The latest installation in the YOLO series, YOLOv9, was released on February 21st, 2024. Since its inception in 2015, the YOLO (You Only Look Once) object-detection algorithm has been closely followed by tech enthusiasts, data scientists, ML engineers, and more, gaining a massive following due to its open-source nature and community contributions. With every new release, the YOLO architecture becomes easier to use and much faster, lowering the barriers to use for people around the world.
YOLOv9: Advancements in Real-time Object Detection
YOLOv9: Advancements in Real-time Object Detection
YOLOv9 entered the YOLO playing field providing a higher mAP, strong performance, and notable advancements in real-time object detection.

Viso Suite
Go beyond point solutions. Discover how Viso Suite delivers full-lifecycle computer vision for enterprise teams
Get a Demo
Viso Suite isn’t a tool, it’s a strategy. See how it transforms AI vision adoption at the enterprise level.
Get a demoYOLO was introduced as a research paper by J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, signifying a step forward in the real-time object detection space, outperforming its predecessor – the Region-based Convolutional Neural Network (R-CNN). It is a single-pass algorithm having only one neural network to predict bounding boxes and class probabilities using a full image as input.

What is YOLOv9?
YOLOv9 is the latest version of YOLO, released in February 2024, by Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao. It is an improved real-time object detection model that aims to surpass all convolution-based and transformer-based methods.
YOLOv9 is released in four models, ordered by parameter count: v9-S, v9-M, v9-C, and v9-E. To improve accuracy, it introduces programmable gradient information (PGI) and the Generalized Efficient Layer Aggregation Network (GELAN). PGI prevents data loss and ensures accurate gradient updates, and GELAN optimizes lightweight models with gradient path planning.
At this time, the only computer vision task supported by YOLOv9 is object detection.

