AlexNet is an Image Classification model that transformed deep learning. It was introduced by Geoffrey Hinton and his team in 2012 and marked a key event in the history of deep learning, showcasing the strengths of CNN architectures and its vast applications.
Before AlexNet, people were skeptical about whether deep learning could be applied successfully to very large datasets. However, a team of researchers aimed to prove that Deep Neural Architectures were the future, and succeeded in it; AlexNet exploded the interest in deep learning post-2012.
The Deep Learning (DL) model was designed to compete in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012. This is an annual competition that benchmarks algorithms for image classification. Before ImageNet, there was no availability of a large dataset to train Deep Neural Networks. As a result, consequently, ImageNet also played a role in the success of Deep Learning.
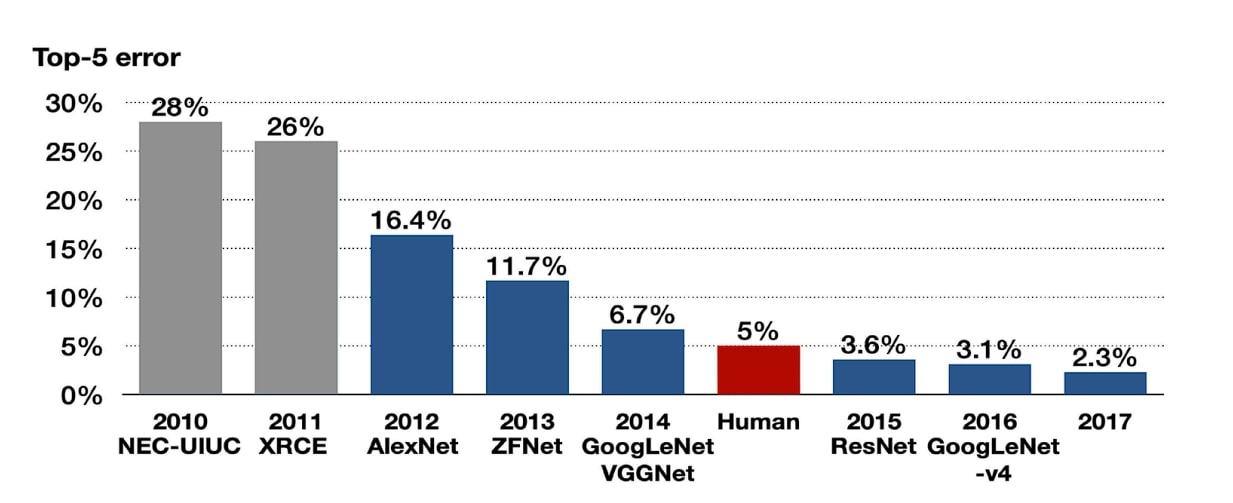
In that competition, AlexNet performed exceptionally well. It significantly outperformed the runner-up model by reducing the top-5 error rate from 26.2% to 15.3%.

Before AlexNet
Machine learning models such as Support Vector Machines (SVMs) and shallow neural networks dominated computer vision before the development of AlexNet. Training a deep model with millions of parameters seemed impossible, we will investigate why, but first, let’s look into the limitations of the previous Machine Learning (ML) models.
- Feature Engineering: SVMs and simple Neural Networks (NNs) require extensive handcrafted feature engineering, which makes scaling and generalization impossible.
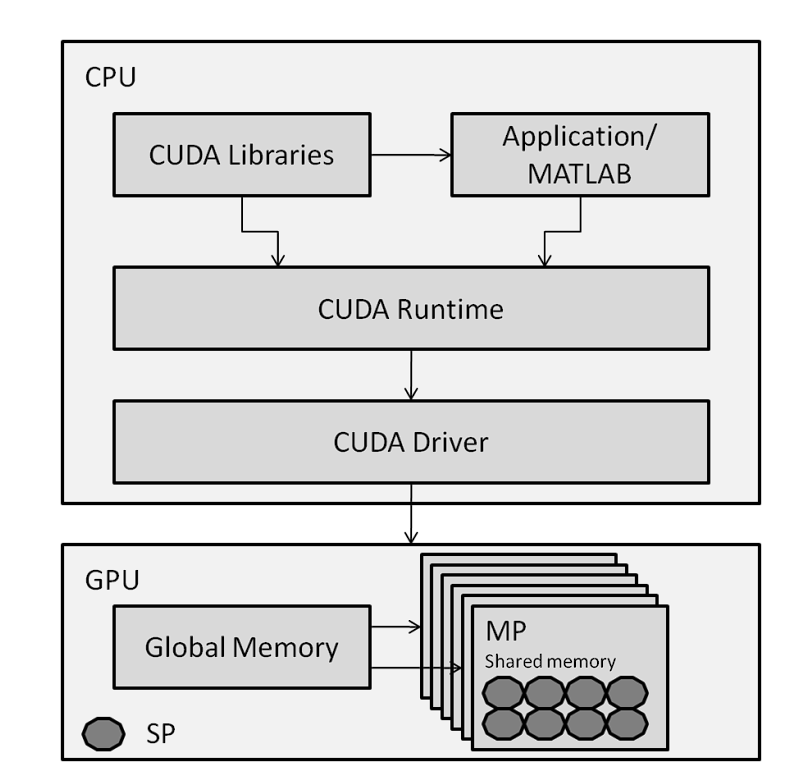
- Computational Resources: Before AlexNet, researchers primarily used CPUs to train models because they did not have direct access to GPU processing. This changed when Nvidia released the CUDA API, allowing AI software to access parallel processing using GPUs.

CUDA Architecture – source
- Vanishing Gradient Problem: Deep Networks faced a vanishing gradient problem. This is where the gradients become too small during backpropagation or disappear completely.
Due to computational limitations, gradient vanishing, and a lack of large datasets to train the model on, most neural networks were shallow. These obstacles made it impossible for the model to generalize.
What is ImageNet?

ImageNet is a vast visual database designed for object recognition research. It consists of over 14 million hand-annotated images with over 20,000 categories. This dataset played a major role in the success of AlexNet and the advancements in DL, as there was no large dataset on which Deep NNs could be trained previously.
The ImageNet project also conducts an annual ImageNet Large Scale Visual Recognition Challenge (ILSVRC) where researchers evaluate their algorithms to classify objects and scenes correctly.
The competition is important because it enables researchers to push the limits of existing models and invent new methodologies. Several breakthrough models have been unveiled in this competition, AlexNet being one of them.
Contribution of AlexNet
The AlexNet paper titled “ImageNet Classification with Deep Convolutional Neural Networks” solved the above-discussed problems.
This paper’s release deeply influenced the trajectory of deep learning. The methods and innovations introduced became a standard for training Deep Neural Networks. Here are the key innovations introduced:
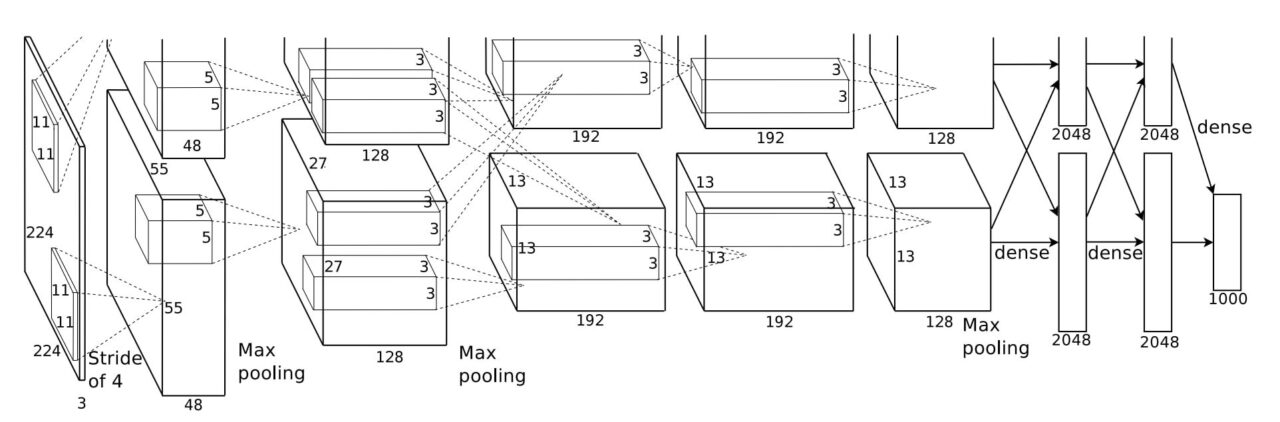
- Deep Architecture: This model utilized deep architecture compared to any NN model released previously. It consisted of five convolutional layers followed by three fully connected layers.
- ReLU Nonlinearity: CNNs at that time used functions such as Tanh or Sigmoid to process information between layers. These functions slowed down the training. In contrast, ReLU (Rectified Linear Unit) made the entire process simpler and many times faster. It outputs only if the input is given to it as positive, otherwise, it outputs a zero.
- Overlapping Pooling: Overlapping pooling is just like regular max pooling layers, but in overlapping pooling, as the window moves across, it overlaps with the previous window. This improved the error percentage in AlexNet.
- Use of GPU: Before AlexNet, NNs were trained on the CPU, which made the process slow. However, the researcher of AlexNet incorporated GPUs, which accelerated computation time significantly. This proved that Deep NNs can be trained feasibly on GPUs.
- Local Response Normalization (LRN): This is a process of normalizing adjacent channels in the network, which normalizes the activity of neurons within a local neighborhood.
The AlexNet Architecture
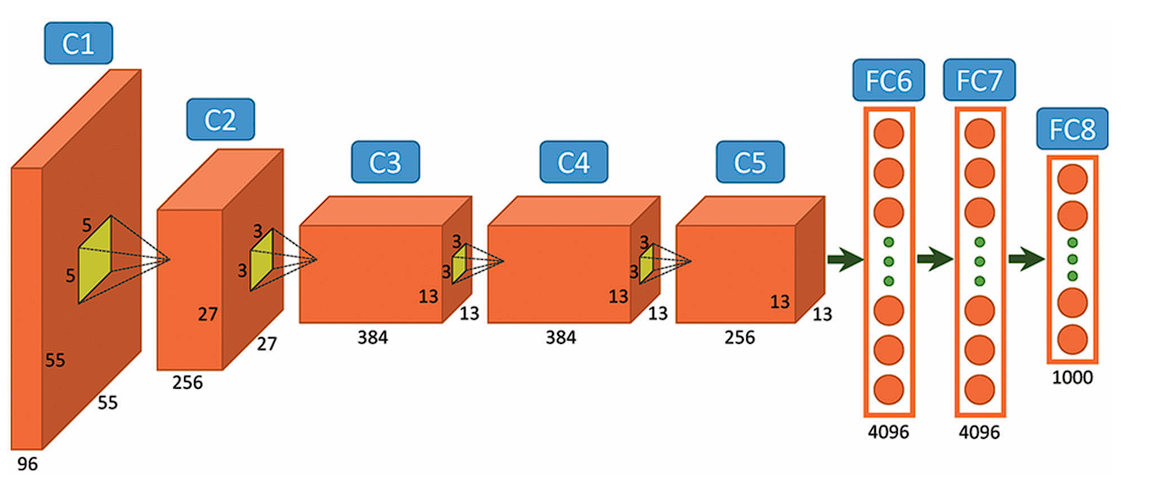
AlexNet comprises a rather simple architecture compared to the latest Deep Learning Models. It consists of 8 layers: 5 convolutional layers and 3 fully connected layers.
However, it integrates several key innovations of its time, including the ReLU Activation Functions, Local Response Normalization (LRN), and Overlapping Max Pooling. We will look at each of them below.
Input Layer
AlexNet takes images of the Input size of 227x227x3 RGB Pixels.
Convolutional Layers
- First Layer: The first layer uses 96 kernels of size 11×11 with a stride of 4, activates them with the ReLU activation function, and then performs a Max Pooling operation.
- Second Layer: The second layer takes the output of the first layer as the input, with 256 kernels of size 5x5x48.
- Third Layer: 384 kernels of size 3x3x256. No pooling or normalization operations are performed on the third, fourth, and fifth layers.
- Fourth Layer: 384 kernels of size 3x3x192.
- Fifth Layer: 256 kernels of size 3x3x192.
Fully Connected Layers
The fully connected layers have 4096 neurons each.
Output Layer
The output layer is a SoftMax layer that outputs probabilities of the 1000 class labels.
Stochastic Gradient Descent
AlexNet uses stochastic gradient descent (SGD) with momentum for optimization. SGD is a variant of Gradient Descent. In SGD, instead of performing calculations on the whole dataset, which is computationally expensive, SGD randomly picks a batch of images, calculates the loss, and updates the weight parameters.
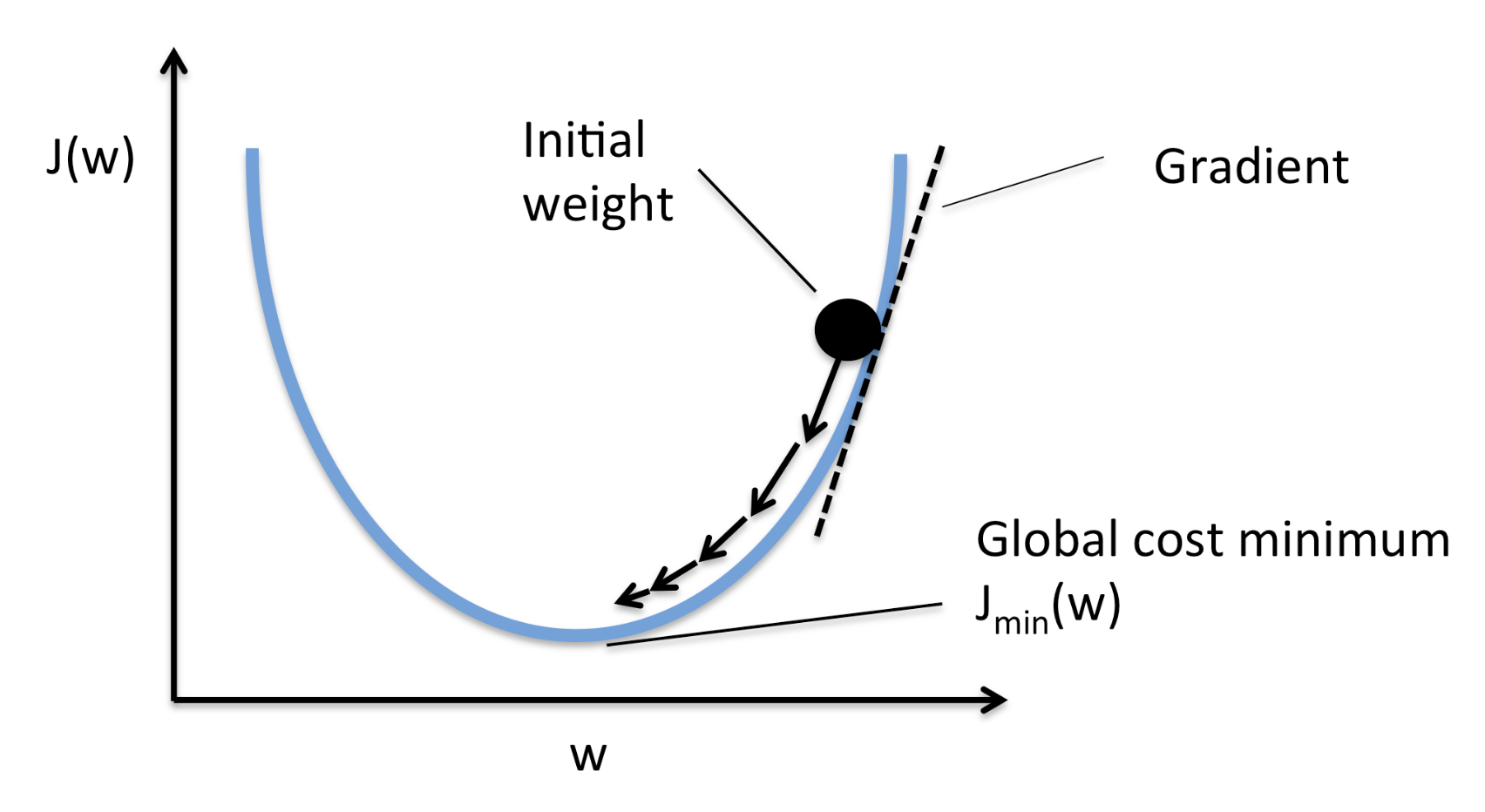
Momentum
Momentum helps accelerate SGD and dampens fluctuations. It performs this by adding a fraction of the previous weight vector to the current weight vector. This prevents sharp updates and helps the model overcome saddle points.
Weight Decay
Lnew(w) = Loriginal(w) + λwTw
Weight decay adds a penalty on the size of the weights. By penalizing larger weights, weight decay encourages the model to learn smaller weights that capture the underlying patterns in the data, rather than memorizing specific details that result in overfitting.
Data Augmentation
Data Augmentation artificially increases the size and diversity of the training data using transformations that don’t change the actual object in the image. This forces the model to learn better and increase its ability to cater to unseen images.
AlexNet used Random Cropping and Flipping, and Color Jitter Augmentations.
Innovations Introduced
ReLU
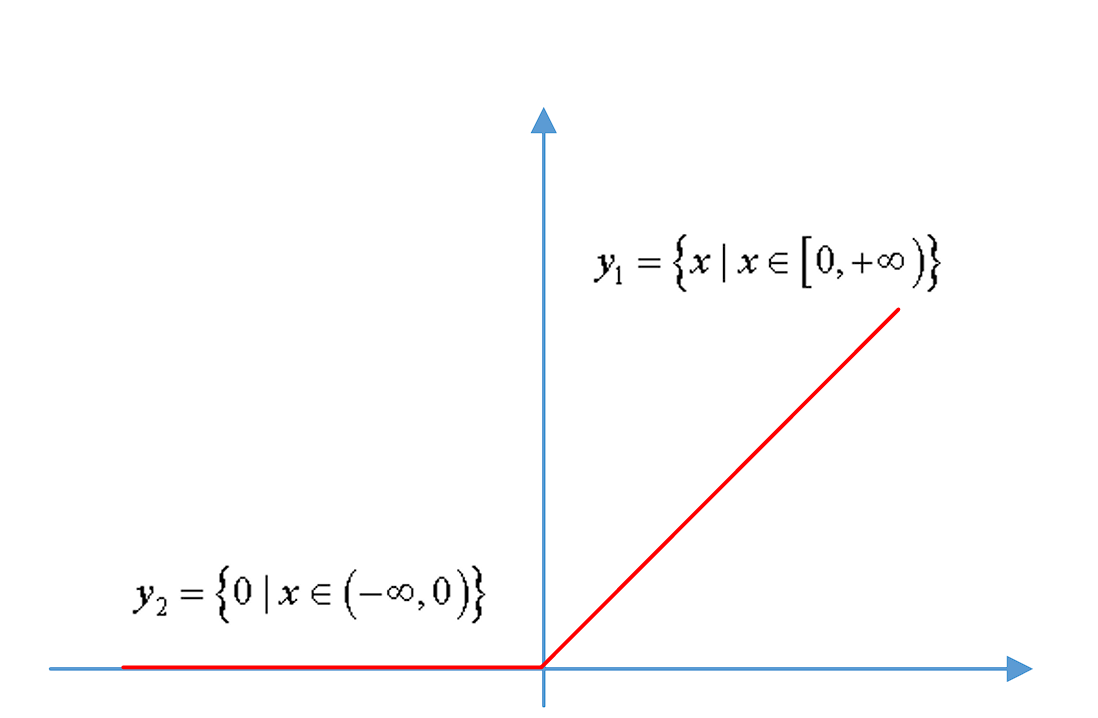
This is a non-linear activation function that has a simple derivative. (It eradicates negative values and only outputs positive values).
Before ReLU, Sigmoid, and Tanh functions were used, but they slowed down the training and caused gradient vanishing. ReLU came up as an alternative since it is faster and requires fewer computation resources during backpropagation because the derivative of Tanh is always less than 1, while the derivative of ReLU is either 0 or 1.
Dropout Layers
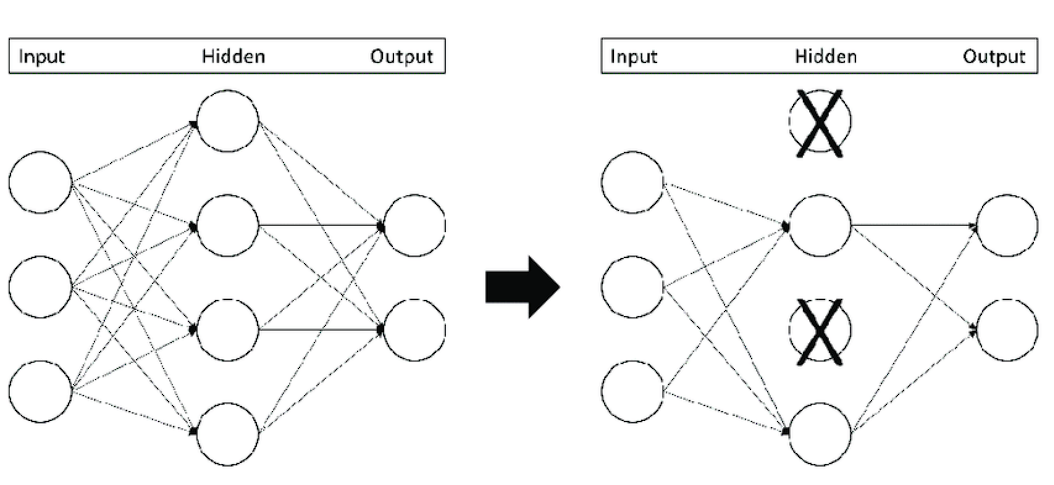
This is a regularization technique (a technique used to address overfitting) that “drops out” or turns off neurons.
This is a simple method that prevents the model from overfitting. It does this by making the model learn more robust features and stopping the model from condensing features in a single area of the network.
Dropout increases the training time; however, the model learns to generalize better.
Overlapping Pooling
Pooling layers in CNNs summarize the outputs of neighboring groups of neurons in the same kernel map. Traditionally, the neighborhoods summarized by adjacent pooling units do not overlap. However, in Overlapping pooling the adjacent pooling operations overlap with each other. This approach:
- Reduces the size of the network
- Provides slight translational invariance.
- Makes it difficult for the model to overfit.
Performance and Impact
The AlexNet architecture dominated in 2012 by achieving a top-5 error rate of 15.3%, significantly lower than the runner-up’s 26.2%.
This large reduction in error rate excited the researchers with the untapped potential of deep neural networks in handling large image datasets. Subsequently, various Deep Learning models were developed later.
AlexNet inspired Networks
The success of AlexNet inspired the design and development of various neural network architectures. These include:
- VGGNet: It was developed by K. Simonyan and A. Zisserman at Oxford. The VGGNet incorporated ideas from AlexNet and was the next step taken after AlexNet.
- GoogLeNet (Inception): This was introduced by Google, which further developed the architecture of AlexNet.
- ResNets: AlexNet started to face a vanishing gradient with deeper networks. To overcome this, ResNet was developed. These networks introduced residual learning, also called skip connections. The skip connection connects activations of lower layers to higher layers by skipping some layers in between.
Applications of AlexNet
Developers created AlexNet for image classification. However, advances in its architecture and transfer learning (a technique where a model trained on one task is repurposed for a novel related task) opened up a new set of possibilities for AlexNet. Moreover, its convolutional layers form the foundation for object detection models such as Fast R-CNN and Faster R-CNN, and professionals have utilized them in fields like autonomous driving and surveillance.
- Autism Detection: Gazal and their team developed a model using transfer learning for early detection of autism in children. The model was first trained on ImageNet, and then the pre-trained model was further trained on their dataset related to autism.

Classification for Autism – source

- Video Classification: For video classification, researchers have used AlexNet to extract critical features in videos for action recognition and event classification.

UAV Vehicle Target – source - Agriculture: AlexNet analyzes images to recognize the health and condition of plants, empowering farmers to take timely measures that improve crop yield and quality. Additionally, researchers have employed AlexNet for plant stress detection and weed and pest identification.
- Disaster Management: Rescue teams use the model for disaster assessment and making emergency relief decisions using images from satellites and drones.
- Medical Images: Doctors utilize AlexNet to diagnose various medical conditions. For example, they use it to analyze X-rays, MRIs (particularly brain MRIs), and CT scans for disease detection, including various types of cancers and organ-specific illnesses. Additionally, AlexNet assists in diagnosing and monitoring eye diseases by analyzing retinal images.

AlexNet Recap
AlexNet marked a significant milestone in the development of Convolutional Neural Networks (CNNs) by demonstrating their potential to handle large-scale image recognition tasks. The key innovations introduced by AlexNet include ReLU activation functions for faster convergence, the use of dropout for controlling overfitting, and the use of a GPU to feasibly train the model. These contributions are still in use today. Moreover, the further models developed after AlexNet took it as a base groundwork and inspiration.