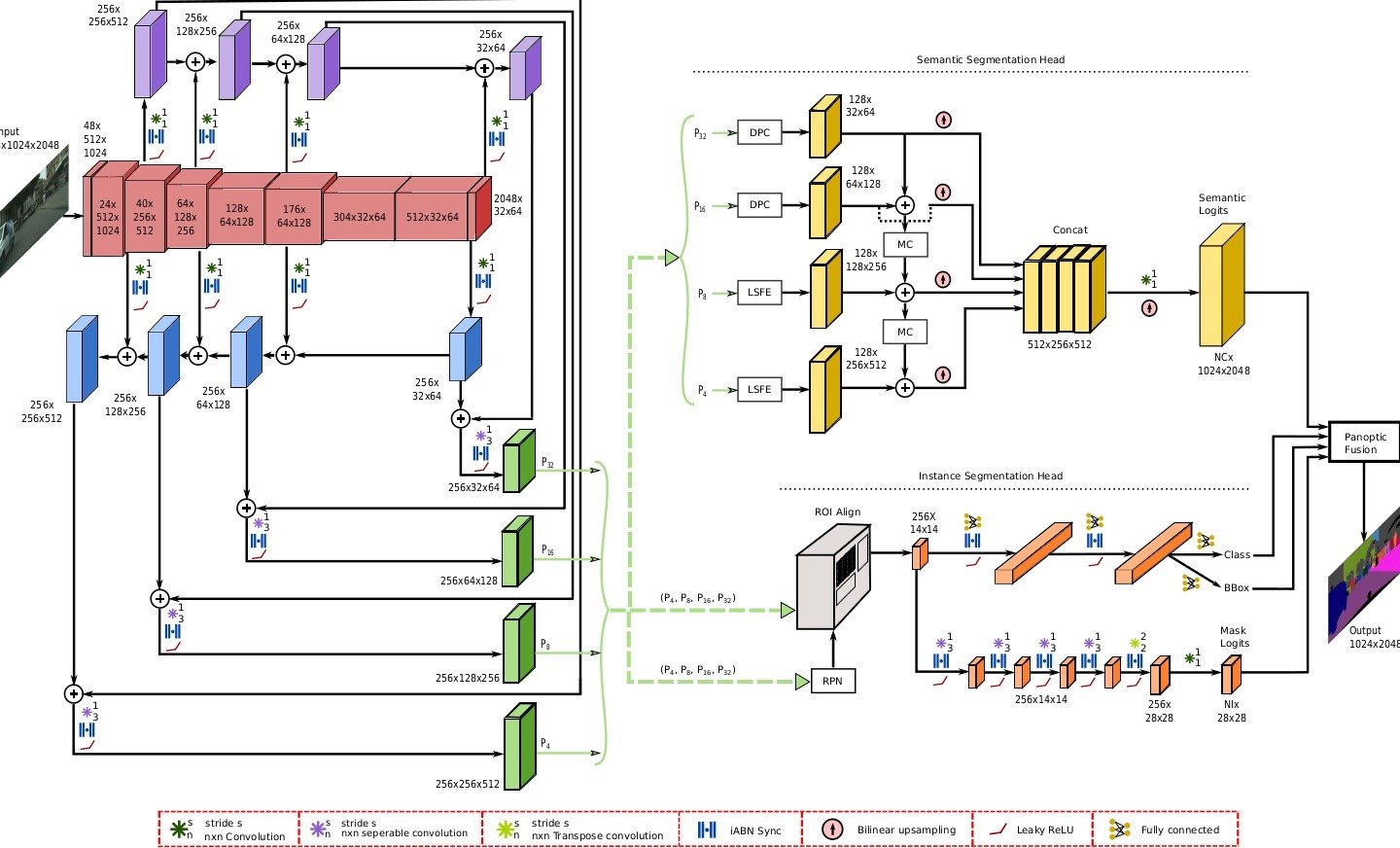
Compared to the traditional approaches, EfficientPS offers several advantages that include improved computational efficiency, better model performance, and consistent predictions across different object categories and types. It can learn useful patterns from the data. All these significances lead to more accurate predictions.