YOLO Version History
Before diving into the specifics, let’s briefly recap on YOLO versions released before YOLOv9.
| Release | Authors | Tasks | Paper | |
|---|---|---|---|---|
| YOLO | 2015 | Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi | Object Detection, Basic Classification | You Only Look Once: Unified, Real-Time Object Detection |
| YOLOv2 | 2016 | Joseph Redmon, Ali Farhadi | Object Detection, Improved Classification | YOLO9000: Better, Faster, Stronger |
| YOLOv3 | 2018 | Joseph Redmon, Ali Farhadi | Object Detection, Multi-scale Detection | YOLOv3: An Incremental Improvement |
| YOLOv4 | 2020 | Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao | Object Detection, Basic Object Tracking | YOLOv4: Optimal Speed and Accuracy of Object Detection |
| YOLOv5 | 2020 | Ultralytics | Object Detection, Basic Instance Segmentation (via custom modifications) | no |
| YOLOv6 | 2022 | Chuyi Li, et al. | Object Detection, Instance Segmentation | YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications |
| YOLOv7 | 2022 | Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao | Object Detection, Object Tracking, Instance Segmentation | YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors |
| YOLOv8 | 2024 | Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao | Classification, Object Detection, Oriented Detection, Instance Segmentation, Keypoint Detection | YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information |
Research Contributions of YOLO v9
- Theoretical analysis of deep neural network architecture from the perspective of reversible function. The authors designed PGI and auxiliary reversible branches based on this analysis and achieved excellent results.
- The designed PGI solves the problem that deep supervision can only be used for extremely deep neural network architectures. Thus, it allows new lightweight architectures to be truly applied in daily life.
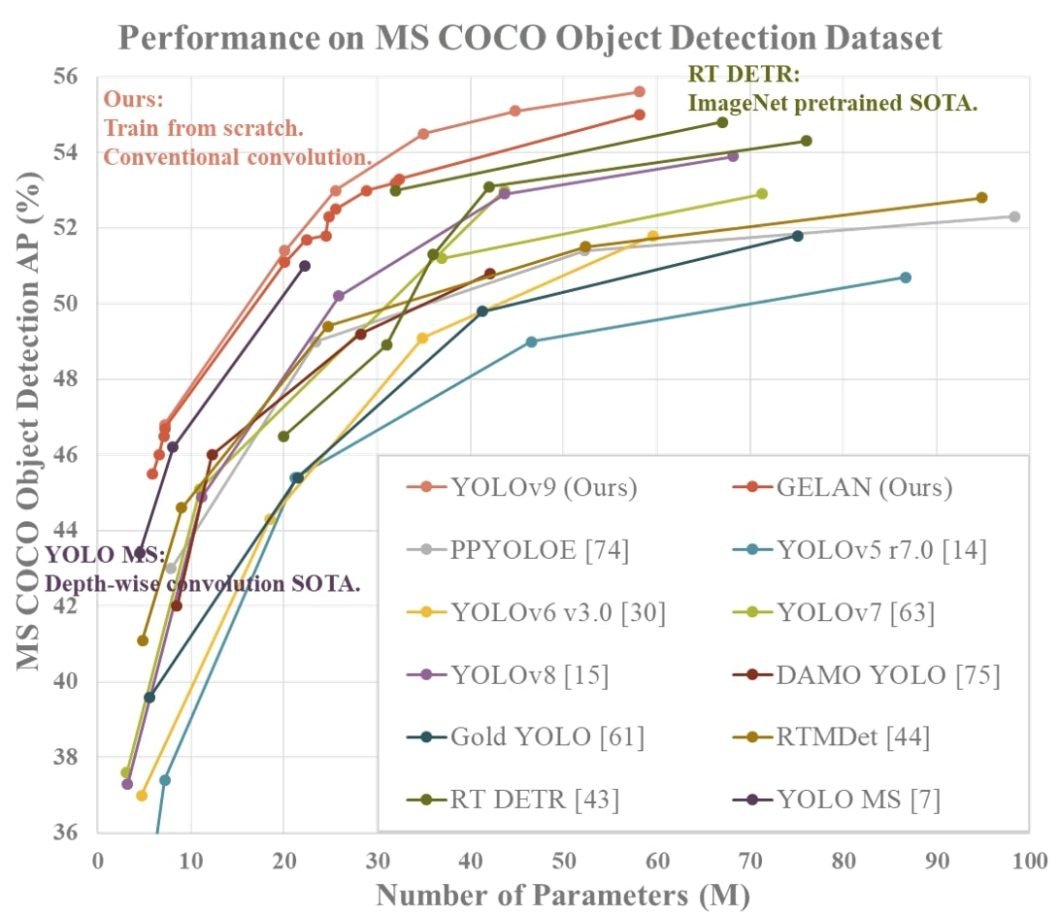
- The GELAN network only uses conventional convolution to achieve a higher parameter usage than the depth-wise convolution design. So it shows the great advantages of being light, fast, and accurate.
- Combining the proposed PGI and GELAN, the object detection performance of the YOLOv9 on the MS COCO dataset largely surpasses the existing real-time object detectors in all aspects.
YOLOv9 License
YOLOv9 was not released with an official license. In the following days, however, WongKinYiu updated the official license to GPL-3.0. YOLOv7 and YOLOv9 have been released under WongKinYiu’s repository.
Advantages of YOLOv9
YOLOv9 arises as a powerful model, offering innovative features that will play an important role in the further development of object detection, and maybe even image segmentation and classification down the road. It provides faster, clearer, and more flexible actions, and other advantages include:
- Handling the information bottleneck and adapting deep supervision to lightweight architectures of neural networks by introducing the Programmable Gradient Information (PGI).
- Creating the GELAN, a practical and effective neural network. GELAN has proven its strong and stable performance in object detection tasks at different convolution and depth settings. It could be widely accepted as a model suitable for various inference configurations.
- By combining PGI and GELAN, YOLOv9 has shown strong competitiveness. Its clever design allows the deep model to reduce the number of parameters by 49% and the number of calculations by 43% compared with YOLOv9. And it still has a 0.6% Average Precision improvement on the MS COCO dataset.
- The developed YOLOv9 model is superior to RT-DETR and YOLO-MS in terms of accuracy and efficiency. It sets new standards in lightweight model performance by applying conventional convolution for better parameter utilization.
| Model | #Param. | FLOPs | AP50:95val | APSval | APMval | APLval |
|---|---|---|---|---|---|---|
| YOLOv7 [63] | 36.9 | 104.7 | 51.2% | 31.8% | 55.5% | 65.0% |
| + AF [63] | 43.6 | 130.5 | 53.0% | 35.8% | 58.7% | 68.9% |
| + GELAN | 41.7 | 127.9 | 53.2% | 36.2% | 58.5% | 69.9% |
| + DHLC [34] | 58.1 | 192.5 | 55.0% | 38.0% | 60.6% | 70.9% |
| + PGI | 58.1 | 192.5 | 55.6% | 40.2% | 61.0% | 71.4% |
The above table demonstrates the average precision (AP) of various object detection models.
YOLOv9 Applications
YOLOv9 is a flexible computer vision model that you can use in different real-world applications. Here we suggest a few popular use cases.

- Logistics and distribution: Object detection can assist in estimating product inventory levels to ensure sufficient stock levels and provide information regarding consumer behavior.
- Autonomous vehicles: Autonomous vehicles can utilize YOLOv9 object detection to help navigate self-driving cars safely through the road.
- People counting: Retailers and shopping malls can train the model to detect real-time foot traffic in their shops, detect queue length, and more.
- Sports analytics: Analysts can use the model to track player movements in a sports field to gather relevant insights regarding team performance.

YOLOv9: Main Takeaways
The YOLO models are the standard in the object detection space with their great performance and wide applicability. Here are our first conclusions about YOLOv9:
- Ease-of-use: YOLOv9 is already in GitHub, so the users can implement YOLOv9 quickly through the CLI and Python IDE.
- YOLOv9 tasks: YOLOv9 is efficient for real-time object detection with improved accuracy and speed.
- YOLOv9 improvements: YOLOv9’s main improvements include a decoupled head with anchor-free detection and mosaic data augmentation that turns off in the last ten training epochs.