
Image segmentation is one of the key applications in the Computer Vision domain. This article aims to provide an easy-to-understand overview of image segmentation and instance segmentation. In particular, you will learn about the following:
- What is Image Segmentation?
- The meaning of Instance Segmentation
- What are popular applications?
- Semantic vs. Instance Segmentation
- Most popular image segmentation datasets
What is Image Segmentation?
One of the most important operations in Computer Vision is Segmentation. Image segmentation is the process of dividing an image into multiple parts or regions that belong to the same class. This task of clustering is based on specific criteria, for example, color or texture.
This process is also called pixel-level classification. In other words, it involves partitioning images (or video frames) into multiple segments or objects.
In the last 40 years, various segmentation methods have been proposed, ranging from MATLAB image segmentation and traditional computer vision methods to state-of-the-art deep learning methods. Especially with the emergence of Deep Neural Networks (DNN), image segmentation applications have made tremendous progress.

Image Segmentation Techniques
There are various image segmentation techniques available, and each technique has its advantages and disadvantages.
- Thresholding: Thresholding is one of the simplest image segmentation techniques, where a threshold value is set, and all pixels with intensity values above or below the threshold are assigned to separate regions.
- Region growing: In region growing, the image is divided into several regions based on similarity criteria. This segmentation technique starts from a seed point and grows the region by adding neighboring pixels with similar characteristics.
- Edge-based segmentation: Edge-based segmentation techniques are based on detecting edges in the image. These edges represent boundaries between different regions and are detected using edge detection algorithms.
- Clustering: Clustering techniques group pixels into clusters based on similarity criteria. These criteria can be color, intensity, texture, or any other feature.
- Watershed segmentation: Watershed segmentation is based on the idea of flooding an image from its minima. In this technique, the image is treated as a topographic relief, where the intensity values represent the height of the terrain.
- Active contours: Active contours, also known as snakes, are curves that deform to find the boundary of an object in an image. These curves are controlled by an energy function that minimizes the distance between the curve and the object boundary.
- Deep learning-based segmentation: Deep learning techniques, such as Convolutional Neural Networks (CNNs), have revolutionized image segmentation by providing highly accurate and efficient solutions. These techniques use a hierarchical approach to image processing, where multiple layers of filters are applied to the input image to extract high-level features. Read more about the basics of a Convolutional Neural Network.
- Graph-based segmentation: This technique represents an image as a graph and partitions the image based on graph theory principles.
- Superpixel-based segmentation: This technique groups a set of similar image pixels to form larger, more meaningful regions, called superpixels.

Applications of Image Segmentation
Image segmentation problems play a central role in a broad range of real-world computer vision applications, including road sign detection, biology, the evaluation of construction materials, or video security and surveillance. Also, self-driving cars and Advanced Driver Assistance Systems (ADAS) need to detect navigable surfaces or apply pedestrian detection.

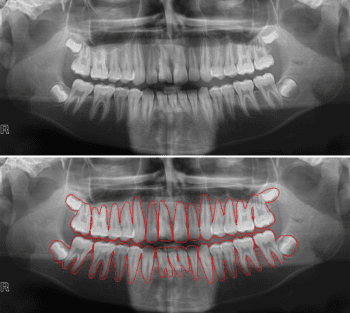
Furthermore, image segmentation is widely applied in medical imaging applications, such as tumor boundary extraction or measurement of tissue volumes. Here, an opportunity is to design standardized image databases that can be used to evaluate fast-spreading new diseases and pandemics.
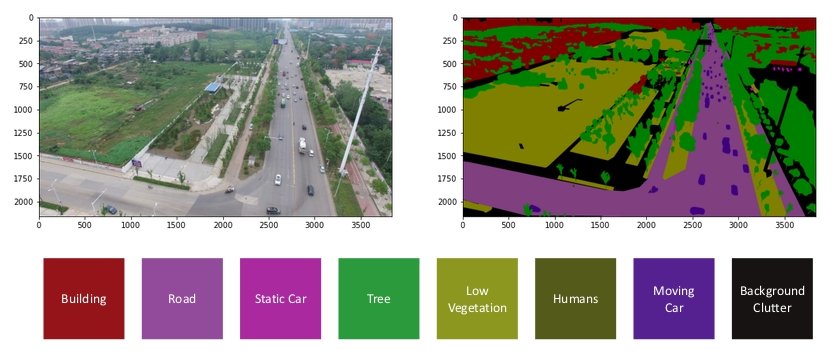
Deep Learning-based Image Segmentation has been successfully applied to segment satellite images in the field of remote sensing, including techniques for urban planning or precision agriculture. Also, images collected by drones (UAVs) have been segmented using Deep Learning techniques, offering the opportunity to address important environmental problems related to climate change.
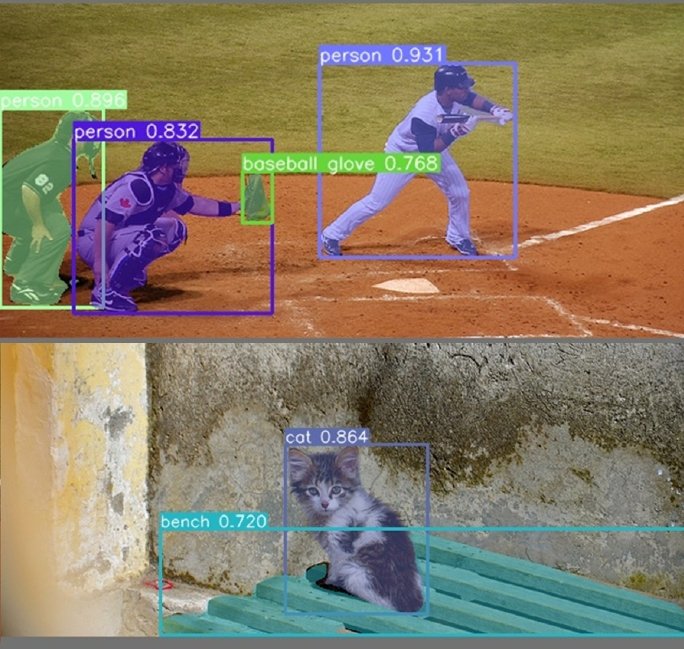
Semantic vs. Instance Image Segmentation
Image segmentation can be formulated as a classification problem of pixels with semantic labels (semantic segmentation) or partitioning of individual objects (instance segmentation). Semantic segmentation performs pixel-level class labeling with a set of object categories (for example, people, trees, sky, cars) for all image pixels.
It is generally a more difficult undertaking than image classification, which predicts a single label for the entire image or frame. Instance segmentation extends the scope of semantic segmentation further by detecting and delineating all the objects of interest in an image.
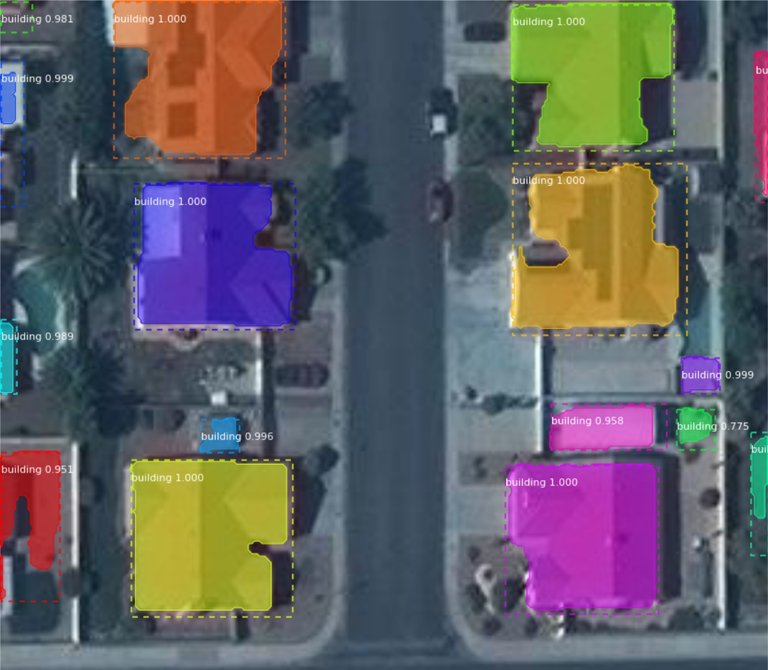
Image Segmentation and Deep Learning
Multiple image segmentation algorithms have been developed. Earlier methods include thresholding, histogram-based bundling, region growing, k-means clustering, or watersheds. However, more advanced algorithms are based on active contours, graph cuts, conditional and Markov random fields, and sparsity-based methods.
Over the last few years, Deep Learning models have introduced a new segment of image segmentation models with remarkable performance improvements. Deep Learning based image segmentation models often achieve the best accuracy rates on popular benchmarks, resulting in a paradigm shift in the field.

Most Popular Image Segmentation Datasets
Due to the success of deep learning models in a wide range of vision applications, there has been a substantial amount of research aimed at developing image segmentation approaches using deep learning. At present, there are many general datasets related to image segmentation. The most popular image segmentation datasets are:
PASCAL VOC
The PASCAL Visual Object Classes (VOC) Challenge provides publicly available image datasets and annotations. The PASCAL VOC is one of the most popular datasets in computer vision, with annotated images available for 5 tasks: classification, segmentation, detection, action recognition, and person layout. A high number of popular segmentation algorithms have been evaluated on this dataset.
For segmentation tasks, the PASCAL VOS supports 21 classes of object labels: vehicles, households, animals, airplanes, bicycle, boat, bus, car, motorbike, train, bottle, chair, dining table, potted plant, sofa, TV/monitor, bird, cat, cow, dog, horse, sheep, and person.
Pixels in the image are labeled as “background” if they do not belong to any of these classes. The training/validation data of the PASCAL VOC has 11’530 images containing 27’450 ROI annotated objects and 6’929 segmentations.
MS COCO
The Microsoft Common Objects in Context (MS COCO) is a large-scale object detection, segmentation, and captioning dataset. COCO includes images of complex everyday scenes containing common objects in their natural contexts.
Therefore, COCO is based on a total of 2.5 million labeled segmented instances in 328k images, containing photos of 91 object types that would be recognized easily by a 4-year-old person. For more information about COCO, check out our article What is the COCO Dataset? What you need to know.

Cityscapes
The large-scale database focuses on the semantic understanding of urban street scenes. It contains a diverse set of stereo video sequences recorded in street scenes from 50 cities, 5’000 fully annotated images, and a set of 20’000 weakly annotated frames.
Also, the collection time spans several months, which covers the seasons of spring, summer, and fall. Cityscapes include semantic and dense pixel annotations of 30 classes, grouped into 8 categories (flat surfaces, humans, vehicles, constructions, objects, nature, sky, and void). The dataset is especially important for autonomous driving applications.
ADE20K
ADE20K offers a standard training and evaluation platform for scene parsing algorithms. The ADE20K dataset contains over 20’000 scene-centric images annotated with objects and object parts, and it provides 150 semantic categories.
Unlike other datasets, ADE20K includes an object segmentation mask and a parts segmentation mask. There are 20’210 color images in the training set, 2’000 images in the validation set, and 3’000 images in the testing set.
YouTube-Objects
The YouTube-Objects Dataset is composed of videos collected from YouTube by querying for the names of 10 object classes. In particular, it includes objects from the 10 PASCAL VOC classes: airplane, bird, boat, car, cat, cow, dog, horse, motorbike, and train.
The original dataset was developed for object detection with weak annotations and did not contain pixel-wise annotations. Therefore, a fully annotated YouTube Video Object Segmentation dataset (YouTube-VOS) was released, containing 4’453 YouTube video clips and 94 object categories.
KITTI
The KITTI dataset is one of the most popular datasets for mobile robotics and autonomous driving. It contains hours of videos of traffic scenarios captured by driving around the mid-sized city of Karlsruhe (on highways and in rural areas). On average, in every image, up to 15 cars and 30 pedestrians are visible.
The main tasks of this dataset are road detection, stereo reconstruction, optical flow, visual odometry, 3D object detection, and 3D tracking. The original dataset does not contain ground truth for semantic segmentation, but researchers have manually annotated parts of the dataset.
OMG-Seg
OMG-Seg is a framework proposed by Li et. al. in 2024 that provides 10 segmentation tasks in one model. The tasks include image, video, open-vocabulary segmentation, and more.
Other Datasets
There are multiple other datasets available for image segmentation purposes, such as the SUN database (16’873 fully annotated images), Shadow detection/Texture segmentation vision dataset, Berkeley segmentation dataset, the Semantic Boundaries Dataset (SBD), PASCAL Part, SYNTHIA, Adobe’s Portrait Segmentation or the LabelMe images database.
What’s Next for Image Segmentation?
In past years, image and instance segmentation methods have made great progress. Hence, image segmentation accelerates the development of real-world applications across industries, including tumor detection, material detection on construction sites, and, most prominently, autonomous driving.
If you enjoyed reading this article, we recommend the following:
- Everything you need to know about Image Annotation
- Read about Object Detection or Face Detection
- Learn about the real-time object detection algorithms YOLOv3 or YOLOv8
- Our guide about OID vs. COCO – differences and similarities
- Machine learning techniques like Active Learning or Unsupervised Learning
- Grounded SAM for segmentation with textual prompts
- An In-Depth Guide to Federated Learning