Popular Datasets for Panoptic Segmentation
For training and testing of panoptic segmentation models, we require high-quality datasets that provide ground truth annotations for both “things” and “stuff” categories.
Below are some of the well-known datasets commonly used for panoptic segmentation tasks.
KITTI Panoptic Segmentation Dataset
This dataset is derived from the KITTI autonomous vehicles driving dataset. It includes panoptic segmentation annotations for outdoor scenes captured from the car surveillance camera.
MS COCO Panoptic Segmentation Dataset
It is a large-scale dataset that contains everyday scenes with objects from a wide range of categories. It offers instance segmentation annotations along with detailed object descriptions. This all makes it valuable for model training.
Cityscapes
The Cityscapes dataset focuses on urban street scenes and provides dense pixel-level annotations for panoptic segmentation labels.
Mapillary Vistas
This dataset has street-level imagery captured from vehicles. It provides annotations for objects, lanes, and driving surfaces. This information aids in the development of panoptic segmentation models for navigation and self-driving applications.
Some other public datasets for training panoptic segmentation models may include Pastis, ADE20k, Panoptic Nuscenes, PASCAL VOC, etc.
Applications and Use Cases
Panoptic image segmentation offers a rich set of applications across the following domains:
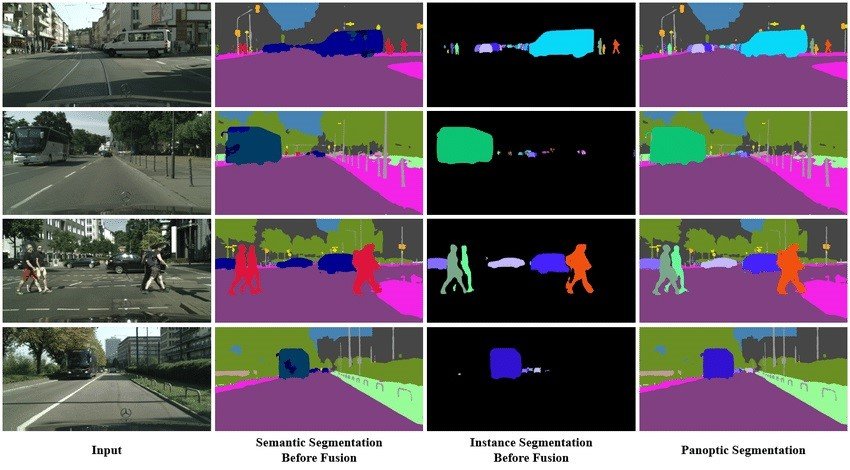
Self-driving cars (Object detection and scene understanding)
This global segmentation technique is crucial for autonomous driving as it helps in accurately detecting objects, and pedestrians, and a detailed understanding of the driving environment.
Robotics (Enhanced perception for manipulation tasks)
Panoptic segmentation enhances robots’ perception abilities to help them better understand and interact with their surroundings. This leads to object manipulation and effective navigation through complex spaces.
Augmented reality (Creating realistic overlays)
By segmenting and understanding the real-world environment, 3D panoptic segmentation enables the creation of realistic augmented reality overlays. This distinction between objects and surfaces enhances the AR experience.
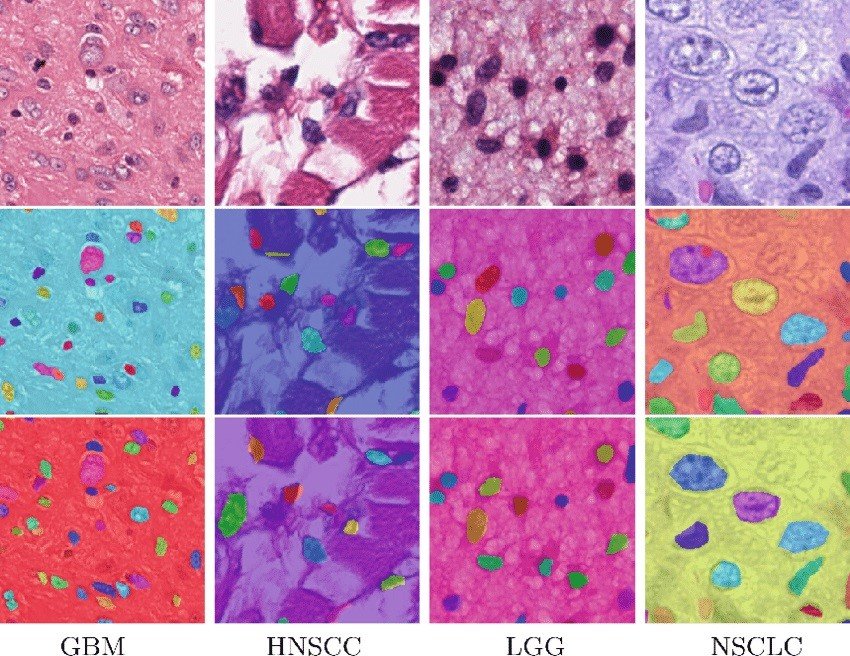
Medical image analysis (Improved segmentation of organs and tissues)
In the medical field, panoptic segmentation helps precisely segment organs, tissues, and anatomical structures. The models typically review images from sources such as CT scans or MRI images. This assists in disease diagnosis, treatment planning, and surgical guidance.
Video understanding (Action recognition and object tracking)
Panoptic segmentation also improves video understanding tasks such as action recognition and object tracking. When objects in video frames are precisely segmented and classified, it simplifies the scene and event analysis process.
Implementation Challenges and Limitations
Panoptic segmentation has seen advancements in recent years, but there are still several challenges to consider.
- Applications like self-driving cars and robotics demand real-time performance for panoptic segmentation. Enhancing efficiency and optimizing models for use on edge devices or embedded systems remains a persistent challenge.
- Real-world settings often present occlusions, clutter, and complex object interaction,s which pose difficulties for segmentation and classification. Extensive research efforts are needed to develop robust segmentation techniques to address these scenarios.
- Models trained or pre-trained on datasets may struggle to generalize across different domains or environments. Enhancing the generalization capabilities of these models and exploring domain adaptation techniques are vital for applicability.
- While most PS approaches concentrate on individual frames, incorporating temporal information from video sequences could potentially enhance the accuracy and consistency of segmentation results over time.
- As models grow in complexity, understanding how to interpret and explain their decisions becomes crucial in safety-critical fields like autonomous driving or medical diagnosis.
- Exploring the fusion of modalities such as RGB images, depth data, or point clouds has the potential to enhance the robustness and accuracy of panoptic segmentation systems across diverse scenarios.
- Exploring weak supervised or unsupervised learning techniques that depend heavily on large-scale, manually annotated datasets can enhance scalability and accessibility.
What’s Next?
Panoptic segmentation is a rapidly developing area with a lot of potential for various AI and ML applications. As research continues to advance, we can expect to see more accurate, efficient, and robust computer vision models. These advanced models might be capable of handling complex real-world problems.
Additionally, the fusion of panoptic segmentation with other cutting-edge technologies like machine learning, computer vision, and robotics will open up avenues for creative solutions and applications across industries.
This is an exciting era for computer vision, with much yet to be discovered in visual comprehension and scene analysis.
If you enjoyed reading this guide and want to dive into related topics, check out the following articles:
- A Complete Guide on How to Perform Image Segmentation Using Deep Learning Techniques
- Explore the Fundamentals of 3D Computer Vision and Its Image Reconstruction Techniques
- Learn about Grounded-SAM and its Applications in Image Segmentation
- An Ultimate Guide to OMG-Seg: A Single CV Model for Various Segmentation Tasks
- An In-Depth Explanation of Object Tracking in Computer Vision
- A Concise Rundown on EfficientNet Technology and Applications