
Person re-identification (Re-ID) retrieves a person of interest across multiple non-overlapping cameras. With deep neural networks and the increasing demand for intelligent video surveillance, this problem has gained significant interest in the computer vision community.

Person Re-Identification Problem
Person ReID is a specific person retrieval problem across non-overlapping, disjoint cameras. ReID aims to determine whether a person-of-interest has appeared in another place at a distinct time captured by multi-camera or even the same camera systems at a different time instant. Images, video sequences, and even text descriptions can represent queries.
The field of re-identification is a widely studied research field. With the urgent demand for public safety and an increasing number of surveillance cameras, the re-identification of people is also a goal of great practical importance.
Challenges
Re-identification is challenging due to various viewpoints, low image resolutions, illumination changes, unconstrained poses, occlusions, heterogeneous modalities, complex camera environments, background clutter, unreliable bounding box generation, and more. All those factors lead to greatly varying settings and uncertainty.
Additionally, for practical model deployment, the dynamically updated camera network, a large-scale gallery with efficient retrieval, group uncertainty, unseen testing scenarios, incremental model updating, and changing clothes also greatly increase the difficulties.
We still consider Re-identification an unsolved problem for real-world applications due to these challenges.
Re-ID with Deep Learning Methods
Early approaches mainly focus on feature construction with human body structures or distance metric learning. However, with deep learning, person re-identification has achieved promising performance on the popular benchmarks.
However, there is still a large gap between the research-oriented scenarios and practical vision applications.
How it Works
The following shows the concept of a practical person re-identification system to solve the problem of pedestrian retrieval across multiple surveillance cameras. Generally, building a person re-identification system requires five main steps:
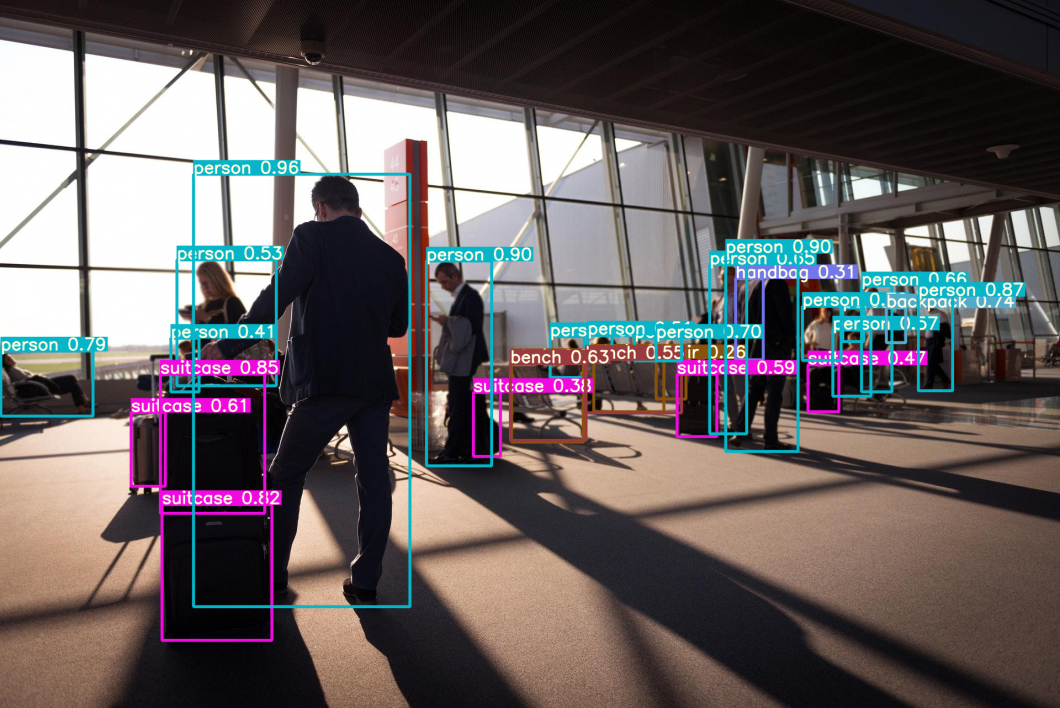
- Video Data Collection: The primary requirement is the availability of raw video data from surveillance cameras. Such cameras are usually placed in different places under varying environments. Often, the raw visual data contains a large amount of complex and noisy background clutter.
- Bounding Box Generation: People in the video data are detected using person detection and tracking algorithms. Video data provides bounding boxes containing images of people.
- Training Data Annotation: The cross-camera labels are annotated. Training data annotation is usually essential for discriminative Re-identification model learning due to the large cross-camera variations. For large domain shifts, the training data usually needs to be annotated in every new scenario.
- Trained Model: In the training phase, a discriminative and robust Re-ID model is trained with the previously annotated person images or videos. This is the core of the development of a re-identification system and is widely researched. Extensive models have been developed to handle the various challenges, concentrating on feature representation learning, distance metric learning, or their combinations.
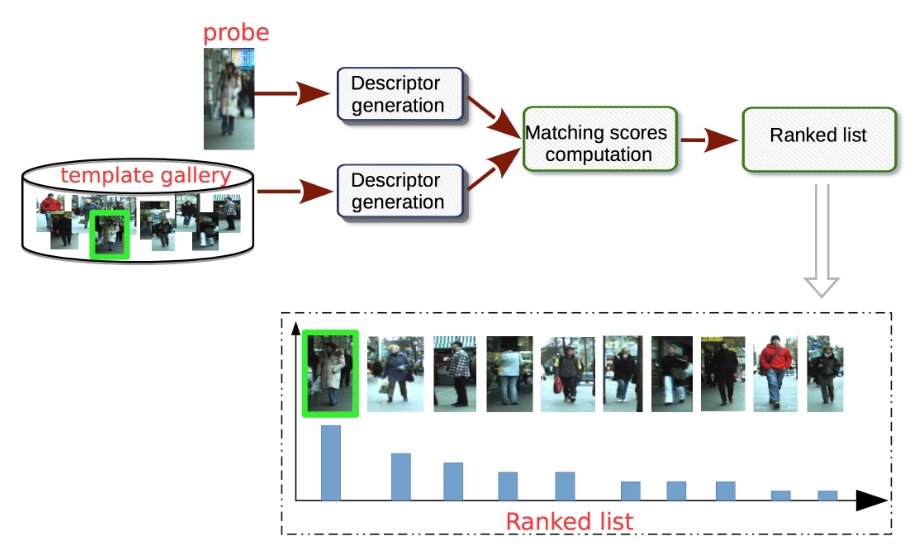
- Pedestrian Retrieval: The testing phase conducts the pedestrian retrieval. Given a query for a person of interest and a gallery set, the Re-ID model extracts feature representations learned in the previous stage. Sorting the calculated query-to-gallery similarity (probability of ID-match) can provide a ranking list.

State-of-the-Art Re-Identification: Closed-World
The widely studied “closed-world” setting is usually applied under research assumptions and has achieved relevant advances using deep learning techniques on several datasets. Typically, a standard closed-world Re-ID system contains three main components:
- Feature Representation Learning focuses on developing feature construction strategies.
- Deep Metric Learning for designing the training objectives with different loss functions or sampling strategies.
- Ranking Optimization to optimize the retrieved ranking list.
The Next Era of Re-Identification: Open-World
With the performance saturation in a closed-world setting, the research focus for person Re-ID has recently moved to the open-world setting, facing more challenging issues:
- Heterogeneous Re-ID by matching person images across heterogeneous modalities. This includes re-identification between depth and RGB images, text-to-image, visible-to-infrared, and cross-resolution re-identification.
- End-to-end Re-ID from the raw images or videos. This alleviates the reliance on the additional step for bounding box generation.
- Noise-robust Re-ID. This includes partial Re-ID with heavy occlusion, Re-ID with sample noise caused by detection or tracking errors, and Re-ID with label noise caused by annotation errors.
- Open-set person Re-ID. When the correct match does not occur in the gallery, Open-set Re-Identification is usually formulated as a person verification problem, such as discriminating whether two person images belong to the same identity.
- Semi or unsupervised Re-ID with limited or unavailable annotated labels.
Unsupervised Re-Identification with Deep Learning
In recent years, video-based re-identification has made great advances. Video sequences provide visual and temporal information using object tracking algorithms in practical video surveillance applications.
However, the annotation difficulty limits the scalability of supervised methods in large-scale camera networks enabled by distributed Edge AI, which drives the need for unsupervised video re-identification.
The difference between unsupervised learning and supervised learning is the availability of labels (image annotation). An intuitive idea for unsupervised learning is to estimate Re-identification labels as accurately as possible, “cross-camera label estimation”.
Feature learning then uses the estimated labels to train robust re-ID models.
With the success of deep learning, Unsupervised Re-ID has gained increasing attention in recent years. Within three years, the unsupervised Re-ID performance for the Market-1501 dataset has increased significantly, the Rank-1 accuracy increased from 54.5% to 90.3%, and mAP increased from 26.3% to 76.7%. Despite its achievements, we still consider the current unsupervised Re-identification as underdeveloped and requiring improvements.
There is still a large gap between the unsupervised and supervised Re-ID. For example, the rank-1 accuracy of supervised ConsAtt has achieved 96.1% on the Market-1501 dataset, while the highest accuracy of unsupervised SpCL is about 90.3%. Recently, researchers demonstrated that unsupervised learning with large-scale unlabeled training data has the ability to outperform supervised learning on various tasks.
What’s Next?
Person Re-Identification (Re-ID) solves a visual retrieval problem by searching for the queried person from a gallery of disjoint cameras. Deep learning techniques paved the way for important advances in recent years.
In the future, we expect to see several breakthroughs in supervised Re-identification methods for open-world settings, using unsupervised techniques to overcome data annotation challenges.
If you want to learn more about related topics, including computer vision and deep learning, we recommend the following articles from viso.ai:
- Explore applications in construction, smart cities, oil, gas, or utilities.
- Read about Federated Learning for distributed training
- A Guide to Deep Face Recognition Technology
- Learn about Edge Intelligence to deploy Deep Learning models
- The Deep Neural Network and three popular types of DNNs
- Combining Computer Vision and NLP: Promptable Object Detection
- Overcoming Model Training Challenges: Bias Detection in Computer Vision
- The YOLO series continues: computer vision with YOLOv9

References: