Before diving into Grounded Segment Anything (Grounded-SAM), let’s take a brief refresher on the core technologies that underly it. Grounded Segment Anything combines Grounding DINO’s zero-shot detection capabilities with Segment Anything’s flexible image segmentation. This integration enables detecting and segmenting objects within images using textual prompts.
About Us: We’re the creators of Viso Suite: the end-to-end machine learning infrastructure for enterprises. With Viso Suite, the entire ML pipeline is consolidated into an easy-to-use platform. To learn more, book a demo with the viso.ai team.
The Core Technology Behind Grounded-SAM
Grounding DINO
Grounding DINO is a zero-shot detector, meaning it can recognize and classify objects never seen during training. It uses DINO (Distilled Knowledge from Internet pre-trained mOdels), to interpret free-form text and generate precise bounding boxes and labels for objects within images. Vision Transformers (ViTs) form the backbone of this model. These ViTs are trained on vast, unlabeled image datasets to learn rich visual representations.
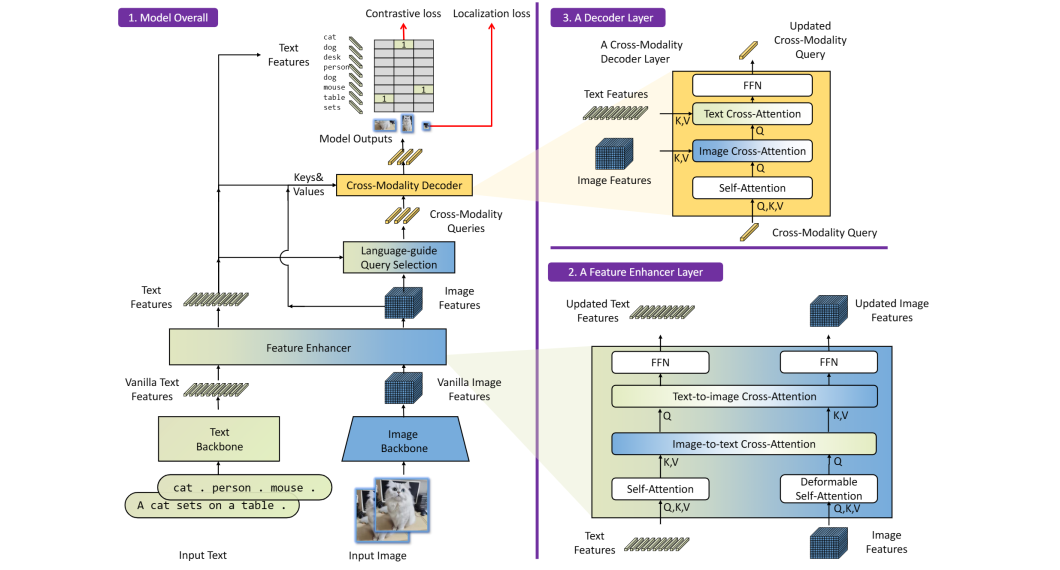
Without prior exposure to specific object classes, Grounding DINO can understand and localize natural language prompts. It recognizes objects with superb generalization using an intuitive understanding of textual descriptions. It thereby effectively bridges the gap between language and visual perception.
Segment Anything Model (SAM)
Segment Anything (SAM) is a foundation model capable of segmenting every discernible entity within an image. On top of textual description, it can also process prompts as bounding boxes or points. Its segmentation mechanism accommodates many objects, regardless of their categories.
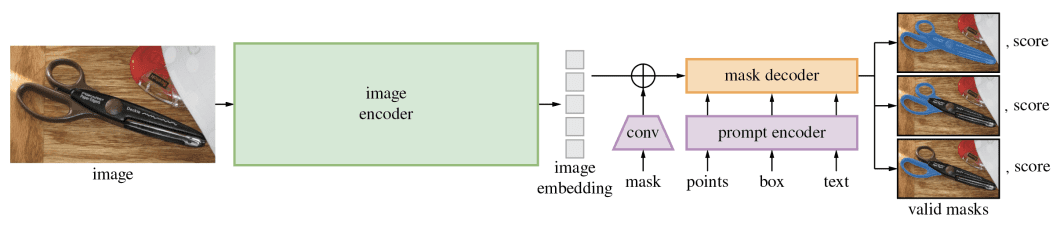
It uses principles of few-shot learning and ViTs to adapt to a versatile range of segmentation tasks. Few-shot machine learning models are designed to understand or infer new tasks and objects from a small amount of training data.
SAM excels in generating detailed masks for objects by interpreting various prompts for fine-grained segmentation across arbitrary categories.
Together, Grounding DINO and Segment Anything enables a more natural, language-driven approach to parsing visual content. The synergy of these two technologies has the potential to offer two-fold benefits:
- Enhance the accuracy of identifying and delineating objects.
- Expand the scope of computer vision applications to include more dynamic and contextually rich environments.
What is Grounded-SAM?
Grounded-SAM aims to refine how models interpret and interact with visual content. This framework combines the strengths of different models to “build a very powerful pipeline for solving complex problems.” They envision a modular framework whereby developers can substitute models with alternatives as they see fit. For example, replacing Grounding DINO with GLIP or Stable-Diffusion with ControlNet or GLIGEN with ChatGPT).
Powered by DistilBERT, Grounding DINO is a distilled version of the BERT model optimized for speed and efficiency. The Grounded-SAM framework is responsible for the first half of the process. It translates linguistic inputs into visual cues with a zero-shot detector that can identify objects from these descriptions. Grounding DINO does this by analyzing the text prompts to predict image labels and bounding boxes.
That’s where SAM comes in. It uses these text-derived cues to create detailed segmentation masks for the identified objects.
It uses a Transformer-based image encoder to process and translate visual input into a series of feature embeddings. These embeddings are processed by a series of convolutional layers. Combined with inputs (points, bounding boxes, or textual descriptions) from a prompt encoder, it generates the various segmentation masks.
The model employs iterative refinement, with each layer refining the mask based on visual features and prompt information. It uses techniques such as Mask R-CNN to fine-tune mask details.
How Does the Model Learn?
SAM learns through a combination of supervised and few-shot learning approaches. It trains on a dataset curated from various sources, including common objects in context (COCO) and Visual Genome. These datasets contain pre-segmented images with rich annotations. A meta-learning framework helps SAM segment new objects with only a handful of annotated examples through pattern recognition.
By integrating the two, Grounding DINO enhances the detection capabilities of SAM. This is especially effective when segmentation models struggle due to the lack of labeled data for certain objects. Grounded-SAM can achieve this by:
- Using Grounding DINO’s zero-shot detection capabilities to provide context and preliminary object localization.
- Using SAM to refine the output into accurate masks.
- Autodistill grounding techniques help the model understand and process complex visual data without extensive supervision.

Grounded SAM achieves a 46.0 mean average precision (mAP) in the “Segmentation in the Wild” competition’s zero-shot track. This surpasses previous models by substantial margins. Potentially, this framework could contribute to AI models that understand and interact with visuals more humanly.
What’s more, it streamlines the creation of training datasets through automatic labeling.
Grounded-SAM Paper and Summary of Benchmarking Results
The open-source Grounded-SAM model paper describes its integration of Grounding DINO and SAM. Referred to as Grounded-SAM, it can detect and segment images without prior training on specific object classes.
The paper evaluates Grounded-SAM’s performance on the challenging ‘Segment in the Wild’ (SIGw) dataset. And, for good measure, compares it to other popular segmentation techniques. The results are promising, with Grounded-SAM variants outperforming existing methods across multiple categories. Grounded-SAM (B+H) scored the highest mAP in many categories, demonstrating its superior ability to generalize.
Here’s a summarized benchmarking table extracted from the paper:
| Method | meanSGinW | Elephants | Airplane-Parts | Fruits | Chicken | Phones |
|---|---|---|---|---|---|---|
| X-Decoder-T | 22.6 | 65.6 | 10.5 | 66.5 | 12.0 | 29.9 |
| X-Decoder-L-IN22K | 26.6 | 63.9 | 12.3 | 79.1 | 3.5 | 43.4 |
| X-Decoder-B | 27.7 | 68.0 | 13.0 | 76.7 | 13.6 | 8.9 |
| X-Decoder-L | 32.2 | 66.0 | 13.1 | 79.2 | 8.6 | 15.6 |
| OpenSeeD-L | 36.7 | 72.9 | 13.0 | 76.4 | 82.9 | 7.6 |
| ODISE-L | 38.7 | 74.9 | 15.8 | 81.3 | 84.1 | 43.8 |
| SAN-CLIP-ViT-L | 41.4 | 67.4 | 13.2 | 77.4 | 69.2 | 10.4 |
| UNINEXT-H | 42.1 | 72.1 | 15.1 | 81.1 | 75.2 | 6.1 |
| Grounded-HQ-SAM(B+H) | 49.6 | 77.5 | 37.6 | 82.3 | 84.5 | 35.3 |
| Grounded-SAM(B+H) | 48.7 | 77.9 | 37.2 | 82.3 | 84.5 | 35.4 |
| Grounded-SAM(L+H) | 46.0 | 78.6 | 38.4 | 86.9 | 84.6 | 3.4 |
The results highlight Grounded-SAM’s superiority in zero-shot detection capabilities and segmentation accuracy. Grounded-SAM (B+H) does particularly well, with an overall mAP of 48.7. However, all Grounded-SAM-based models performed well, with an average score of 48.1 compared to 33.5 for the rest.
The only category in which Grounded-SAM models lagged significantly behind others was phone segmentation. You can review the paper for a complete set of results.
In conclusion, Grounded-SAM, demonstrates a significant advancement in the field of AI-driven image annotation.
Practical Guide on How to Use Grounded Segment Anything and Integrate with Various Platforms/Frameworks
The researchers behind Grounded-SAM encourage other developers to create interesting demos based on the foundation they provided. Or, to develop other new and interesting projects based on Segment-Anything. Consequently, it offers support for a range of platforms and other computer vision models, extending its versatility.
Here is a quick, practical guide on how you can get started experimenting with Grounded-SAM:
Setting Up Grounded Segment Anything Step-by-Step:
- Environment Preparation:
- Ensure Python 3.8+ is installed.
- Set up a virtual environment (optional but recommended).
- Install PyTorch 1.7+ with compatible CUDA support for GPU acceleration.
- Installation:
- Clone the GSA repository:
git clone [GSA-repo-url]. - Navigate to the cloned directory:
cd [GSA-repo-directory]. - Install GSA:
pip install -r requirements.txt.
- Clone the GSA repository:
- Configuration:
- Download the pre-trained models and place them in the specified directory.
- Modify the configuration files to match your local setup. Remember to specify paths to models and data.
- Execution:
- Run the GSA script with appropriate flags for your task:
python run_gsa.py --input [input-path] --output [output-path]. - Utilize provided Jupyter notebooks for interactive usage and experimentation.
- Run the GSA script with appropriate flags for your task:
Integration with Other Platforms/Frameworks
Here’s a list of various platforms, frameworks, and components that you can integrate with Grounded-SAM:
- OSX: Integrated as a one-stage motion capture method that generates high-quality 3D human meshes from monocular images. Utilizes the UBody dataset for enhanced upper-body reconstruction accuracy.
- Stable-Diffusion: A top latent text-to-image diffusion model to augment the creation and refinement of visual content.
- RAM: Employed for its image tagging abilities, capable of accurately identifying common categories across various contexts.
- RAM++: The next iteration of the RAM model. It recognizes a vast array of categories with heightened precision and is part of the project object recognition module.
- BLIP: A language-vision model that enhances the understanding of images.
- Visual ChatGPT: Serves as a bridge between ChatGPT and visual models for image sending and receiving during conversations.
- Tag2Text: Provides both advanced image captioning and tagging, supporting the need for descriptive and accurate image annotations.
- VoxelNeXt: Fully sparse 3D object detector predicting objects directly from sparse voxel features.
We encourage checking out the GitHub repo for full guidance on these technologies, such as the Gradio APP, Whisper, VISAM, etc.
Use Cases, Applications, Challenges, and Future Directions
GSA could make a difference in various sectors with its advanced visual and image recognition capabilities. Surveillance, for example, has the potential to improve monitoring and threat detection. In healthcare, GSA’s precision in analyzing medical images aids in early diagnosis and treatment planning. In the paper’s benchmarking tests, GSA-based models achieved the first and second-highest scores for segmenting brain tumors.
GSA’s implementation across these fields not only elevates product features but also promotes innovation by tackling complex visual recognition challenges. Yet, its deployment faces obstacles like high computational requirements, the need for vast, diverse datasets, and ensuring consistent performance across different contexts.
Looking ahead, GSA’s trajectory includes refining its zero-shot learning capabilities to better handle unseen objects and scenarios. Also, broadening the model’s ability to handle low-resource settings and languages will make it more accessible. Future integrations may include augmented and virtual reality platforms, opening new possibilities for interactive experiences.
Implementing Computer Vision for Business
Viso Suite is the end-to-end computer vision infrastructure for organizations to build, deploy, manage, and scale their applications. A key advantage of Viso Suite is its flexibility, meaning that it easily adapts and scales with evolving business needs.
Additionally, because Viso Suite consolidates the entire ML pipeline, teams no longer need to rely on point solutions to fill in the gaps. Viso Suite handles everything from data collection to application management to security. By using a single infrastructure, organizations can experience an implementation time-to-value of just 3 days. To learn more, read our Viso Suite economic impact study.
For organizations looking to integrate computer vision into their business flows, we offer custom demos of Viso Suite. Be sure to book a demo with our team of experts.
