
Computer vision models enable the machine to extract, analyze, and recognize useful information from a set of images. Lightweight computer vision models allow users to deploy them on mobile and edge devices.
Today’s boom in CV started with the implementation of deep learning models and convolutional neural networks (CNN). The main CV methods include image classification, image localization, detection, and segmentation.
This article lists the most significant lightweight computer vision models SMEs can efficiently implement in their daily tasks. We’ve split the lightweight models into four different categories: face recognition, healthcare, traffic, and general-purpose machine learning models.
Lightweight Models for Face Recognition
DeepFace – Lightweight Face Recognition Analyzing Facial Attributes
DeepFace AI is a lightweight face recognition and facial attribute library. The open-source DeepFace library includes all modern AI models for modern face recognition. Therefore, it can handle all procedures for facial recognition in the background.
DeepFace is an open-source project written in Python and licensed under the MIT License. You can install DeepFace from its GitHub library, published in the Python Package Index (PyPI).

DeepFace features include:
- Face Recognition: This task finds a face in an image database. Therefore, to do face recognition, the algorithm often runs face verification.
- Face Verification: Users apply this to compare a candidate’s face to another. Also, to confirm that a physical face matches the one in an ID document.
- Facial Attribute Analysis: describes the visual properties of face images. Accordingly, users apply it to extract attributes such as age, gender, emotions, etc.
- Real-Time Face Analysis: utilizes the real-time video feed of your webcam.
MobileFaceNets (MFN) – CNNs for Real-Time Face Verification
Chen et al. (2018) published their research titled MobileFaceNets. Their model is an efficient CNN for Accurate Real-Time Face Verification on Mobile Devices. They used less than 1 million parameters. They adapted the model for high-accuracy real-time face verification on mobile and embedded devices.
Also, they analyzed the weakness of previous mobile networks for face verification. They trained it by ArcFace loss on the refined MS-Celeb-1M. MFN of 4.0MB size achieved 99.55% accuracy on LFW.
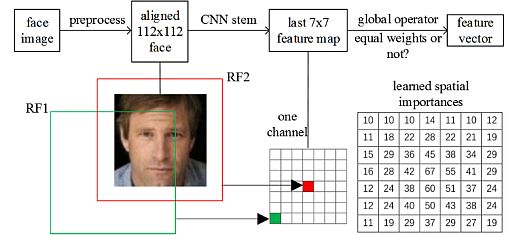
Model characteristics:
- All convolutional layers in the same sequence have the same number c of output channels. The first layer of each sequence has a stride S, and all others use a stride of 1.
- All spatial convolutions in the bottlenecks use 3 × 3 kernels. Hence, the researchers applied the expansion factor t to the input batch.
- MFN provides improved efficiency over previous state-of-the-art mobile CNNs for face verification.
EdgeFace – Face Recognition Model for Edge Devices
Researchers A. George, C. Ecabert, et al. (2015) published a paper called EdgeFace or Efficient Face Recognition Model. This paper introduced EdgeFace, a lightweight and efficient face recognition network inspired by the hybrid architecture of EdgeNeXt. Thus, EdgeFace achieved excellent face recognition performance optimized for edge devices.
The proposed EdgeFace network had low computational costs and required fewer computational resources and compact storage. Also, it achieved high face recognition accuracy, making it suitable for deployment on edge devices. The EdgeFace model was top-ranked among models with fewer than 2M parameters in the IJCB 2023 Face Recognition Competition.
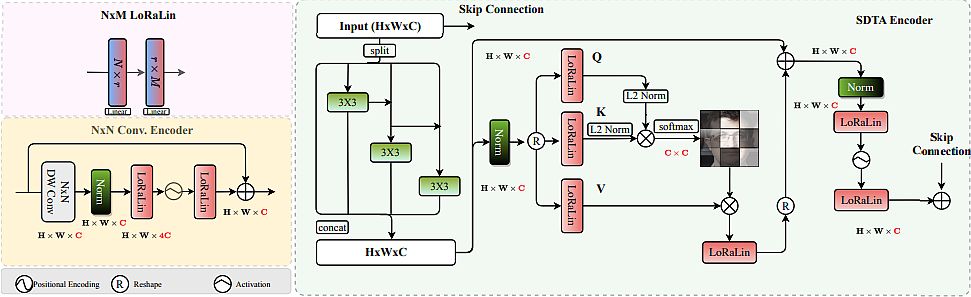
Model Characteristics:
- Leveraged efficient hybrid architecture and LoRaLin layers, thus achieving remarkable performance while maintaining low computational complexity.
- Demonstrated efficiency on various face recognition benchmarks, including LFW and AgeDB-30
- EdgeFace offers an efficient and highly accurate face recognition model suitable for edge (mobile) devices.
Healthcare CV Models
MedViT: A Robust Vision Transformer for Medical Image Recognition
Manzari et al. (2023) published the research MedViT – A Robust Vision Transformer for Generalized Medical Image Recognition. They proposed a robust yet efficient CNN-Transformer hybrid model equipped with CNNs and global integration of vision Transformers.
The authors performed data augmentation on image shape information by permuting the feature mean and variance within mini-batches. In addition to its low complexity, their hybrid model demonstrated its high robustness. Researchers compared it to the other approaches that utilize the MedMNIST-2D dataset.
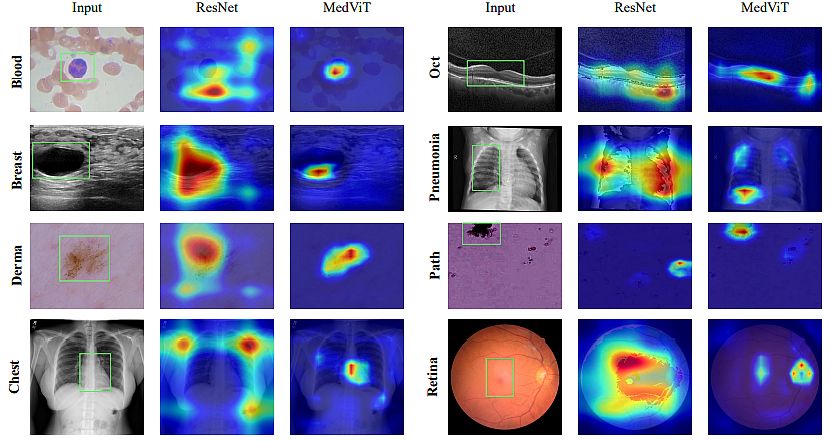
Model characteristics:
- They trained all MedViT variants for 100 epochs on NVIDIA 2080 Ti GPUs. Also, they utilized a batch size of 128 as a training dataset sample.
- They used an AdamW optimizer with a learning rate of 0.001, thus reducing it by a factor of 0.1.
- MedViT-S showed superior learning ability on both evaluation metrics. Subsequently, it achieved an increase of 2.3% (AUC) in RetinaMNIST.
MaxCerVixT: A Lightweight Transformer-based Cancer Detection
Pacal (2024) introduced an advanced framework (architecture), the Multi-Axis Vision Transformer (MaxViT). He addressed the challenges in Pap test accuracy. Pacal conducted a large-scale study with a total of 106 deep learning models. In addition, he utilized 53 CNN-based and 53 vision transformer-based models for each dataset.
He substituted MBConv blocks in the MaxViT architecture with ConvNeXtv2 blocks and MLP blocks with GRN-based MLPs. That change reduced parameter counts and also enhanced the model’s recognition capabilities. In addition, he evaluated the proposed method using the publicly available SIPaKMeD and Mendeley LBC Pap smear datasets.
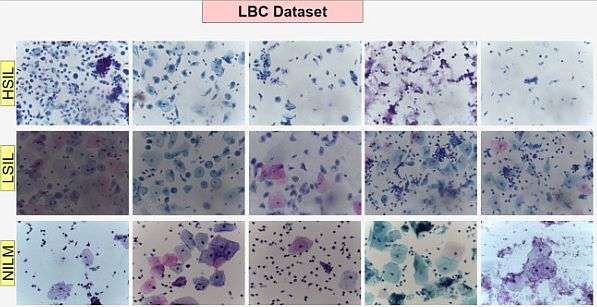
Model characteristics:
- In comparison with experimental and state-of-the-art methods, the proposed method demonstrated superior accuracy.
- Also, when compared with multiple CNN-based models, the method achieved a faster inference speed (6 ms).
- It surpassed all existing deep learning models, thus achieving 99.02% accuracy on the SIPaKMeD dataset. Also, the model achieved 99.48% accuracy on the LBC dataset.
Lightweight CNN Architecture for Anomaly Detection in E-Health
Yatbaz et al. (2021) published their research Anomaly Detection in E-Health Applications Using Lightweight CNN Architecture. The authors used ECG data for the prediction of cardiac stress activities. Moreover, they tested the proposed deep learning model on the MHEALTH dataset with two different validation techniques.
The experimental results showed that the model achieved up to 97.06% accuracy for the cardiac stress level. In addition, the model for ECG prediction was lighter than the existing approaches with sizes of 1.97 MB.
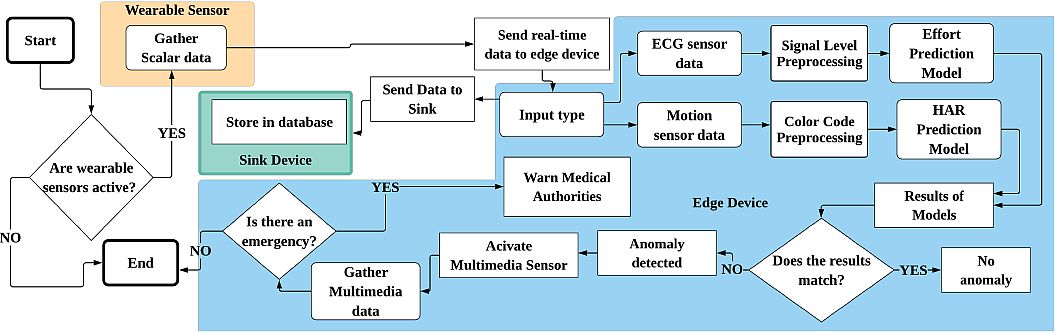
Model characteristics:
- For color code generation, researchers extracted each sensory input within each windowing activity. They tested their deep learning model on the M-Health dataset.
- For ECG data, they applied a mapping algorithm from activities to effort levels and a lightweight CNN architecture.
- Regarding complexity, the ECG-based model had parameters of 1.0410 GFLOPS and a model size of 1.97 MB.
Traffic / Vehicles Recognition Models
Lightweight Vehicles Detection Network model based on YOLOv5
Wang et al. (2024) published their research Lightweight Vehicle Detection Based on Improved YOLOv5. They applied integrated perceptual attention, with few parameters and high detection accuracy.
They proposed a lightweight module, IPA, with a Transformer encoder based on integrated perceptual attention. In addition, they achieved a reduction in the number of parameters while capturing global dependencies for richer contextual information.

Model characteristics:
- A lightweight and efficient Multiscale Spatial Reconstruction module (MSCCR) with low parameters and computational complexity for feature learning.
- It includes the IPA module and the MSCCR module in the YOLOv5s backbone network. Thus, it reduces model parameters and improves accuracy.
- The test results showed that the model parameters decreased by about 9%, and accuracy increased by 3.1%. Moreover, the FLOPS score did not increase with the parameter number.
A Lightweight Vehicle-Pedestrian Detection Based on Attention
Zhang et al. (2022) published their research Lightweight Vehicle-Pedestrian Detection Algorithm Based on Attention Mechanism in Traffic Scenarios. They proposed an improved lightweight and high-performance vehicle-pedestrian detection algorithm based on YOLOv4.
To reduce parameters and improve feature extraction, they replaced the backbone network CSPDarknet53 with MobileNetv2. Also, they used the method of multi-scale feature fusion to realize the information interaction among different feature layers.
Model characteristics:
- It contains a coordinate attention mechanism to focus on the region of interest in the image by weight adjustment.
- The experimental results showed that this improved model has a great performance in vehicle-pedestrian detection in traffic scenarios.
- Therefore, the improved YOLOv4 model maintains a great balance between detection accuracy and speed on different datasets. It surpassed the other tiny models for vehicle detection.
Smart Lightweight Visual Attention Model for Fine-Grained Vehicle Recognition
Boukerche et al. (2023) published “Smart Lightweight Visual Attention Model for Fine-Grained Vehicle Recognition.” Their LRAU (Lightweight Recurrent Attention Unit) extracted the discriminative features to locate the key points of a vehicle.
They generated the attention mask using the feature maps received by the LRAU and its preceding attention state. Moreover, by utilizing the standard CNN architecture they received the multi-scale feature maps.
Model characteristics:
- It underwent comprehensive experiments on three challenging VMMR datasets to evaluate the proposed VMMR models.
- Experimental results show their deep learning models have a stable performance under different conditions.
- The models achieved state-of-the-art results with 93.94% accuracy on the Stanford Cars dataset. Moreover, they achieved 98.31% accuracy on the CompCars dataset.
General Purpose Lightweight CV Models
MobileViT: Lightweight, General-purpose Vision Transformer
Mehta et al. (2022) published their research, MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. They combined the strengths of CNNs and ViTs to build a lightweight and low-latency network for mobile vision tasks.
They introduced MobileViT, a lightweight and general-purpose vision transformer for mobile devices. MobileViT provides a different perspective for the global processing of information with transformers, i.e., transformers as convolutions.
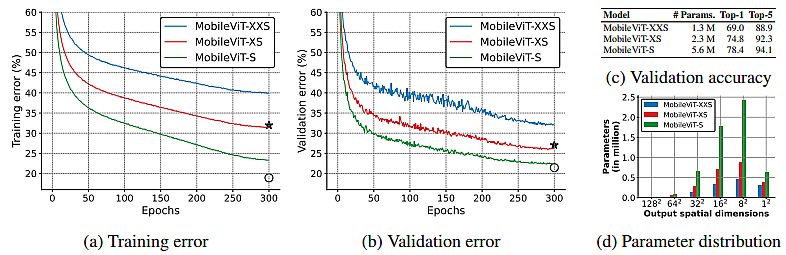
Model characteristics:
- Results showed that MobileViT significantly outperforms CNN- and ViT-based networks across different tasks and training data sets.
- On the ImageNet-1k dataset, MobileViT achieved top-1 accuracy of 78.4% with about 6 million parameters. The lightweight model is 6.2% more accurate than MobileNetv3 (CNN-based).
- On the MS-COCO real-time object detection task, MobileViT is 5.7% more accurate than MobileNetv3. Also, it performed faster for a similar number of parameters.
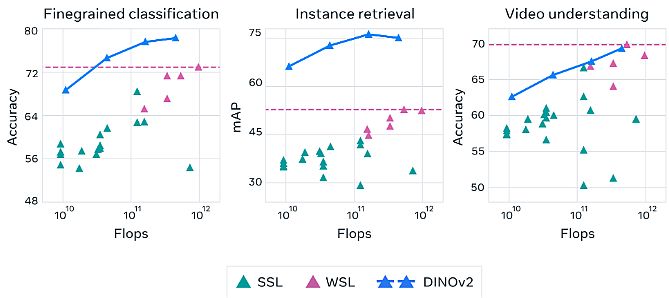
DINOv2: Learning Robust Visual Features without Supervision
In April 2023, Meta published their DINOv2: State-of-the-art computer vision pre-trained models with self-supervised learning. DINOv2 provides high-performance features, along with simple linear classifiers. Therefore, users utilize DINOv2 to create multipurpose backbones for many different computer vision tasks.
- Regarding data, the authors proposed an automatic pipeline to build a dedicated, diverse, and curated image dataset.
- They trained a ViT model with 1B parameters and distilled it into a series of smaller/tiny models.
- It surpassed the best available general-purpose features, OpenCLIP, on most of the benchmarks at the image and pixel levels.
- DINOv2 delivers strong performance and does not require fine-tuning. Thus, it is suitable for use as a backbone for many different computer vision tasks.
Viso Suite: End-to-End Computer Vision Platform
Viso Suite is an end-to-end computer vision platform. Businesses use it to build, deploy, and monitor real-world computer vision applications. Also, Viso is an end-to-end infrastructure utilizing state-of-the-art CV models – OpenCV, Tensor Flow, and PyTorch.
- It includes over 15 products in one solution, including image annotation, model training, and application development. Also, it provides device management, IoT communication, and custom dashboards.
- The model-driven architecture provides a robust and secure infrastructure to build computer vision pipelines with building blocks.
- High flexibility provides the addition of custom code or integration with Tableau, Power BI, SAP, or external databases (AWS-S3, MongoDB, etc.).
- Enterprises use Viso Suite to build and operate state-of-the-art CV applications. Subsequently, we have clients in industry, visual inspection, remote monitoring, etc.
What’s Next?
Lightweight computer vision systems are useful on mobile and edge devices since they require low processing and storage resources. Hence, they are essential in many business applications. The Viso Suite platform offers firms comprehensive tools for building, deploying, and managing CV apps on different devices. The lightweight pre-trained models are applicable in multiple industries. We provide computer vision models on the edge, where events and activities happen.
To learn more about the world of machine learning and computer vision, check out our other blogs:
- Complete Guide to Feature Extraction in Python
- Concept Drift vs Data Drift: How AI Can Beat the Change
- Multispectral Imaging: Looking Beyond the Visible Light
- Gradient Descent in Computer Vision
- MLflow: Simplifying Machine Learning Experimentation
- ONNX Explained: A New Paradigm in AI Interoperability