Access to synthetic data is valuable for developing effective artificial intelligence (AI) and machine learning (ML) models. Real-world data often poses significant challenges, including privacy, availability, and bias. To address these challenges, we introduce synthetic data as an ML model training solution.
What is Synthetic Data?
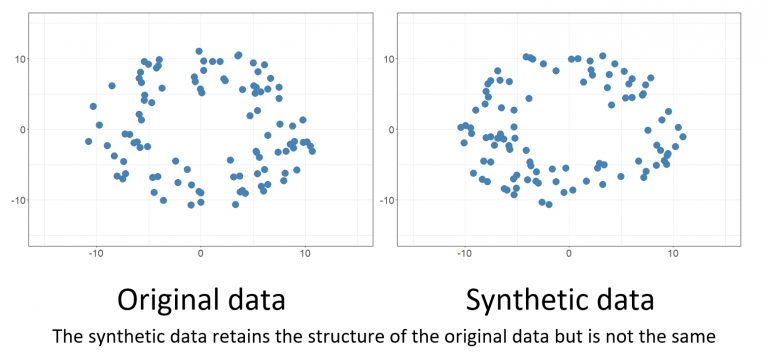
Synthetic data for AI refers to artificially generated data that resembles the characteristics and patterns of real data. Instead of relying on organic events, we generate this data through computer simulations or generative models. Synthetic data can augment existing datasets, create new datasets, or simulate unique scenarios.
Specifically, it solves two key problems: data scarcity and privacy concerns. Synthetic data offers the ability to generate vast amounts of training data. This omits the need for limited or sensitive real-world data.
As a result, a benefit of synthetic data is its rapid implementation and ability to overcome privacy risks. Since it does not contain any traceable personally identifiable information (PII), it’s a safer and more ethical alternative.
An example is a privacy-preserving solution for developing healthcare AI models. Healthcare professionals can use artificial patient data while keeping the statistical properties of real-world health data. As a result, individual privacy and personal information remain intact.

Synthetic Data in Computer Vision
In computer vision, the integration of synthetic data is instrumental in pushing the capabilities of artificial intelligence (AI) models. Particularly, generative techniques for data that closely mirror authentic visual patterns. This process significantly contributes to the augmentation of training datasets, resulting in improved model performance and robustness.
Synthetic data is especially essential in scenarios where obtaining a diverse and extensive real dataset is challenging or constrained by privacy considerations. By introducing artificially generated images during the training phase, computer vision models become adept at recognizing nuanced visual features. This leads to enhanced generalization when applied to authentic visual data.

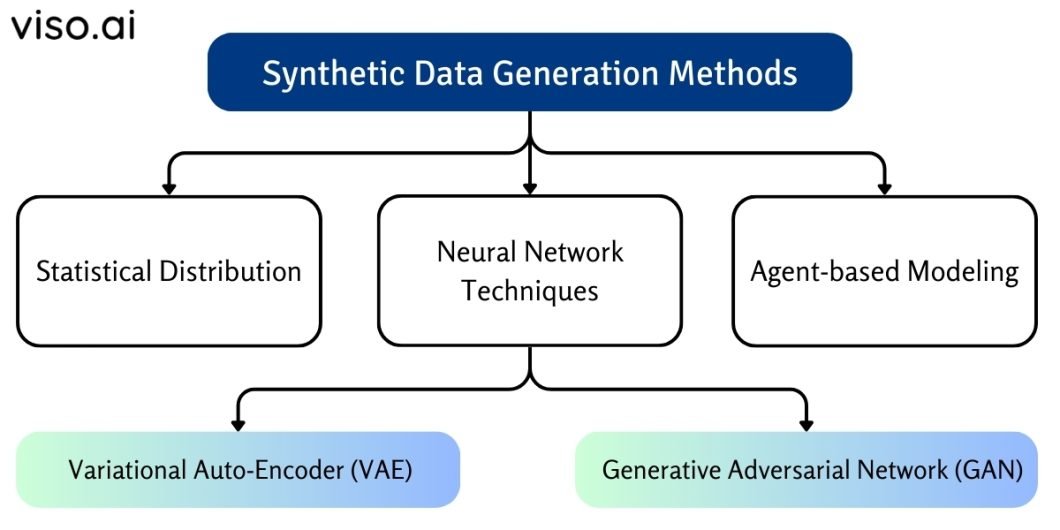
Synthetic Data Generation Methods
We generate synthetic data for machine learning with three common methods:
- Statistical distribution methods
- Agent-based modeling (by fitting real data to a known distribution)
- Neural network techniques
The data generation choice depends on the type of data needed, the desired outcome, and available computational resources.
Generation With Statistical Distribution
A simple way to generate data is with a statistical distribution matching the real data distribution. This involves analyzing the statistical properties of real data, such as mean, variance, and distribution type. The algorithm then generates new data points that follow the same statistical patterns.
While this method is simple and efficient, it may not capture complex relationships and variations in the real data. The accuracy of the trained model becomes highly dependent on the expertise of the data scientist. A better understanding of the statistical data structure will result in more realistic data.
Generation With Agent-Based Modeling
Another way to generate data is to fit the real data to a known distribution, or agent-based modeling. This involves analyzing and mapping the behavior of real data. Then, we implement algorithms such as iterative proportional fitting (IPF) or combinatorial optimization. These create individual agents that comply with real datasets.
These agents interact with each other and their environment. The agents generate emergent patterns of synthetic datasets that reflect the real-world system. Physical laws, behavioral rules, or statistical assumptions can form the basis for the model.
This method can capture more realistic and dynamic patterns in the real data. However, it requires a strong understanding of the underlying mechanisms and assumptions of the model.
Generation With Neural Network Techniques
Neural Networks are the most advanced techniques of automated data generation. They can handle much richer data distributions than traditional algorithms, such as decision trees. Neural networks can also synthesize unstructured data like images and video.
Technique No.1: Variational Auto-Encoder. A Variational Auto-Encoder (VAE) generates synthetic data via double transformation, known as an encoded-decoded architecture. First, it encodes the real data into a latent space (a lower-dimensional representation). Then, it decodes this data back into simulated data.
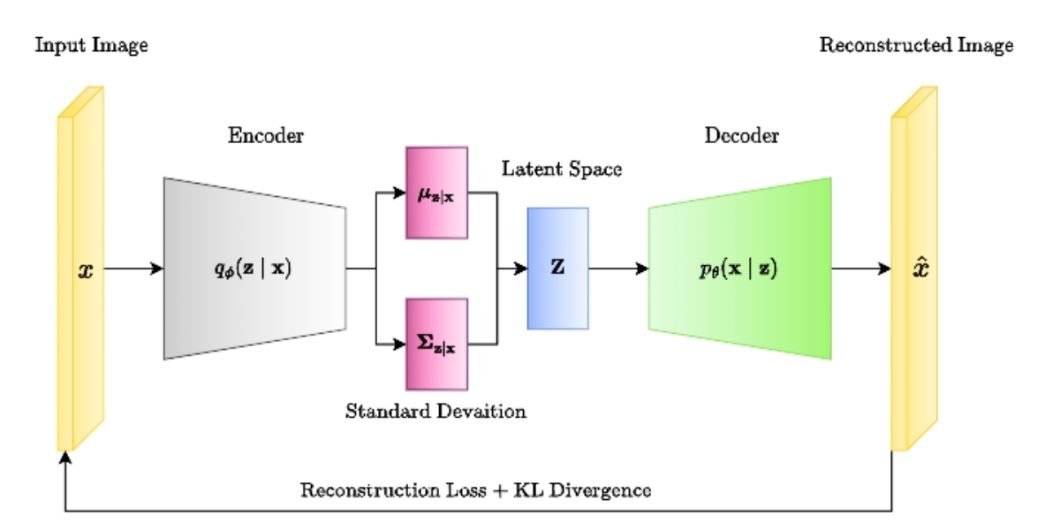
This is how it works:
- Encoder. The encoder takes input data (e.g., images, text) and compresses it into a smaller representation called the latent space.
- Latent space. The latent space captures the essential features and variations of the real data.
- Decoder. Conversely, the decoder reconstructs the authentic data from the latent space representation as accurately as possible.
- Training Losses. VAEs are trained with reconstruction and regularization loss functions. Reconstruction loss is the difference between original and reconstructed data points, measuring how the decoder reconstructs the input data. We calculate regularization loss using the Kullback-Leibler (KL) divergence between the latent and standard normal distributions.
The key to VAE’s success lies in its probabilistic approach. Instead of directly mapping inputs to outputs, the encoder generates a probability distribution for the latent representation. This allows the decoder to generate diverse data samples, capturing the inherent variability within the original dataset.
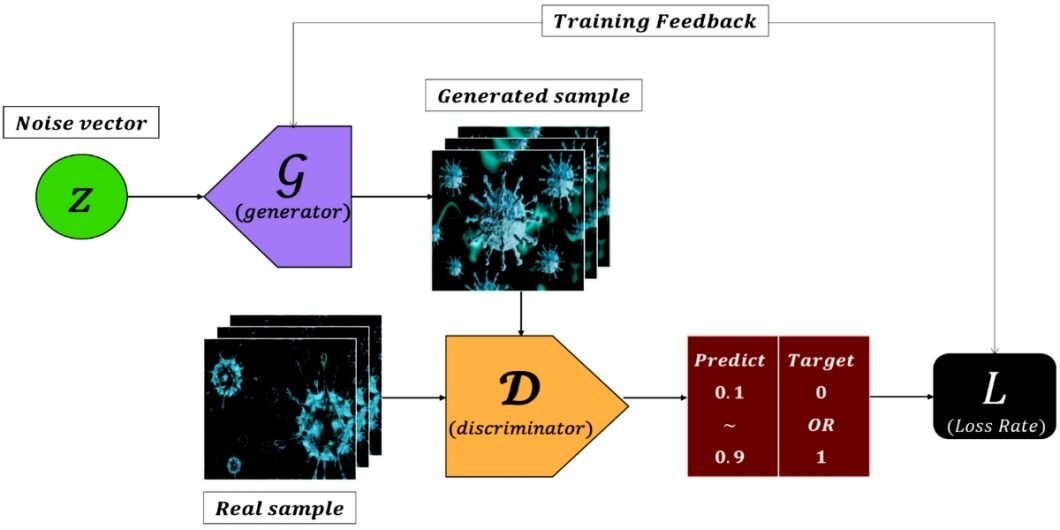
Technique No. 2: Generative Adversarial Network (GAN). Generative Adversarial Networks (GANs) are a powerful deep learning technique for generating synthetic data that resembles real data. This generative AI technique involves two competing neural networks: a generator and a discriminator.
- Generator. The generator network is responsible for creating new simulated data instances. It starts with a random noise vector and gradually transforms it into a realistic sample. This sample resembles the real data distribution.
- Discriminator. This network is a critic, trying to distinguish between real and fake data samples. It outputs a probability score indicating the likelihood that a sample came from the real data set.
In a GAN system, these two networks are trained in an adversarial manner.

The generator tries to fool the discriminator by creating increasingly realistic datasets while the discriminator distinguishes between real and fake GAN synthetic datasets. This process continues until both networks reach an equilibrium. Here, the generator can create data that is almost identical to real data.
Applications of Synthetic Data in Artificial Intelligence and Machine Learning
Synthetic data can train and test models for computer vision (CV), natural language processing (NLP), speech recognition, and more. Synthetic datasets help improve the accuracy and efficiency of AI models by providing more data variety, reducing bias, and enhancing scalability. This allows for:
- Developing Robust and Generalizable AI Models. Training AI models on synthetic data expose them to a wider range of variations and edge cases. This can lead to better performance in real-world situations.
- Rapid AI Development. Using generative models for synthetic data can be much faster and cheaper than collecting real-world data. Thus, significantly reducing the development timelines for new AI applications.
- Exploring New AI Ideas. With synthetic data, we can experiment with novel AI concepts without relying on real-world data. This is important for fraud detection, to evaluate several risk scenarios.
- Data Augmentation. When real-world data is limited, synthetic data can augment the dataset (artificially expand data sets). Thus, training machine learning models on a large dataset improves the performance of machine learning models.
- Bridging Data Gaps in Production Data. Synthetic datasets can fill in missing information for scenarios where data is scarce. This is important for developing autonomous vehicles, to train a model for situations without the need to test it with a self-driving car.
- Improving Fairness and Reducing Bias. Engineers can create unbiased data, representative of diverse populations leading to fairer and more ethical machine-learning models.
Synthetic Data Applications in Data Privacy
Synthetic data also plays a crucial role in addressing data privacy concerns, which include:
- Sharing Data Without Compromising Privacy. Artificial data can replace sensitive real-world data, enabling collaboration and research without infringing on individual privacy.
- Protecting Personal Information. Using artificial data instead of real data reduces the risk of data breaches and misuse of personal information.
- Complying With Data Regulations. Organizations can leverage simulated data to comply with strict data privacy regulations like GDPR. They may do this without limiting their ability to develop and deploy data-driven technologies.
Benefits of Synthetic Data in Digital Landscape
Privacy Protection
Synthetic data does not contain personally identifiable (PII) or sensitive information linked back to real data sources. Hence, organizations can use this data to train AI models without violating privacy laws or ethical principles.
Scalability
One of the biggest advantages of synthetic data is the potential to generate data on demand and in large quantities. This is particularly important when acquiring large, diverse datasets is logistically or economically unfeasible.
The data can also be highly adjusted to meet specific needs or custom requirements in scalable AI solutions. These may include generating rare or extreme cases, adding noise or outliers, and balancing classes or categories. For example, synthetic data can be generated to train models for detecting extremely rare diseases or variants.
Reducing Bias
Bias can arise from various sources, such as human errors, prejudices, or discrimination. Biased data can greatly affect the quality and reliability of the trained model. In this regard, the use of synthetic data can help mitigate dataset bias by generating more balanced and representative data samples.
Filling in Data Gaps
In situations where certain data points are missing or insufficient, synthetic data can be used to fill gaps in datasets. The ability to customize data points makes it possible for models to have comprehensive and diverse inputs for robust training.
Extreme Event Modelling
Infrequent occurrences like natural disasters, cyberattacks, and pandemics may not happen often, but they can cause significant disruptions. Such catastrophes bring substantial challenges and risks to fields like public safety, healthcare, and security sectors. In this context, synthetic data facilitates the simulation of these events that are difficult to measure in real data. This allows organizations to prepare for and mitigate potential risks.
Behavior Analysis for Next Action
Behavior analysis is the process of understanding and explaining how subjects act or react in certain contexts. Synthetic data can help simulate different scenarios and predict the future behavior of subjects, for example, the movement of robots in autonomous driving.
Reducing Data Collection Costs
Synthetic data minimizes the need for extensive data collection efforts. Thus, reducing costs associated with data acquisition. This is especially beneficial in industries where data collection is resource-intensive – for example, in medical imaging.
Data Anonymization
Data anonymization is the process of modifying information linked to real data sources or individuals. It allows for the sharing, publishing, or storing of real data without compromising secrecy and integrity. It can anonymize real data by generating artificial data with characteristics and patterns similar to real data but without traceable information.

Challenges and Limitations in Implementing Synthetic Data
Data Quality Limitations
Current methods may struggle to accurately represent the real world, which is full of complexity and nuances. This can lead to poorly performing models in these situations.
Furthermore, while noise injection and data augmentation can improve data diversity, they may introduce unintended biases or artifacts that negatively impact model performance.
Privacy Concerns
Generating realistic synthetic data may require the use of sensitive information from real datasets. This can lead to privacy breaches for non-anonymized synthetic data. Sometimes, even this data may be susceptible to reverse engineering, potentially exposing sensitive information from the original datasets.
Technical and Practical Challenges
Generating high-quality synthetic data can be computationally expensive and time-consuming, especially for complex datasets. Moreover, data generation methods may not be suitable for all types of data and applications. The effectiveness of these methods often depends on the specific domain and available resources.
Lack of Standardized Tools and Methodologies
The data generation field is still evolving, and there is a lack of standardized tools and methodologies. This makes it challenging for researchers and practitioners to compare results and build upon existing work.

The Future Outlook
Potential to Reshape Data Privacy Norms
Synthetic data can redefine privacy norms by providing a privacy-preserving alternative to traditional data-sharing practices. As organizations navigate stringent data protection regulations, it emerges as a viable solution that enables collaboration without compromising individual privacy.
Driving Innovation in AI Research and Development
The availability of high-quality synthetic data will accelerate AI research and development by lowering barriers to entry and enabling rapid experimentation. Researchers will be able to explore new ideas and test hypotheses without the constraints of limited real-world data.
Addressing Ethical Concerns and Ensuring Responsible AI Practices
Developing guidelines and best practices to ensure responsible data generation and usage is crucial. This will involve addressing bias, fairness, misuse, and transparency issues.
What Synthetic Data Applications Will We See Next?
Synthetic data has emerged as an innovative force in artificial intelligence, machine learning, and data privacy. This artificial data can overcome data scarcity, protect privacy, and address bias. Thus, the vast number of open-source tools promises enormous potential for advancing research, developing innovative applications, and shaping a more responsible and ethical future for AI.
Check out the following related articles to learn more about computer vision AI:
- Deepfakes in the Real World: Applications and Ethics
- Everything You Need To Know About Autoencoders For Generating Synthetic Data
- Learn How To Generate High-Quality Video Data For AI Vision Training
- Understand the Ethical Practices involved in AI
- Learn How to Analyze the Performance of Machine Learning Models
- How to Identify AI-Generated Content