Upon its 2022 release, the YOLOv7 algorithm made big waves in the computer vision and machine learning communities. We will discuss how YOLOv7 works and what makes it one of the most valuable algorithms.
The YOLO version 7 algorithm surpassed previous object detection models and YOLO versions in terms of speed and accuracy. It is several times cheaper than other neural networks and can be trained much faster on small datasets without any pre-trained weights.
YOLO Real-Time Object Detection
What is Real-time Object Detection?
In computer vision, real-time object detection is a very important task that is often a key component in computer vision systems. Applications that use real-time object detection models include video analytics, robotics, autonomous vehicles, multi-object tracking and object counting, medical image analysis, and so on.
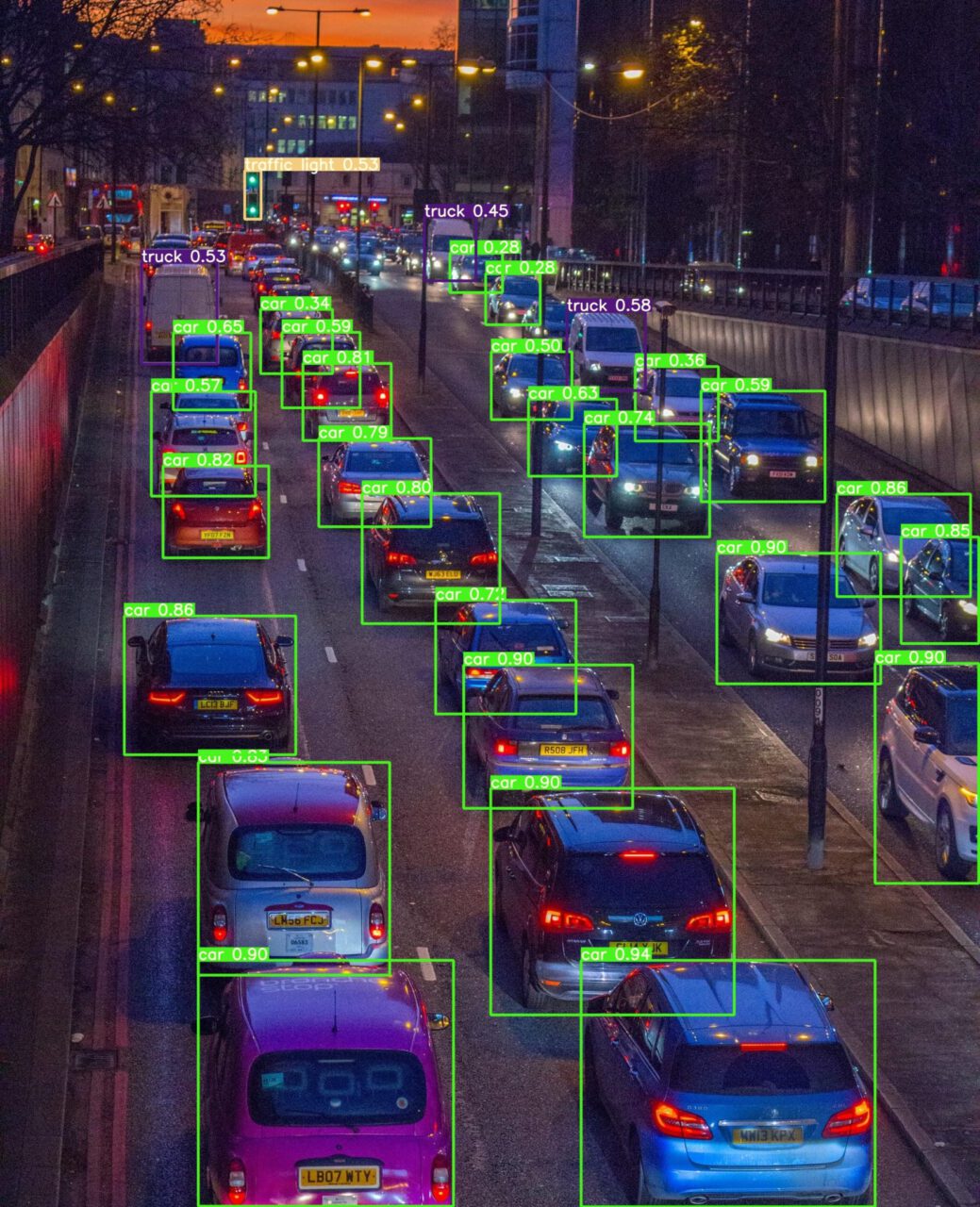
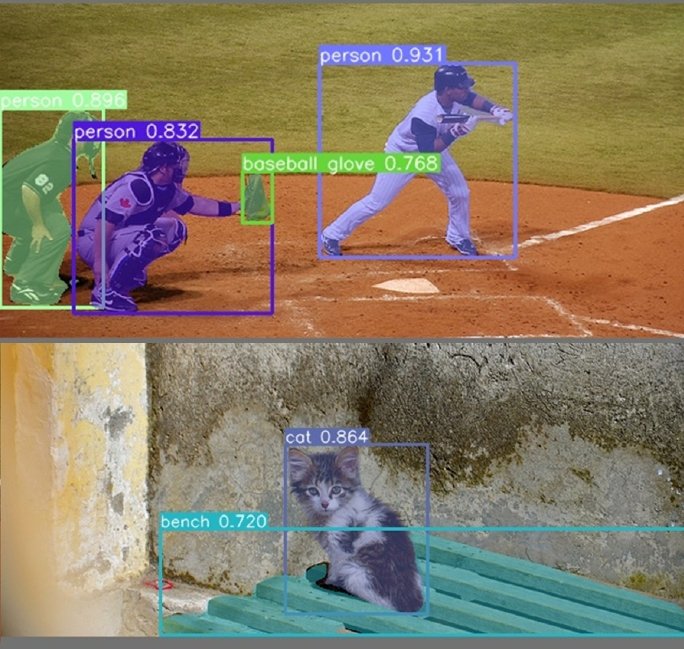
An object detector is an object detection algorithm that performs image recognition tasks by taking an image as input and then predicting bounding boxes and class probabilities for each object in the image (see the example image below). Most algorithms use a convolutional neural network (CNN) to extract features from the image to predict the probability of learned classes.

What is YOLO in Computer Vision?
YOLO stands for “You Only Look Once”; it is a popular family of real-time object detection algorithms. The original YOLO object detector was first released in 2016. It was created by Joseph Redmon, Ali Farhadi, and Santosh Divvala. At release, this architecture was much faster than other object detectors and became state-of-the-art for real-time computer vision applications.

Since then, different versions and variants of YOLO have been proposed, each providing a significant increase in performance and efficiency. The versions from YOLOv1 to the popular YOLOv3 were created by then-graduate student Joseph Redmon and advisor Ali Farhadi. YOLOv4 was introduced by Alexey Bochkovskiy in 2020, who continued the legacy since Redmon had stopped his computer vision research due to ethical concerns.
YOLOv7 is the latest official YOLO version created by the original authors of the YOLO architecture, released in 2022.
| Release | Authors | Tasks | Paper | |
|---|---|---|---|---|
| YOLO | 2015 | Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi | Object Detection, Basic Classification | You Only Look Once: Unified, Real-Time Object Detection |
| YOLOv2 | 2016 | Joseph Redmon, Ali Farhadi | Object Detection, Improved Classification | YOLO9000: Better, Faster, Stronger |
| YOLOv3 | 2018 | Joseph Redmon, Ali Farhadi | Object Detection, Multi-scale Detection | YOLOv3: An Incremental Improvement |
| YOLOv4 | 2020 | Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao | Object Detection, Basic Object Tracking | YOLOv4: Optimal Speed and Accuracy of Object Detection |
| YOLOv5 | 2020 | Ultralytics | Object Detection, Basic Instance Segmentation (via custom modifications) | no |
| YOLOv6 | 2022 | Chuyi Li, et al. | Object Detection, Instance Segmentation | YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications |

Unofficial YOLO Versions
There were some controversies in the computer vision community whenever other researchers and companies published their models as YOLO versions. A popular example is YOLOv5, which was created by the company Ultralytics. It’s similar to YOLOv4 but uses a different framework, PyTorch, instead of DarkNet. However, the creator of YOLOv4, Alexey Bochkovskiy, provided benchmarks comparing YOLOv4 vs. YOLOv5, showing that v4 is equal or better.
Another example is YOLOv6, which was published by the Chinese commerce giant, Meituan (hence the MT prefix of YOLOv6). There is also an unofficial YOLOv7 version that was released in the year before the official YOLOv7 (there are two YOLOv7s).
Both YOLOv5 and YOLOv6 are not considered part of the official YOLO series but were heavily inspired by the original one-stage YOLO architecture. Critics argue that companies try to benefit from the YOLO hype and that the papers were not adequately peer-reviewed or tested under the same conditions. Hence, some say that the official YOLOv7 should be the real YOLOv5.
Additionally, YOLOv8 has since been released by Ultralytics in 2023, also considered unofficial without a paper released.

How to Run YOLO Detection Efficiently at the Edge
Running object detection in real-world computer vision applications is hard. Key challenges include the allocation of computing resources, system robustness, scalability, efficiency, and latency. In addition, ML computer vision requires IoT communication (see AIoT) for data streaming with images as input and detections as output.
To overcome those challenges, the concept of Edge AI has been introduced, which leverages Edge Computing with Machine Learning (Edge ML, or Edge Intelligence). Edge AI modes ML processing from the cloud closer to the data source (camera). Thus, Edge AI applications form distributed edge systems with multiple, connected edge devices or virtual edge nodes (MEC or cloud).
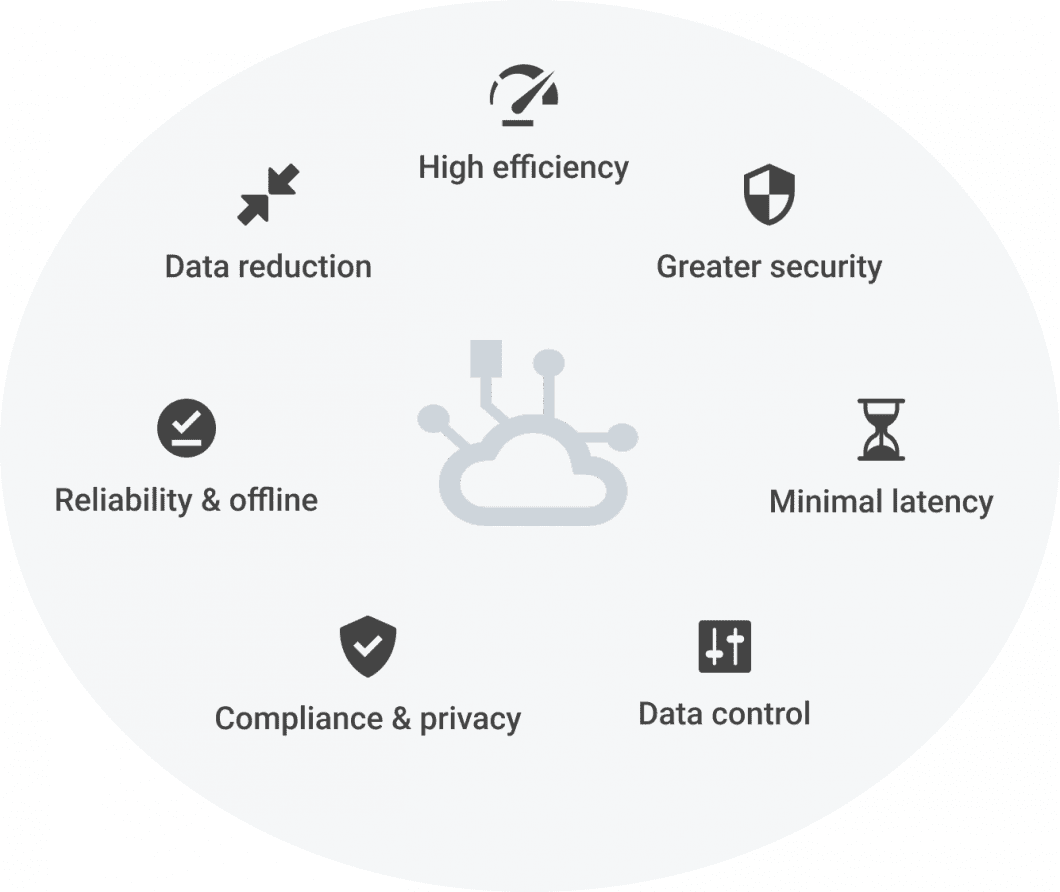
The computing device that executes object detection is usually some edge device with a CPU or GPU processor, as well as neural processing units (NPU) or vision accelerators. Such NPU devices are increasingly popular AI hardware for computer vision inferencing, for example:
- Neural Compute Stick or NCS (Intel)
- Jetson AI edge devices (Nvidia)
- Apple Neural Engine (Apple)
- Coral Edge TPU (Google)
- Neural processing engine (Qualcomm)
More recently, the design of efficient object detection architectures has focused on models that can be used on a CPU for scalable edge applications. Such models are mainly based on MobileNet, ShuffleNet, or GhostNet. Other mainstream object detectors have been optimized for GPU computing; they commonly use ResNet, DarkNet, or DLA architectures.

What is YOLOv7?
YOLOv7 is one of the fastest and most accurate real-time object detection models for computer vision tasks. The official YOLOv7 paper named “YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors” was released in July 2022 by Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao.
The YOLOv7 research paper has become immensely popular in a matter of days. The source code was released as open source under the GPL-3.0 license, a free copyleft license, and can be found in the official YOLOv7 GitHub repository that was awarded over 4.3k stars in the first month after release. There is also a complete appendix of the YOLOv7 paper.

The Differences Between the Basic YOLOv7 Versions
The different basic YOLOv7 models include YOLOv7, YOLOv7-tiny, and YOLOv7-W6:
- YOLOv7 is the basic model that is optimized for ordinary GPU computing.
- YOLOv7-tiny is a basic model optimized for edge GPUs. The suffix “tiny” of computer vision models means that they are optimized for Edge AI and deep learning workloads, and are more lightweight to run ML on mobile computing devices or distributed edge servers and devices. This model is important for distributed real-world computer vision applications. Compared to the other versions, the edge-optimized YOLOv7-tiny uses leaky ReLU as the activation function, while other models use SiLU as the activation function.
- YOLOv7-W6 is a basic model optimized for cloud GPU computing. Such Cloud Graphics Units (GPUs) are computer instances for running applications to handle massive AI and deep learning workloads in the cloud without requiring GPUs to be deployed on the local user device.
Other variations include YOLOv7-X, YOLOv7-E6, and YOLOv7-D6, which were obtained by applying the proposed compound scaling method (see YOLOv7 architecture further below) to scale up the depth and width of the entire model.

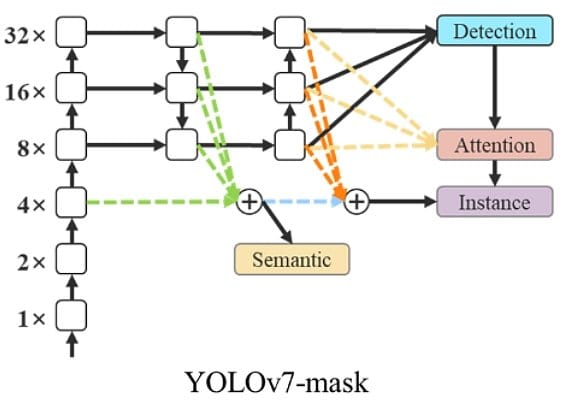
YOLOv7-mask
The integration of YOLOv7 with BlendMask is used to perform instance segmentation. Therefore, the YOLOv7 object detection model was fine-tuned on the MS COCO instance segmentation dataset and trained for 30 epochs. It achieves state-of-the-art real-time instance segmentation results.
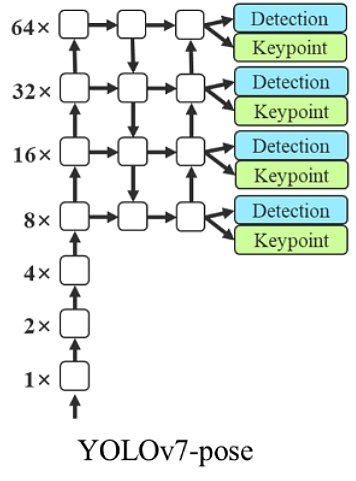
YOLOv7-pose
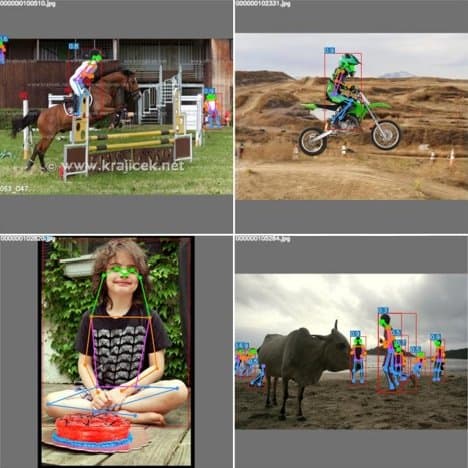
The integration of YOLOv7 with YOLO-Pose allows keypoint detection for Pose Estimation. The authors fine-tuned a YOLOv7-W6 people detection model on the MS COCO keypoint detection dataset and achieved state-of-the-art real-time pose estimation performance.
YOLOv7 Updates
YOLOv7 provides a greatly improved real-time object detection accuracy without increasing the inference costs. As previously shown in the benchmarks, when compared to other known object detectors, YOLOv7 can effectively reduce about 40% of parameters and 50% of computation of state-of-the-art real-time object detections, and achieve faster inference speed and higher detection accuracy.
In general, YOLOv7 provides a fast and strong network architecture that provides a more effective feature integration method, more accurate object detection performance, a more robust loss function, and an increased label assignment and model training process efficiency.
As a result, YOLOv7 requires several times cheaper computing hardware than other deep learning models. It can be trained much faster on small datasets without any pre-trained weights.
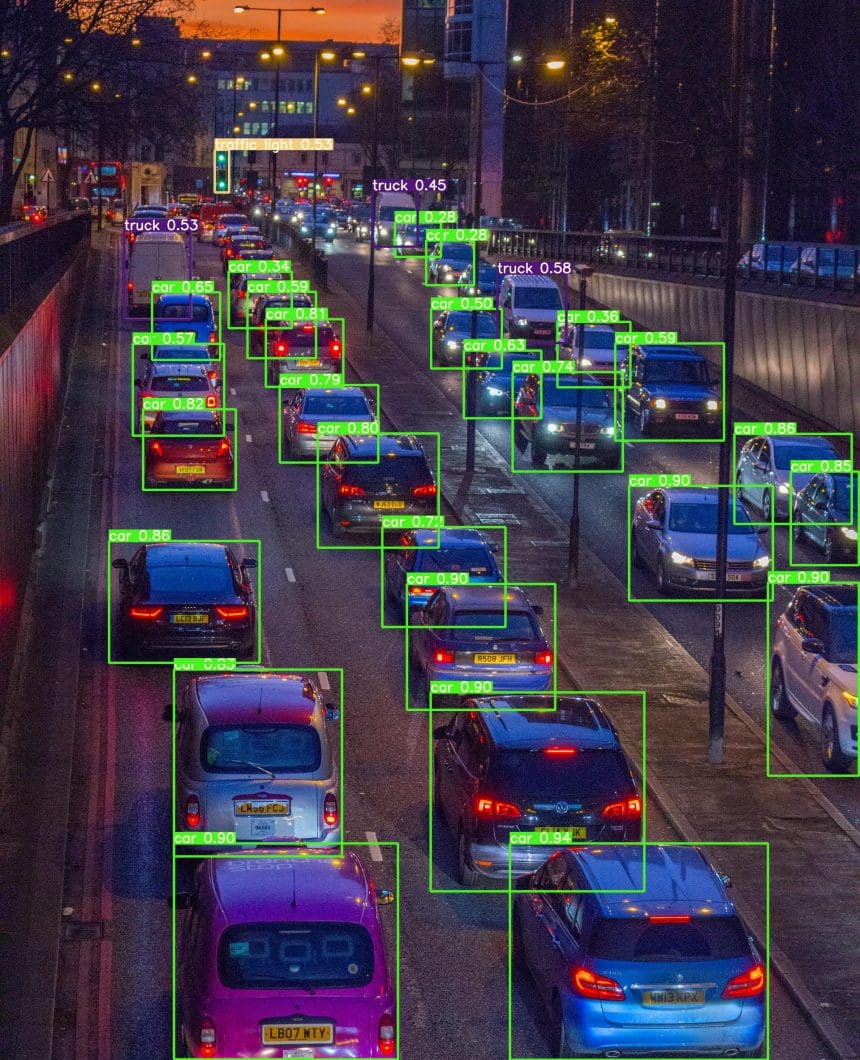
The authors train YOLOv7 using the MS COCO dataset without using any other image datasets or pre-trained model weights. Similar to Scaled YOLOv4, YOLOv7 backbones do not use Image Net pre-trained backbones (such as YOLOv3).
The YOLOv7 paper introduced the following major changes. Later in this article, we will describe those architectural changes and how YOLOv7 works.
- YOLOv7 Architecture
- Extended Efficient Layer Aggregation Network (E-ELAN)
- Model Scaling for Concatenation-based Models
- Trainable Bag of Freebies
- Planned re-parameterized convolution
- Coarse for auxiliary and fine for lead loss
What are Freebies in YOLOv7?
Bag-of-freebies features (more optimal network structure, loss function, etc.) increase accuracy without decreasing detection speed. That’s why YOLOv7 increases both speed and accuracy compared to previous YOLO versions.
The term was introduced in the YOLOv4 paper. Usually, a conventional object detector is trained offline. Consequently, researchers always like to take this advantage and develop better training methods that can make the object detector receive better accuracy without increasing the inference cost (read about computer vision costs). The authors call these methods that only change the training strategy or only increase the training cost a “bag of freebies”.
Where can I Quickly Test YOLOv7?
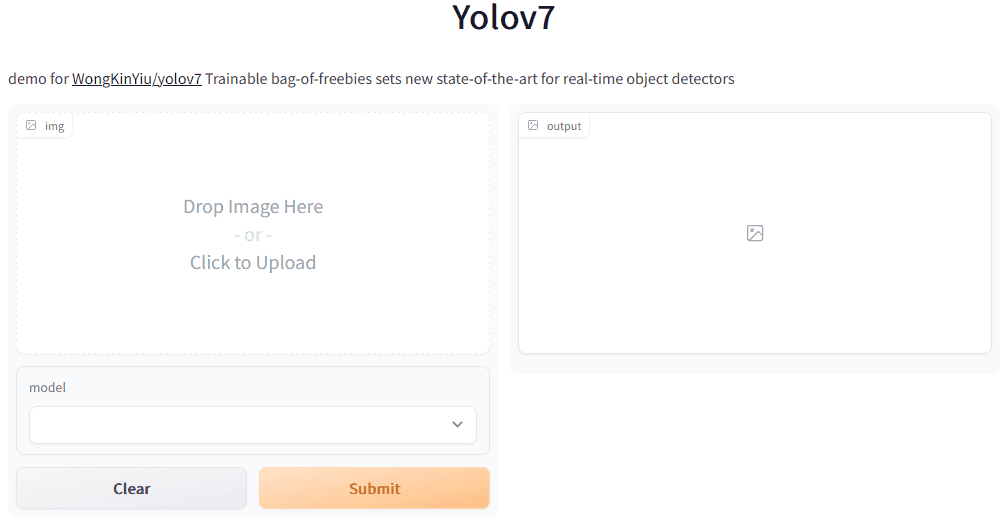
Here is a very fast way to test the new YOLOv7 deep learning model directly on Hugging Face: Find it here. This allows you to
- Upload your images from your local device,
- Select a YOLOv7 model, and
- Generate an output image with label boxes.
Since the DL model was trained on the COCO dataset, it will perform image recognition to detect the default COCO classes (find them in our guide about MS COCO).
YOLOv7 Performance and Comparisons
The YOLOv7 performance was evaluated based on previous YOLO versions (YOLOv4 and YOLOv5) and YOLOR as baselines. The models were trained with the same settings. The new YOLOv7 shows the best speed-to-accuracy balance compared to state-of-the-art object detectors.
In general, YOLOv7 surpasses all previous object detectors in terms of both speed and accuracy, ranging from 5 FPS to as much as 160 FPS. The YOLO v7 algorithm achieves the highest accuracy among all other real-time object detection models – while achieving 30 FPS or higher using a GPU V100.
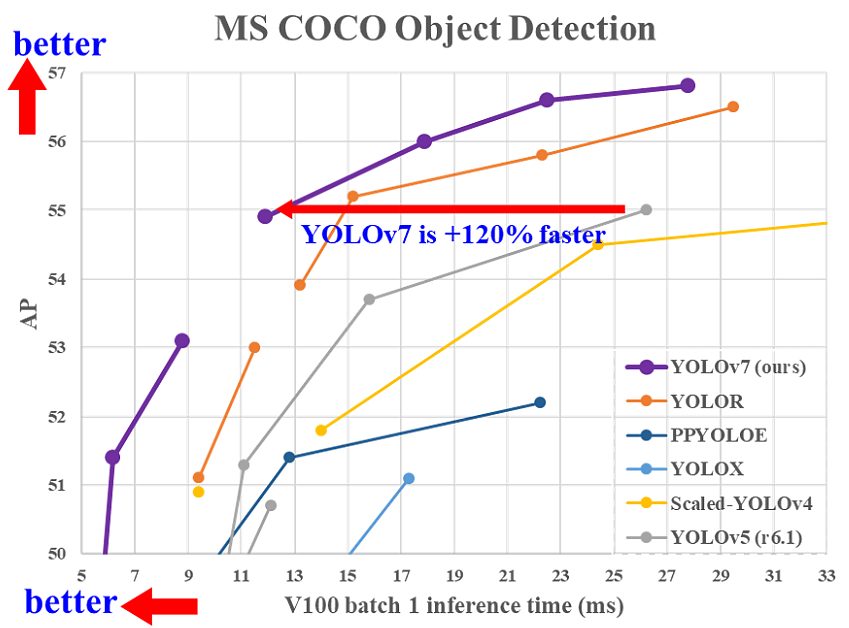
Compared to the best-performing Cascade-Mask R-CNN models, YOLOv7 achieves 2% higher accuracy at a dramatically increased inference speed (509% faster). This is impressive because such R-CNN versions use multi-step architectures that previously achieved significantly higher detection accuracies than single-stage detector architectures.
YOLOv7 outperforms YOLOR, YOLOX, Scaled-YOLOv4, YOLOv5, DETR, ViT Adapter-B, and many more object detection algorithms in speed and accuracy.
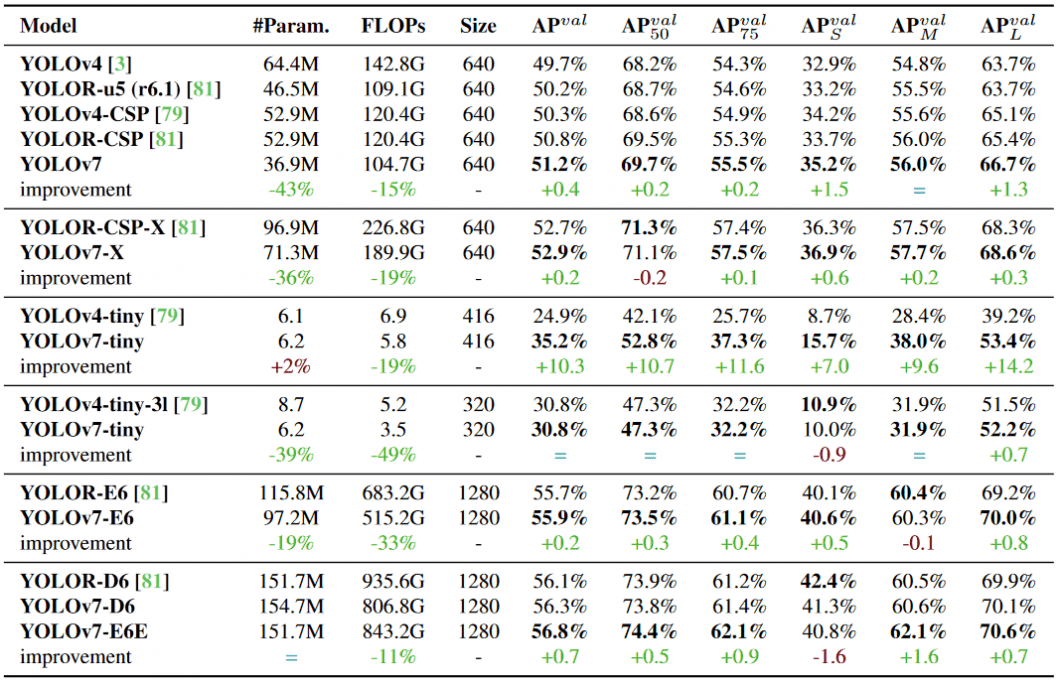
YOLOv7 vs YOLOv4
In comparison with YOLOv4, YOLOv7 reduces the number of parameters by 75%, requires 36% less computation, and achieves 1.5% higher AP (average precision).
Compared to the edge-optimized version YOLOv4-tiny, YOLOv7-tiny reduces the number of parameters by 39%, while also reducing computation by 49%, while achieving the same AP.
YOLOv7 vs YOLOR
Compared to YOLOR, Yolov7 reduces the number of parameters by 43%, requires 15% less computation, and achieves 0.4% higher AP.
When comparing YOLOv7 vs. YOLOR using the input resolution 1280, YOLOv7 achieves an 8 FPS faster inference speed with an increased detection rate (+1% AP).
When comparing YOLOv7 with YOLOR, the YOLOv7-D6 achieves a comparable inference speed, but a slightly higher detection performance (+0.8% AP).
YOLOv7 vs YOLOv5
Compared to YOLOv5-N, YOLOv7-tiny is 127 FPS faster and 10.7% more accurate on AP. The version YOLOv7-X achieves 114 FPS inference speed compared to the comparable YOLOv5-L with 99 FPS, while YOLOv7 achieves a better accuracy (higher AP by 3.9%).
Compared with models of a similar scale, the YOLOv7-X achieves a 21 FPS faster inference speed than YOLOv5-X. Also, YOLOv7 reduces the number of parameters by 22% and requires 8% less computation while increasing the average precision by 2.2%.
Comparing YOLOv7 vs. YOLOv5, the YOLOv7-E6 architecture requires 45% fewer parameters compared to YOLOv5-X6, and 63% less computation while achieving a 47% faster inference speed.
YOLOv7 vs PP-YOLOE
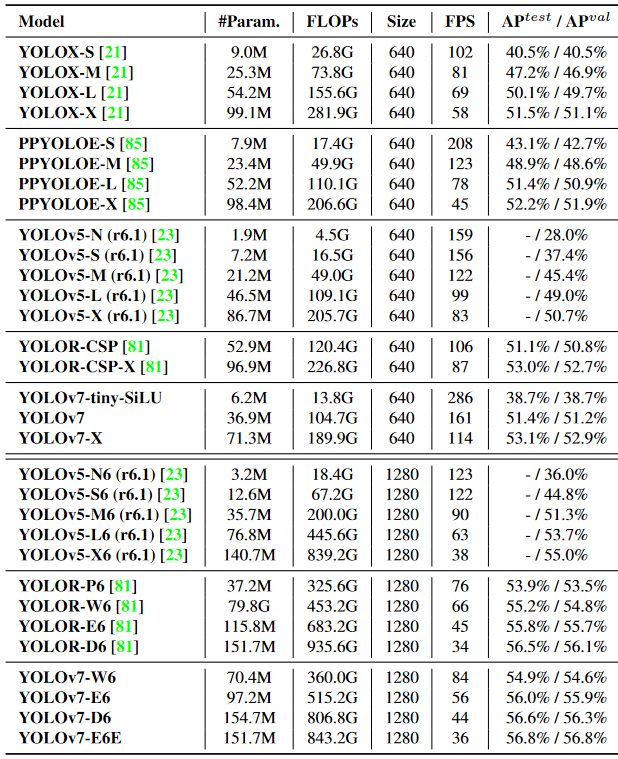
Compared to PP-YOLOE-L, YOLOv7 achieves a frame rate of 161 FPS compared to only 78 FPS with the same AP of 51.4%. Hence, YOLOv7 achieves an 83 FPS or 106% faster inference speed. In terms of parameter usage, YOLOv7 is 41% more efficient.
YOLOv7 vs YOLOv6
Compared to the previously most accurate YOLOv6 model (56.8% AP), the YOLOv7 real-time model achieves a 13.7% higher AP (43.1% AP) on the COCO dataset.
Any comparison of the lighter Edge model versions under identical conditions (V100 GPU, batch=32) on the COCO dataset, YOLOv7-tiny is over 25% faster while achieving a slightly higher AP (+0.2% AP) than YOLOv6-n.
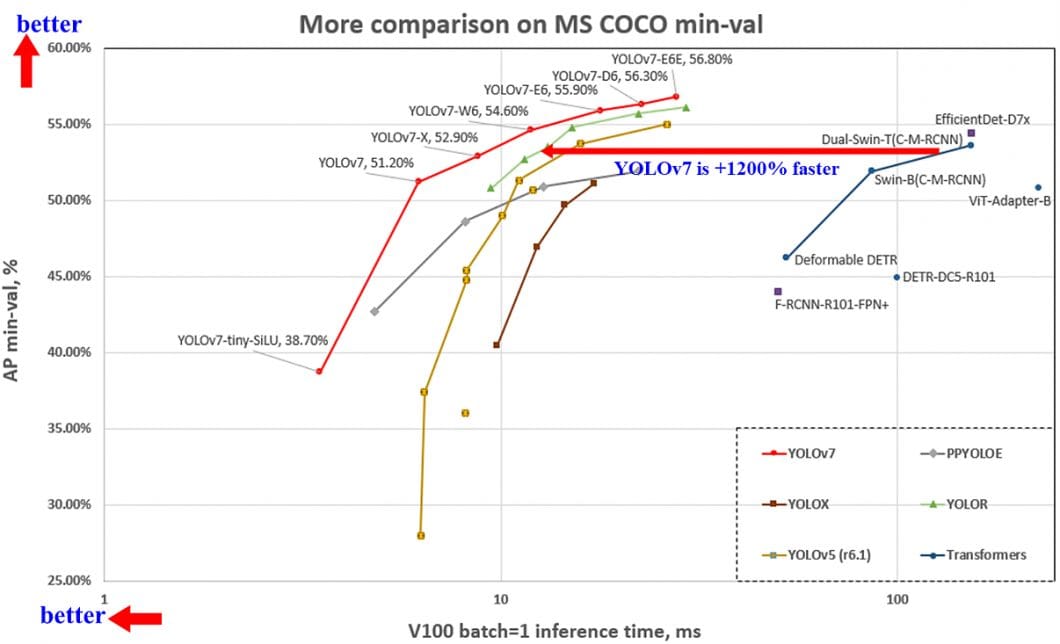
YOLOv7 Architecture
The YOLOv7 architecture is based on previous YOLO model architectures, namely YOLOv4, Scaled YOLOv4, and YOLO-R. In the following, we will provide a high-level overview of the most important aspects detailed in the YOLOv7 paper. To learn more about deep learning architectures, check out our article about the three popular types of Deep Neural Networks.
Extended Efficient Layer Aggregation Network (E-ELAN)
The computational block in the YOLOv7 backbone is named E-ELAN, standing for Extended Efficient Layer Aggregation Network. The E-ELAN architecture of YOLOv7 enables the model to learn better by using “expand, shuffle, merge cardinality” to achieve the ability to continuously improve the learning ability of the network without destroying the original gradient path.
YOLOv7 Compound Model Scaling
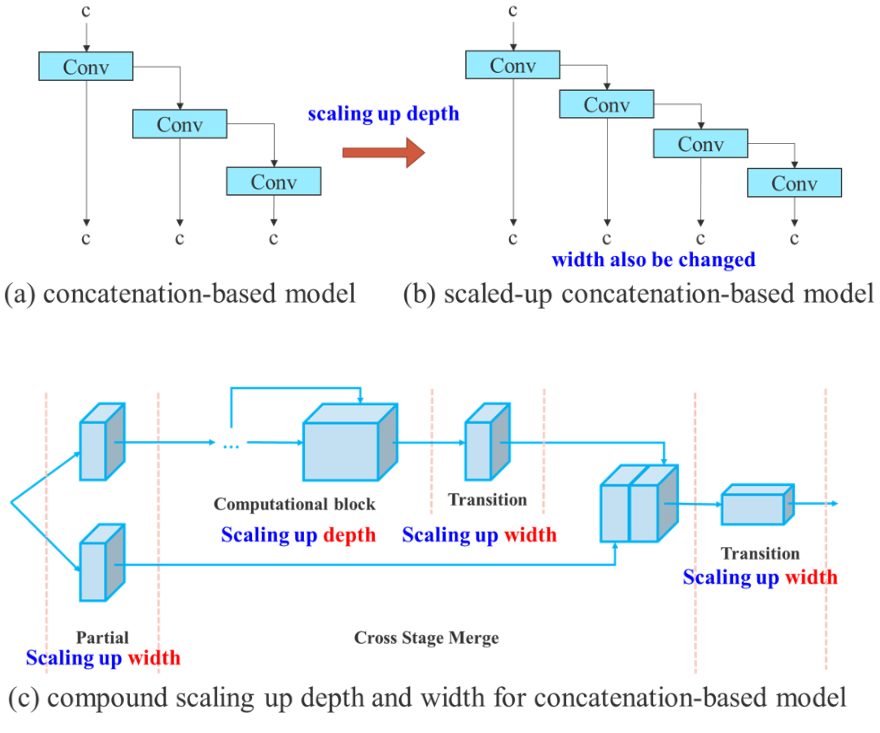
The main purpose of model scaling is to adjust key attributes of the model to generate models that meet the needs of different application requirements. For example, model scaling can optimize the model width (number of channels), depth (number of stages), and resolution (input image size).
In traditional approaches with concatenation-based architectures (for example, ResNet or PlainNet), different scaling factors cannot be analyzed independently and must be considered together. For instance, scaling up model depth will cause a ratio change between the input channel and output channel of a transition layer, which in turn may lead to a decrease in hardware usage of the model.
This is why YOLOv7 introduces compound model scaling for a concatenation-based model. The compound scaling method allows the maintenance of properties that the model had at the initial design and thus maintains the optimal structure.
And this is how compound model scaling works: For example, scaling the depth factor of a computational block also requires a change in the output channel of that block. Then, width factor scaling is performed with the same level of change on the transition layers.
Planned Re-parameterized Convolution
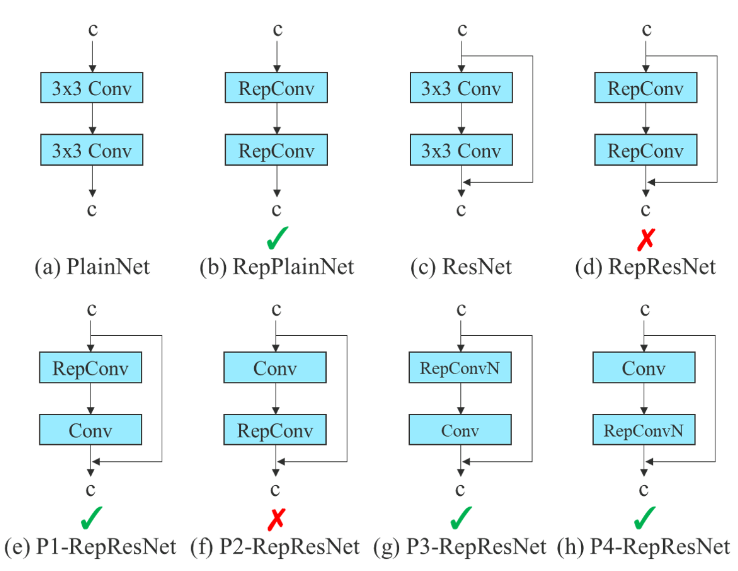
While RepConv has achieved great performance in VGG architectures, the direct application in ResNet or DenseNet leads to significant accuracy loss. In YOLOv7, the architecture of planned re-parameterized convolution uses RepConv without identity connection (RepConvN).
The idea is to avoid that there is an identity connection when a convolutional layer with residual or concatenation is replaced by a reparameterized convolution.
Coarse for Auxiliary and Fine for Lead Loss
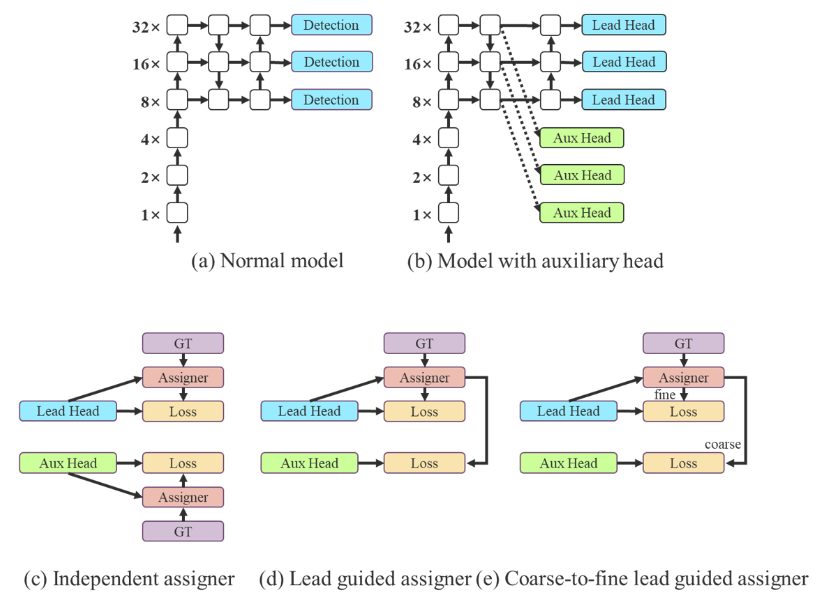
A YOLO architecture contains a backbone, a neck, and a head. The head contains the predicted model outputs. Inspired by Deep Supervision, a technique often used in training deep neural networks, YOLOv7 is not limited to one single head. The head responsible for the final output is called the lead head, which assists in training in the middle layers, named the auxiliary head.
In addition to enhancing the deep network training, a Label Assigner mechanism was introduced that considers network prediction results together with the ground truth and then assigns soft labels. Compared to traditional label assignment that directly refers to the ground truth to generate hard labels based on given rules, reliable soft labels use calculation and optimization methods that also consider the quality and distribution of prediction output, together with the ground truth.
Applications of YOLOv7
In the following, we will list real-world applications of YOLOv7 across different industries. It is important to understand that the object detector is only one part of an entire vision pipeline that often includes a sequence of steps – from camera integration and image acquisition to processing, output formatting, and system integration.
Security and Surveillance
Object detection is used in security and surveillance to identify and track objects in a given area. This can be used for security purposes, such as identifying potential threats, or for tracking the movements of people or objects in a pre-defined space (perimeter monitoring). Object detection is also an integral part of many facial recognition systems.
If you are looking for an open-source deep-learning library for face recognition, check out DeepFace.

Smart City and Traffic Management
YOLOv7 enables object detection as used in traffic management systems to detect vehicles and pedestrians at intersections. Hence, object detection has many use cases in smart cities, to analyze large crowds of people and inspect infrastructure.

AI Retail Analytics
Applications of computer vision in retail are of great importance for retailers with physical stores to digitize their operations. Visual AI enables data-driven insights that are otherwise only available in e-commerce (customer behavior, visitor path, customer experience, etc.).
Object detection is used to detect and track customer and employee movement patterns and footfall, improve the accuracy of inventory tracking, increase security, and much more.
Manufacturing and Energy
Object detection technology is a highly disruptive emerging technology in industrial manufacturing. YOLOv7 algorithms can be used to recognize and track objects as they move through a production line, allowing for more efficient and accurate manufacturing.
Additionally, object detection is used for quality control and defect detection in products or components as they are being manufactured. Traditional machine vision is increasingly replaced with modern deep learning methods. AI vision applications that help avoid interruptions or delays are often of immense business value. Explore our article about AI vision in oil and gas.

Autonomous Vehicles
Object detection is a key technology for self-driving cars to detect other vehicles, pedestrians, and obstacles automatically. AI vision is also used in Aviation, for autonomous drones, asset management, or even missile technologies.

Visual AI in Healthcare
One of the most important applications for object detection is in the field of healthcare. In particular, hospitals and clinics use it to detect and track medical equipment, supplies, and patients. This helps to keep track of everything that is going on in the hospital (patient movement), allows for more efficient inventory management, and improves patient safety. Also, physicians use object detection algorithms to support the diagnosis of conditions with medical imaging, such as X-rays and MRI scans.
Construction With Computer Vision
Computer vision tasks can be applied in the construction industry to enhance safety, efficiency, and quality control. One of the most popular applications we’ve seen is in progress monitoring and site management. This is where edge devices capture high-resolution images and videos of construction sites. This visual data is used to track progress, identify potential delays, and ensure compliance with project timelines.
Additionally, computer vision is important for quality inspections, where AI systems automatically detect defects, errors, and safety hazards in construction materials and structures.
Getting Started with YOLOv7
At viso.ai, we power the enterprise computer vision platform Viso Suite. The end-to-end solution allows enterprises to build, deploy, and scale real-time computer vision applications at the Edge. Viso Suite fully integrates the new YOLOv7 model and allows for the training of YOLOv7 models with pre-built notebooks, management of model versions, and use in powerful vision pipelines.
Read more about related topics: