In this article, we dive into the most popular computer vision tasks being used across industries and sectors today.
Computer vision (CV) is a rapidly evolving area in artificial intelligence (AI), allowing machines to process complex real-world visual data in different domains like healthcare, transportation, agriculture, and manufacturing. Modern computer vision research is producing novel algorithms for various applications, such as facial recognition, autonomous driving, annotated surgical videos, etc.
State of Computer Vision Tasks
The field of computer vision today involves advanced AI algorithms and architectures, such as convolutional neural networks (CNNs) and vision transformers (ViTs), to process, analyze, and extract relevant patterns from visual data.
- Generative AI: Architectures like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) are giving rise to generative models that can synthesize new images based on input data distributions. The technology can help you solve data annotation issues and augment data samples for better model training.
- Edge Computing: With the growth in data volume, processing visual data at the edge has become a crucial concept for the adoption of computer vision. Edge AI involves processing data near the source. Therefore, edge devices like servers or computers are connected to cameras and run AI models in real-time applications.
- Real-Time Computer Vision: With the help of advanced AI hardware, computer vision solutions can analyze real-time video feeds to provide critical insights. The most common example is security analytics, where deep learning models analyze CCTV footage to detect theft, traffic violations, or intrusions in real-time.
- Augmented Reality: As Meta and Apple enter the augmented reality space, the role of CV models in understanding physical environments will witness breakthrough progress, allowing users to blend the digital world with their surroundings.
- 3D Imaging: Advancements in CV modeling are helping experts analyze 3D images by accurately capturing depth and distance information. For instance, CV algorithms can understand Light Detection and Ranging (LIDAR) data for enhanced perceptions of the environment.
- Few-Shot vs. Zero-Shot Learning: Few-shot and zero-shot learning paradigms are revolutionizing machine learning (ML) development by allowing you to train CV models using only a few to no labeled samples.
Image Classification
Image classification tasks involve CV models categorizing images into user-defined classes for various applications. For example, a classification model will classify the image below as a tiger.

The list below mentions some of the best image classification models:
BLIP
Bootstrapping Language-Image Pre-training (BLIP) is a vision-language model that allows you to caption images, retrieve images, and perform visual-question answering (VQA).
The model achieves state-of-the-art (SOTA) results using a filter that removes noisy data from synthetic captions.
The underlying architecture involves an encoder-decoder architecture that uses a bootstrapping method to filter out noisy captions.
ResNet
Residual Neural Networks (ResNets) use the CNN architecture to learn complex visual patterns. The most significant benefit of using ResNets is that they allow you to build dense, deep learning networks without causing vanishing gradient problems.
Usually, deep neural networks with several layers fail to update the weights of the initial layers. This is the result of very small gradients during backpropagation. ResNets circumvent this issue by skipping a few layers and learning a residual function during training.
VGGNet
Very Deep Convolutional Networks, also called VGGNet, is a type of CNN-based model. VGGNet uses 3×3 filters to extract fundamental features from image data.
The model secured first and second positions in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2014.
Real-Life Applications of Classification
The classification models allow you to use CV systems in various domains, including:
- Computer vision in logistics and inventory management is used to classify inventory items for detailed analysis.
- Computer vision in healthcare is used to classify medical images, such as X-rays and CT scans, for disease diagnosis.
- Computer vision in manufacturing is used to detect defective products for quality control.

Object Detection and Localization
While image classification categorizes an entire image, object detection and localization identify specific objects within an image.
For example, CV models can detect multiple objects, such as a chair and a table, in a single image. This is done by drawing bounding boxes or polygons around the object of interest.

Popular object detection models include:
Faster R-CNN
Faster R-CNN is a deep learning algorithm that follows a two-stage architecture. For stage one, the model uses Region Proposal Networks (RPN) based on convolutional layers to identify relevant object regions for classification.
In the second stage, Fast R-CNN uses the region proposals for detecting objects. In addition, the RPN and Fast R-CNN components form a single network using the novel attention mechanism that allows the model to pay attention to essential regions for detection.
YOLO v7
You Only Look Once (YOLO) is a popular object-detection algorithm that uses a deep convolutional network to detect objects in a single go. Unlike Faster R-CNN, it can analyze and predict object locations without needing proposal regions.
YOLOv7 is a recent iteration of the YOLO network. This iteration improves upon all the previous versions by giving higher accuracy and faster results. The machine learning model is beneficial in real-time applications where you want instant results.

To learn more about other object detector models in the YOLO series, check out our other articles on YOLOv3, YOLOv5, YOLOv8, and YOLOv9.
SSD
The Single-Shot Detector (SSD) model breaks down bounding boxes from ground-truth images into several default boxes with different aspect ratios. The boxes appear in multiple locations of a feature map having different scales.
The architecture allows for more accessible training and integration with object detection systems at scale.

Real-Life Applications of Object Detection
Real-world applications for object detection include:
- Autonomous driving where the vehicle must identify different objects on the road for navigation.
- Inventory management on shelves and in retail outlets to detect shortages.
- Anomaly detection and threat identification in surveillance using detection and localization CV models.
Semantic Segmentation
Semantic segmentation aims to identify each pixel within an image for a more detailed categorization. The method produces more precise classification by assigning a label to an object’s individual pixels.

Common semantic segmentation models include:
FastFCN
Fast Fully Convolutional Network (FastFCN) improves upon the previous FCN architecture for semantic segmentation. This is done by introducing a Joint Pyramid Upsampling (JPU) method that reduces the computation cost of extracting feature maps.
DeepLab
The DeepLab system overcomes the challenges of traditional deep convolutional networks (DCNNs). These DCNNs have lower feature resolutions, an inability to capture objects at multiple scales, and inferior localization accuracy.
DeepLab addresses them through atrous convolutions, Atrous Spatial Pyramid Pooling (ASPP), and Conditional Random Fields (CRF).
U-Net
The primary purpose of the U-Net architecture was to segment biomedical images, which requires high localization accuracy. Also, the lack of annotated data samples is a significant challenge that prevents you from effective model training.
U-Net solves these problems by modifying the FCN architecture through upsampling operators that increase image resolution and combine the upsampled output with high-resolution features for better localization.
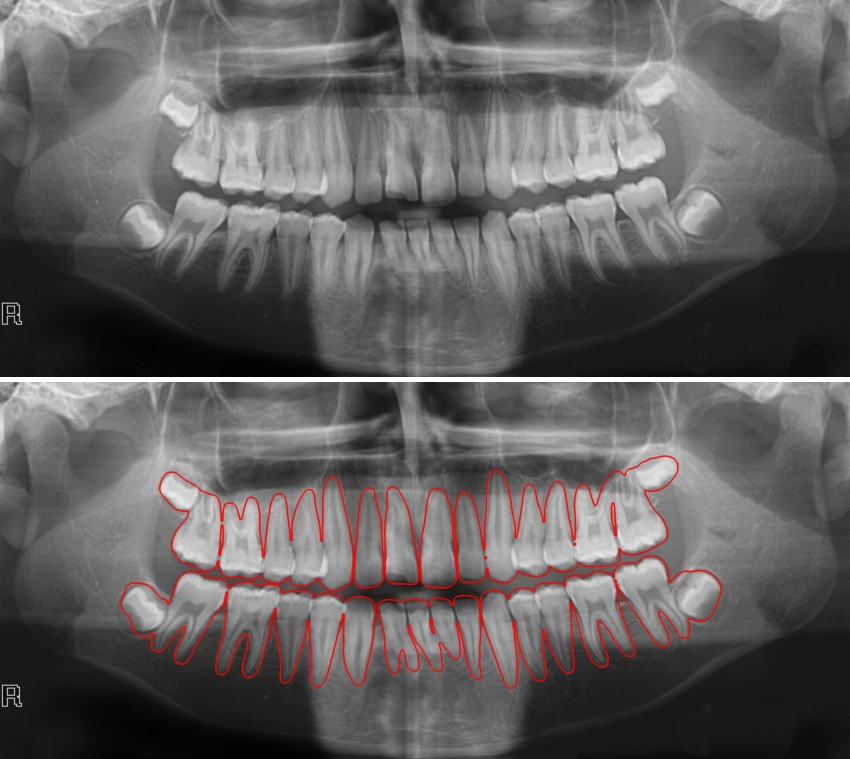
Real-Life Applications of Semantic Segmentation
Semantic segmentation finds applications in diverse fields, such as:
- In medical image diagnosis, for assistance in analyzing CT scans in more detail.
- In scene segmentation, to identify individual objects in a particular scene.
- In disaster management with satellites, to detect damaged areas resulting from flooding.

Instance Segmentation
Instance segmentation identifies each instance of the same object, making it more granular than semantic segmentation. For example, if there are three elephants in an image, instance segmentation will separately identify and highlight each elephant, treating them as distinct instances.

The following are a couple of popular instance segmentation models:
SAM
Segment Anything Model (SAM) is an instance segmentation framework by Meta AI that allows you to segment any object through clickable prompts. The model follows the zero-shot learning paradigm, making it suitable for classifying novel objects in an image.
The model uses the encoder-decoder architecture, where the primary encoder computes image embeddings, and a prompt encoder takes user prompts as input. A mask decoder works to understand the encodings to predict the final output.

Mask R-CNN
Mask Region-based convolutional neural networks (Mask R-CNNs) extend the faster R-CNN architecture. They do this by including another branch that predicts the segmentation masks of regions of interest (ROI).
In Faster R-CNN, one branch classifies object regions based on ground-truth bounding boxes, and the other predicts bounding box offsets. Faster R-CNN adds these offsets to the classified regions to ensure predicted bounding boxes come closer to ground-truth bounding boxes.
Adding the third branch improves generalization performance and boosts the training process.

Real-Life Applications of Instance Segmentation
Instance segmentation finds its usage in various computer vision applications, including:
- Aerial imaging for geospatial analysis, to detect moving objects (cars, etc.) or structures like streets and buildings.
- Virtual try-on in retail, to let customers try different wearables virtually.
- Medical diagnosis, to identify different instances of cells for detecting cancer.

Pose Estimation
Pose estimation identifies key semantic points on an object to track orientation. For example, it helps identify human body movements by marking key points such as the shoulders, right arm, left arm, etc.

Mainstream models for pose estimation tasks include:
OpenPose
OpenPose is a real-time multi-person 2D bottom-up pose detection model that uses Part Affinity Fields (PAFs) to relate body parts to individuals. It has better runtime performance and accuracy as it only uses PAF refinements instead of the simultaneous PAF and body-part refinement strategy.

MoveNet
MoveNet is a pre-trained high-speed position tracking model by TensorFlow that captures knee, hip, shoulder, elbow, wrist, ear, eye, and nose movements, marking a maximum of 17 key points.
TensorFlow offers two variants: Lightning and Thunder. The Lightning variant is for low-latency applications, while the Thunder variant is suitable for use cases where accuracy is critical.
PoseNet
PoseNet is a framework based on TensorFlow.js that detects poses using a CNN and a pose-decoding algorithm. This computer vision algorithm assigns pose confidence scores, keypoint positions, and corresponding keypoint confidence scores.
The model can detect up to 17 key points, including the nose, ear, left knee, right foot, etc. It has two variants. One variant detects only one person, while the other can identify multiple individuals in an image or video.
Real-Life Applications of Pose Estimation
Pose estimation has many applications, some of which include:
- Computer vision robotics, where pose estimation models can help train robotic movements.
- Fitness and sports, where trainers can track body movements to design better training regimes.
- VR-enabled games, where pose estimation can help detect a gamer’s movement during gameplay.
Image Generation and Synthesis
Image generation is an evolving field where AI algorithms generate novel images, artwork, designs, etc., based on training data. This training data can include images from the web or some other user-defined source.

Below are a few well-known image-generation models:
DALL-E
DALL-E is a zero-shot text-to-image generator created by OpenAI. This tool takes user-defined textual prompts as input to generate realistic images.
A variant of the famous Generative Pre-Trained Transformer 3 (GPT-3) model, DALL-E 2 works on the Transformer architecture. It also uses a variational autoencoder (VAE) to reduce the number of image tokens for faster processing.

MidJourney
Like DALL-E, MidJourney is also a text-to-image generator but uses the diffusion architecture to produce images.
The diffusion method successively adds noise to an input image and then denoises it to reconstruct the original image. Once trained, the model can take any random input to generate images.

Stable Diffusion
Stable Diffusion by Stability AI also uses the diffusion framework to generate photo-realistic images through textual user prompts.
Users can train the model on limited computational resources. This is because the framework uses pre-trained autoencoders with cross-attention layers to boost quality and training speed.
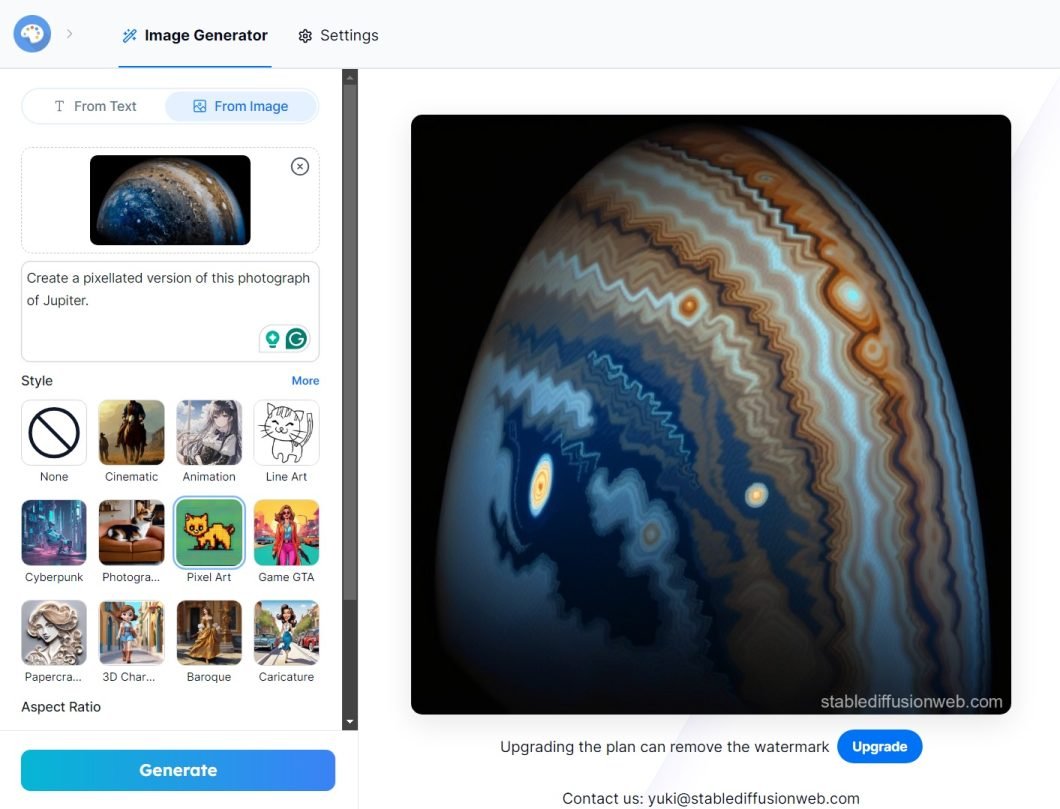
Real-Life Applications of Image Generation and Synthesis
Image generation has multiple use cases, including:
- Content creation, where advertisers can use image generators to produce artwork for branding and digital marketing.
- Product Ideation provides manufacturers and designers with textual prompts describing their desired features to generate suitable images.
- Synthetic data generation to help overcome data scarcity and privacy problems in computer vision.
Challenges and Future Directions in Computer Vision Tasks
As computer vision applications increase, the number of challenges also rises. These challenges guide future research to overcome the most pressing issues facing the AI community.
Challenges
- Lack of infrastructure: Computer vision requires incredibly powerful hardware and a set of software technologies. The main challenge is to make computer vision scalable and cost-efficient while achieving sufficient accuracy. The lack of optimized infrastructure is the main reason why we do not see more computer vision systems in production. At viso.ai, we’ve built the most powerful end-to-end platform Viso Suite to solve this challenge and enable organizations to implement and scale real-world computer vision.
- Lack of annotated data: Training CV models is challenging because of the scarcity of relevant data for training. For example, the lack of annotated datasets has been a long-standing issue in the medical field, where only a few images exist, making AI-based diagnosis difficult. However, self-supervised learning is a promising development that helps you develop models with limited labeled data. In general, algorithms tend to become dramatically more efficient, and the latest frameworks enable better AI models to be trained with a fraction of previously required data.
- Ethical issues: With ever-evolving data regulations, it is paramount that computer vision models produce unbiased and fair output. The challenge here is understanding critical sources of bias and identifying techniques to remove them without compromising performance. Read our article about ethical challenges at OpenAI.
Future Directions
- Explainable AI: Explainable AI (XAI) is one research paradigm that can help you detect biases easily. This is because XAI allows you to see how a model works behind the scenes.
- Multimodal learning: As evident from image generator models, combining text and image data is the norm. The future will likely see more models integrating different modalities, such as audio and video, to make CV models more context-aware.
- High-performance AI video analytics: Today, we’ve only achieved a fraction of what will be possible in terms of real-time video understanding. The near future will bring breakthroughs in running more capable ML models more cost-efficiently on higher-resolution data.
Computer Vision Tasks: Key Takeaways
As the research community develops more robust architectures, the tasks that CV models can perform will likely evolve, giving rise to newer applications in various domains.
But the key things to remember for now include:
- Common computer vision tasks: Image classification, object detection, pose semantic segmentation, instance segmentation, pose estimation, and image generation will remain among the top computer vision tasks.
- CNNs and Transformers: While the CNN framework dominates most tasks discussed above, the transformer architecture remains crucial for generative AI.
- Multimodal learning and XAI: Multimodal learning and explainable AI will revolutionize how humans interact with AI models and improve AI’s decision-making process.
You can explore related topics in the following articles:
- How to evaluate a computer vision model’s performance
- Data augmentation techniques
- Popular computer vision tools
- Computer vision guide for businesses
- Feature extraction in Python
Getting Started With End-to-End Computer Vision
Deploying computer vision systems can be messy, as you require a robust data pipeline to collect, clean, and pre-process unstructured data, a data storage platform, and experts who understand modeling procedures.
Using open-source tools may be one option. However, they usually require familiarity with the back-end code, and integrating them into a single orchestrated workflow with your existing tech stack is complex.
Viso Suite is a one-stop end-to-end infrastructure for applying computer vision tasks to real-world solutions:
- Annotate visual data through automated tools
- Build a complete computer vision pipeline for development and deployment
- Monitor performance through custom dashboards
Want to see how computer vision can work in your industry? Get started with Viso Suite for enterprise machine learning applications.