Viso Suite is our end-to-end computer vision platform for enterprises. Learn more about how we help firms leverage visual data for real-world solutions.
Viso Suite is our end-to-end computer vision platform for enterprises. Learn more about how we help firms leverage visual data for real-world solutions.
YOLOv8 is the newest model in the YOLO algorithm series – the most well-known family of object detection and classification models in the Computer Vision (CV) field. With the latest version, the YOLO legacy lives on by providing state-of-the-art results for image or video analytics, with an easy-to-implement framework.
In this article, we’ll discuss:
The evolution of the YOLO algorithms
Improvements and enhancements in YOLOv8
Implementation details and tips
Applications
Real-Life Computer Vision for Business
Viso.ai can help you implement computer vision models in an end-to-end computer vision system through the Viso Suite, which integrates simply with the model frameworks. Request a demo to see how your team can solve complex business problems with computer vision.
You Only Look Once (YOLO) is an object-detection algorithm introduced in 2015 in a research paper by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. YOLO’s architecture was a significant revolution in the real-time object detection space, surpassing its predecessor – the Region-based Convolutional Neural Network (R-CNN).
YOLO is a single-shot algorithm that directly classifies an object in a single pass by having only one neural network predict bounding boxes and class probabilities using a full image as input.
The family YOLO model is continuously evolving. Several research teams have since released different YOLO versions, with YOLOv8 being the latest iteration. The following section briefly overviews all the historical versions and their improvements.
A Brief History of YOLO
Before discussing YOLO’s evolution, let’s look at some basics of how a typical object detection algorithm works.
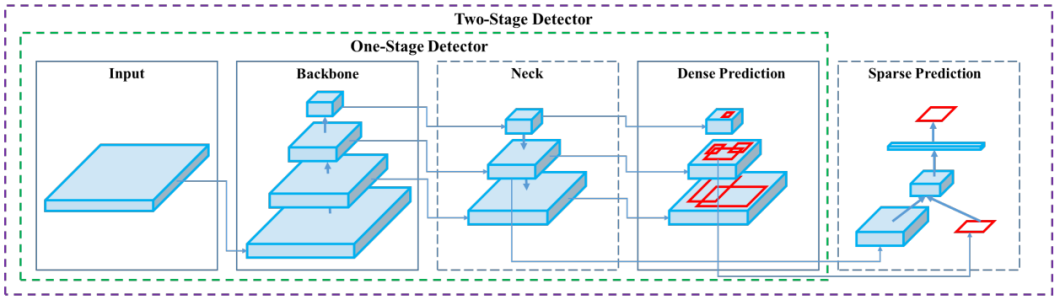
The diagram below illustrates the essential mechanics of an object detection model.
The essential mechanics of an object detection model – source.
The architecture consists of a backbone, neck, and head. The backbone is a pre-trained Convolutional Neural Network (CNN) that extracts low, medium, and high-level feature maps from an input image. The neck merges these feature maps using path aggregation blocks like the Feature Pyramid Network (FPN). It passes them onto the head, classifying objects and predicting bounding boxes.
The head can consist of one-stage or dense prediction models, such as YOLO or Single-shot Detector (SSD). Alternatively, it can feature two-stage or sparse prediction algorithms like the R-CNN series. Here are the YOLO versions up until YOLOv8.
Release
Authors
Tasks
Paper
YOLO
2015
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi
Object Detection, Basic Classification
You Only Look Once: Unified, Real-Time Object Detection
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
YOLOv8 Tasks
YOLOv8 comes in five variants based on the number of parameters – nano(n), small(s), medium(m), large(l), and extra large(x). You can use all the variants for classification, object detection, and segmentation.
Image Classification
Classification involves categorizing an entire image without localizing the object present within the image.
You can implement classification with YOLOv8 by adding the -cls suffix to the YOLOv8 version. For example, you can use yolov8n-cls.pt for classification if you wish to use the nano version.
Object Detection
Object detection localizes an object within an image by drawing bounding boxes. You don’t have to add any suffix to use YOLOv8 for detection.
The implementation only requires you to define the model as yolov8n.pt for object detection with the nano variant.
Image Segmentation
Image segmentation goes a step further and identifies each pixel belonging to an object. Unlike object detection, segmentation is more precise in locating different objects within a single image.
You can add the -seg suffix as yolov8n-seg.pt to implement segmentation with the YOLOv8 nano variant.
YOLOv8 Major Developments
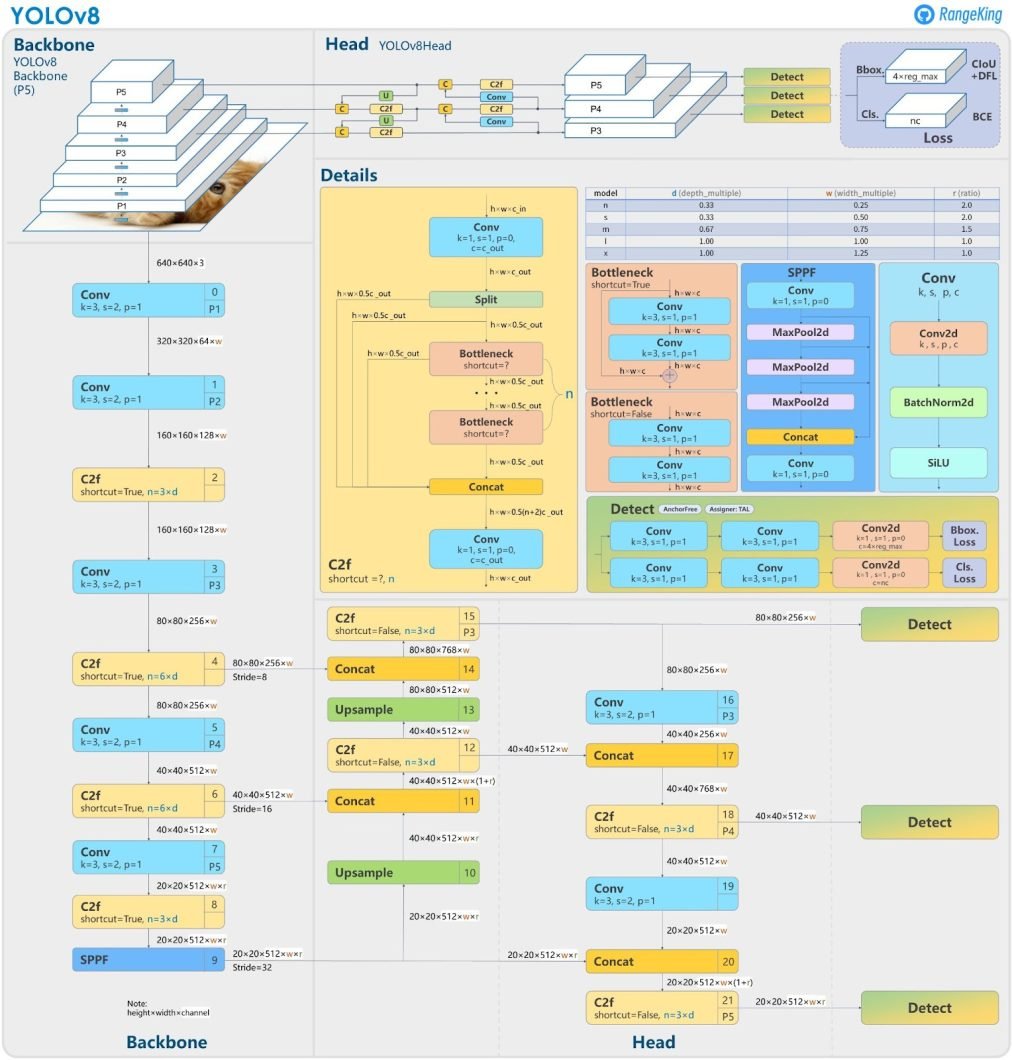
YOLOv8’s architecture is presented by GitHub user RangeKing
The main features of YOLOv8 include mosaic data augmentation, anchor-free detection, a C2f module, a decoupled head, and a modified loss function.
Let’s discuss each change in more detail.
Mosaic Data Augmentation
Like YOLOv4, YOLOv8 uses mosaic data augmentation that mixes four images to provide the model with better context information. The change in YOLOv8 is that the augmentation stops in the last ten training epochs to improve performance.
Anchor-Free Detection
YOLOv8 switched to anchor-free detection to improve generalization. The problem with anchor-based detection is that predefined anchor boxes reduce the learning speed for custom datasets.
With anchor-free detection, the model directly predicts an object’s midpoint and reduces the number of bounding box predictions. This helps speed up Non-max Suppression (NMS) – a pre-processing step that discards incorrect predictions.
C2f Module
The model’s backbone now consists of a C2f module instead of a C3 one. The difference between the two is that in C2f, the model concatenates the output of all bottleneck modules. In contrast, in C3, the model uses the output of the last bottleneck module.
A bottleneck module consists of bottleneck residual blocks that reduce computational costs in deep learning networks.
This speeds up the training process and improves gradient flow.
Decoupled Head
The diagram above illustrates that the head no longer performs classification and regression together. Instead, it performs the tasks separately, which increases model performance.
Loss
Misalignment is possible since the decoupled head separates the classification and regression tasks. It means the model may localize one object while classifying another.
The solution is to include a task alignment score based on which the model knows a positive and negative sample. The task alignment score multiplies the classification score with the Intersection over Union (IoU) score. The IoU score corresponds to the accuracy of a bounding box prediction.
Based on the alignment score, the model selects the top-k positive samples and computes a classification loss using BCE and regression loss using Complete IoU (CIoU) and Distributional Focal Loss (DFL).
The BCE loss simply measures the difference between the actual and predicted labels.
The CIoU loss considers how the predicted bounding box is relative to the ground truth in terms of the center point and aspect ratio. In contrast, the distributional focal loss optimizes the distribution of bounding box boundaries by focusing more on samples that the model misclassifies as false negatives.
YOLOv8 Implementation
Let’s see how you can implement YOLOv8 on your local machine for object detection. The benefit of YOLOv8 is that Ultralytics allows you to apply the model directly through the CLI and as a Python package.
CLI Implementation
You can start using the model by running pip install ultralytics in the Anaconda command prompt.
After installation, you can run the following command, which trains the YOLOv8 nano model on the COCO dataset with ten training epochs and a learning rate of 0.01.
You can view the CLI syntax for other operations in the Ultralytics CLI guide.
Python Implementation
The example below shows how you can quickly fine-tune the YOLOv8 nano model on a custom dataset for object detection.
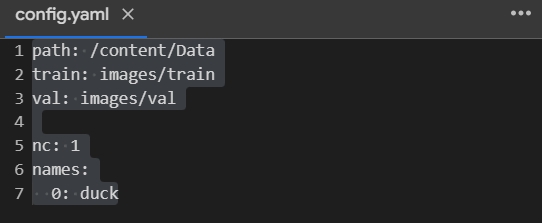
The data used comes from the Open Images Dataset v7 for object detection. The images consist of ducks with bounding box labels.
The publicly available sample for fine-tuning is on Kaggle, which contains 400 training and 50 validation images. The bounding box labels consist of x-y coordinates.
You can follow along the steps using the Google Colab notebook.
Step 1
The first step is to install the Ultralytics package.
!pip install ultralytics
Step 2
Next, we will import the relevant packages.
from ultralytics import YOLO
from google.colab import files
Step 3
Then, we will import our dataset using the Kaggle API. You must create an account on Kaggle to get your unique API key and download the related Kaggle JSON file.
Once the JSON file is on your local machine, you can upload it on Colab using the following:
files.upload()
A prompt will ask you to upload the file from your local machine.
You can run the following commands to mount the data on your Google Drive.
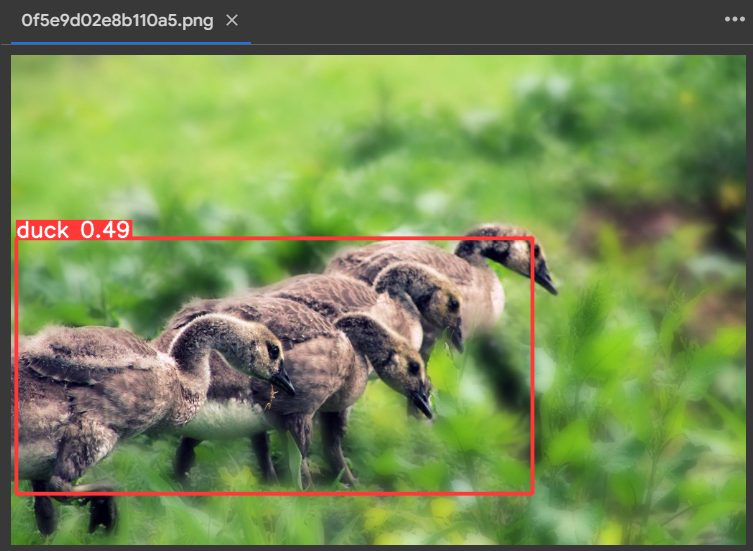
You can view the image’s predicted bounding box and classification score by going to “content/runs/detect/predict” from the left menu bar. It gives the following result:
Output for Duck detectionThe output of running object detection with YOLOv8 for Animal Detection
YOLOv8 Applications
YOLOv8 is a versatile model that you can use in several real-world applications. Below are a few popular use cases.
People counting:Retailers can train the model to detect real-time foot traffic in their shops, detect queue length, and more.
Sports analytics: Analysts can use the model to track player movements in a sports field to gather relevant insights regarding team dynamics (See AI in sports).
Inventory management: The object detection model can help detect product inventory levels to ensure sufficient stock levels and provide information regarding consumer behavior.
Autonomous vehicles: Autonomous driving uses object detection models to help navigate self-driving cars safely through the road.
YOLOv8 applied in smart cities for pothole detection.
YOLOv8: Key Takeaways
The YOLO series is the standard in the object detection space with its exemplary performance and broad applicability. Here are a few things you should remember about YOLOv8.
YOLOv8 improvements: YOLOv8’s primary improvements include a decoupled head with anchor-free detection and mosaic data augmentation that turns off in the last ten training epochs.
YOLOv8 tasks: Besides real-time object detection with cutting-edge speed and accuracy, YOLOv8 is efficient for classification and segmentation tasks.
Ease-of-use: With an easy-to-use package, users can implement YOLOv8 quickly through the CLI and Python IDE.
You can read related topics in the following articles: